
Dubbo 原始碼分析 - 叢集容錯之 Cluster
1.簡介
為了避免單點故障,現在的應用至少會部署在兩臺伺服器上。對於一些負載比較高的服務,會部署更多臺伺服器。這樣,同一環境下的服務提供者數量會大於1。對於服務消費者來說,同一環境下出現了多個服務提供者。這時會出現一個問題,服務消費者需要決定選擇哪個服務提供者進行呼叫。另外服務呼叫失敗時的處理措施也是需要考慮的,是重試呢,還是丟擲異常,亦或是隻列印異常等。為了處理這些問題,Dubbo 定義了叢集介面 Cluster 以及及 Cluster Invoker。叢集 Cluster 用途是將多個服務提供者合併為一個 Cluster Invoker,並將這個 Invoker 暴露給服務消費者。這樣一來,服務消費者只需通過這個 Invoker 進行遠端呼叫即可,至於具體呼叫哪個服務提供者,以及呼叫失敗後如何處理等問題,現在都交給叢集模組去處理。叢集模組是服務提供者和服務消費者的中間層,為服務消費者遮蔽了服務提供者的情況,這樣服務消費者就可以處理遠端呼叫相關事宜。比如發請求,接受服務提供者返回的資料等。這就是叢集的作用。
Dubbo 提供了多種叢集實現,包含但不限於 Failover Cluster、Failfast Cluster 和 Failsafe Cluster 等。每種叢集實現類的用途不同,接下來我會一一進行分析。
2. 叢集容錯
在對叢集相關程式碼進行分析之前,這裡有必要先來介紹一下叢集容錯的所有元件。包含 Cluster、Cluster Invoker、Directory、Router 和 LoadBalance 等,先來看圖。
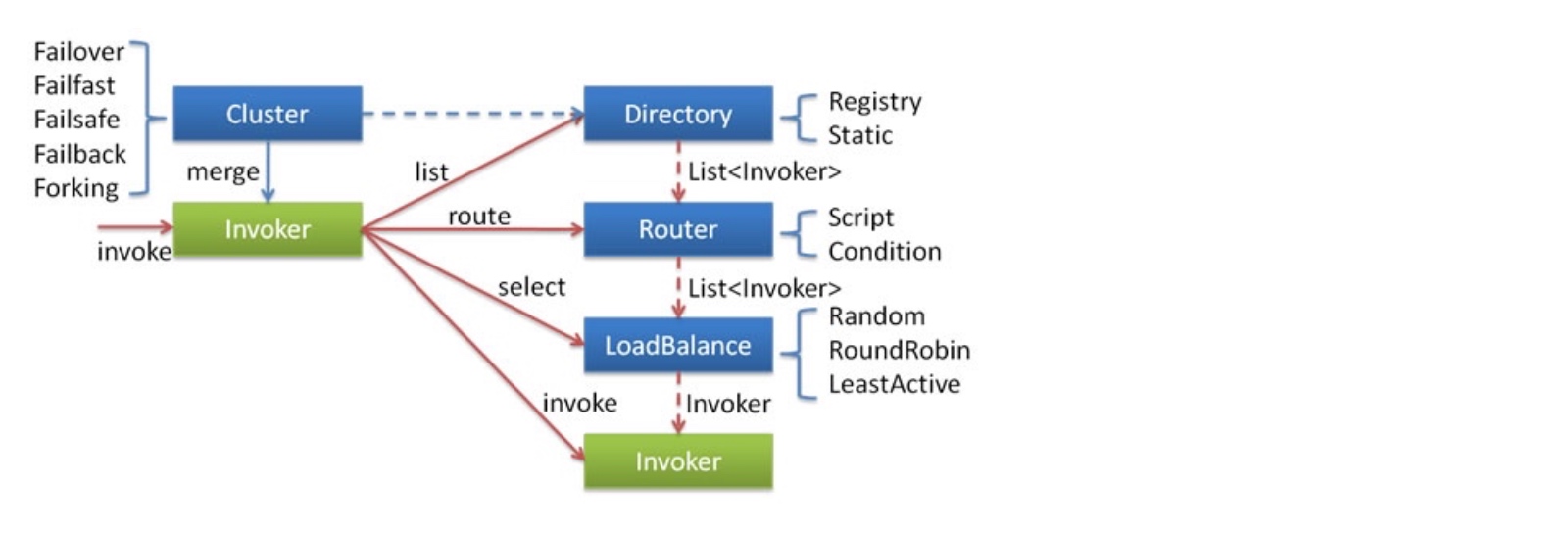
* 圖片來源:Dubbo 官方文件
這張圖來自 Dubbo 官方文件,接下來我會按照這張圖介紹叢集工作過程。叢集工作過程可分為兩個階段,第一個階段是在服務消費者初始化期間,叢集 Cluster 實現類為服務消費者建立 Cluster Invoker 例項,即上圖中的 merge 操作。第二個階段是在服務消費者進行遠端呼叫時。以 FailoverClusterInvoker 為例,該型別 Cluster Invoker 首先會呼叫 Directory 的 list 方法列舉 Invoker 列表(可將 Invoker 簡單理解為服務提供者)。Directory 的用途是儲存 Invoker,可簡單類比為 List<Invoker>。其實現類 RegistryDirectory 是一個動態服務目錄,可感知註冊中心配置的變化,它所持有的 Inovker 列表會隨著註冊中心內容的變化而變化。每次變化後,RegistryDirectory 會動態增刪 Inovker,並呼叫 Router 的 route 方法進行路由,過濾掉不符合路由規則的 Invoker。回到上圖,Cluster Invoker 實際上並不會直接呼叫 Router 進行路由。當 FailoverClusterInvoker 拿到 Directory 返回的 Invoker 列表後,它會通過 LoadBalance 從 Invoker 列表中選擇一個 Inovker。最後 FailoverClusterInvoker 會將引數傳給 LoadBalance 選擇出的 Invoker 例項的 invoker 方法,進行真正的 RPC 呼叫。
以上就是叢集工作的整個流程,這裡並沒介紹叢集是如何容錯的。Dubbo 主要提供了這樣幾種容錯方式:
- Failover Cluster - 失敗自動切換
- Failfast Cluster - 快速失敗
- Failsafe Cluster - 失敗安全
- Failback Cluster - 失敗自動恢復
- Forking Cluster - 並行呼叫多個服務提供者
這裡暫時只對這幾種容錯模式進行簡單的介紹,在接下來的章節中,我會重點分析這幾種容錯模式的具體實現。好了,關於叢集的工作流程和容錯模式先說到這,接下來進入原始碼分析階段。
3.原始碼分析
3.1 Cluster 實現類分析
我在上一章提到了叢集介面 Cluster 和 Cluster Invoker,這兩者是不同的。Cluster 是介面,而 Cluster Invoker 是一種 Invoker。服務提供者的選擇邏輯,以及遠端呼叫失敗後的的處理邏輯均是封裝在 Cluster Invoker 中。那麼 Cluster 介面和相關實現類有什麼用呢?用途比較簡單,用於生成 Cluster Invoker,僅此而已。下面我們來看一下原始碼。
|
|
