
Building Machine Learning at LinkedIn Scale
Building Machine Learning at LinkedIn Scale


Building machine learning at scale is a road full of challenges and there are not many well-documented case studies that can be used as a reference. My team at Invector Labs, recently published a slide deck that summarizes some of the lessons we have learned building machine learning solutions at scale but we are also always trying to study how other companies in the space are solving these issues.
LinkedIn is one of the companies that have been applying machine learning to large scale scenarios for years but little was known about the specific methods and techniques used at the software giant. Recently, the LinkedIn engineering team has published a series of blog posts that provide some very interesting insights about their machine learning infrastructure and practices. While many of the scenarios are very specific to LinkedIn, the techniques and best practices are applicable to many large scale machine learning solutions.
Machine Learning with Humans in the Loop
One of the most interesting aspects of LinkedIn’s machine learning architecture is how they leverage humans as part of the machine learning workflows. Let’s take, for instance, a scenario that discovers relationships between different titles such as “sr. software engineer” or “lead developer” to improve the search experience. LinkedIn uses human taxonomists to tag relationships between titles so that they can be used in machine learning models such as Long-Short-Term-Memory networks which help to discover additional relationships between titles. That machine learning architecture is the foundation of
Machine Learning Infrastructure at Scale
The core of LinkedIn’s machine learning infrastructure is a proprietary system called Pro-ML. Conceptually, Pro-ML controls the entire lifecycles of machine learning models from training to monitoring. In order to scale Pro-ML, LinkedIn has built an architecture that combines some of its open source technologies such as Kafka or Samza with infrastructure building blocks like Spark or Hadoop YARN.


While most of the technologies used as part of LinkedIn’s machine learning stack are well-known, there are a couple of new contributions that deserve further exploration:
· Ambry: LinkedIn’s Ambry is a distributed immutable blob storage system that is highly available, very easy to scale, optimized to serve immutable objects of few KBs to multiple GBs in size with high throughput and low latency and enables end to end streaming from the clients to the storage tiers and vice versa. The system has been built to work under active-active setup across multiple datacenters and provides very cheap storage.
· TonY: TensorFlow on YARN (TonY) is a framework to natively run TensorFlow on Apache Hadoop. TonY enables running either single node or distributed TensorFlow training as a Hadoop application.
· PhotonML: Photon ML is a machine learning library based on Apache Spark. Currently, Photon ML supports training different types of Generalized Linear Models(GLMs) and Generalized Linear Mixed Models(GLMMs/GLMix model): logistic, linear, and Poisson.
TensorFlow on Hadoop
Last month, the LinkedIn engineering team open sourced the first release of its TensorFlow on YARN(TonY) framework. The goal of the release was to enable TensorFlow programs to run on distributed YARN clusters. While TensorFlow workflows are widely supported on infrastructures like Apache Spark, YARN has remained largely ignored by the machine learning community. TonY e first-class support for running TensorFlow jobs on Hadoop by handling tasks such as resource negotiation and container environment setup.

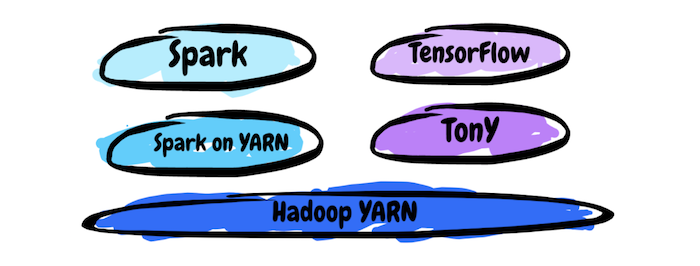
At its core, TonY takes a TensorFlow programs and splits it into multiple parallel tasks that can be executed on a YARN cluster. It does so while maintaining full support for TensorFlow’s computation graph which means that tools such as TensorBoard can be used on TonY without any modifications.


TonY is an interesting contribution to the TensorFlow ecosystem that can improve the experience of TensorFlow applications running at scale. Furthermore, TonY can benefit from the wide range of tools and libraries available in the YARN ecosystem to provide a highly-scalable runtime for training and running TensorFlow applications.
Testing
LinkedIn runs thousands of concurrent machine learning models which are constantly evolving and being versioned. In those scenarios, developing a robust testing methodology is essential to optimize the performance of machine learning models at runtime. In the case of LinkedIn, the engineering team has embedded A/B Testing as a first-class citizen of its Pro-ML architecture allowing machine learning engineers to deploy competing algorithms for specific scenarios and evaluate the one that yield the best results.


Internet giant like LinkedIn are at the forefront of the implementation of large-scale machine learning solutions and their insights about this subject are incredibly valuable to companies starting their machine learning journey. LinkedIn’s work clearly shows that developing machine learning at scale is a never-ending exercises that combines popular open source libraries and platforms with proprietary frameworks and methodologies.