如上,FailoverCluster 總共就包含這幾行程式碼,用於建立 FailoverClusterInvoker 物件,很簡單。下面再看一個。
|
|
如上,FailbackCluster 的邏輯也是很簡單,無需解釋了。所以接下來,我們把重點放在各種 Cluster Invoker 上
3.2 Cluster Invoker 分析
我們首先從各種 Cluster Invoker 的父類 AbstractClusterInvoker 原始碼開始說起。前面說過,叢集工作過程可分為兩個階段,第一個階段是在服務消費者初始化期間,這個在服務引用那篇文章中已經分析過了,這裡不再贅述。第二個階段是在服務消費者進行遠端呼叫時,此時 AbstractClusterInvoker 的 invoke 方法會被呼叫。列舉 Invoker,負載均衡等操作均會在此階段被執行。因此下面先來看一下 invoke 方法的邏輯。
|
|
AbstractClusterInvoker 的 invoke 方法主要用於列舉 Invoker,以及載入 LoadBalance。最後再呼叫模板方法 doInvoke 進行後續操作。下面我們來看一下 Invoker 列舉方法 list(Invocation) 的邏輯,如下:
|
|
如上,AbstractClusterInvoker 中的 list 方法做的事情很簡單,只是簡單的呼叫了 Directory 的 list 方法,沒有其他更多的邏輯了。Directory 的 list 方法我在前面的文章中已經分析過了,這裡就不贅述了。
接下來,我們把目光轉移到 AbstractClusterInvoker 的各種實現類上,來看一下這些實現類是如何實現 doInvoke 方法邏輯的。
3.2.1 FailoverClusterInvoker
FailoverClusterInvoker 在呼叫失敗時,會自動切換 Invoker 進行重試。在無明確配置下,Dubbo 會使用這個類作為預設 Cluster Invoker。下面來看一下該類的邏輯。
|
|
如上,FailoverClusterInvoker 的 doInvoke 方法首先是獲取重試次數,然後根據重試次數進行迴圈呼叫,失敗後進行重試。在 for 迴圈內,首先是通過負載均衡元件選擇一個 Invoker,然後再通過這個 Invoker 的 invoke 方法進行遠端呼叫。如果失敗了,記錄下異常,並進行重試。重試時會再次呼叫父類的 list 方法列舉 Invoker。整個流程大致如此,不是很難理解。下面我們看一下 select 方法的邏輯。
|
|
如上,select 方法的主要邏輯集中在了對粘滯連線特性的支援上。首先是獲取 sticky 配置,然後再檢測 invokers 列表中是否包含 stickyInvoker,如果不包含,則認為該 stickyInvoker 不可用,此時將其置空。這裡的 invokers 列表可以看做是存活著的服務提供者列表,如果這個列表不包含 stickyInvoker,那自然而然的認為 stickyInvoker 掛了,所以置空。如果 stickyInvoker 存在於 invokers 列表中,此時要進行下一項檢測 ---- 檢測 selected 中是否包含 stickyInvoker。如果包含的話,說明 stickyInvoker 在此之前沒有成功提供服務(但其仍然處於存活狀態)。此時我們認為這個服務不可靠,不應該在重試期間內再次被呼叫,因此這個時候不會返回該 stickyInvoker。如果 selected 不包含 stickyInvoker,此時還需要進行可用性檢測,比如檢測服務提供者網路連通性等。當可用性檢測通過,才可返回 stickyInvoker,否則呼叫 doSelect 方法選擇 Invoker。如果 sticky 為 true,此時會將 doSelect 方法選出的 Invoker 賦值給 stickyInvoker。
以上就是 select 方法的邏輯,這段邏輯看起來不是很複雜,但是資訊量比較大。不搞懂 invokers 和 selected 兩個入參的含義,以及粘滯連線特性,這段程式碼應該是沒法看懂的。大家在閱讀這段程式碼時,不要忽略了對背景知識的理解。其他的不多說了,繼續向下分析。
|
|
doSelect 主要做了兩件事,第一是通過負載均衡元件選擇 Invoker。第二是,如果選出來的 Invoker 不穩定,或不可用,此時需要呼叫 reselect 方法進行重選。若 reselect 選出來的 Invoker 為空,此時定位 invoker 在 invokers 列表中的位置 index,然後獲取 index + 1 處的 invoker,這也可以看做是重選邏輯的一部分。關於負載均衡的選擇邏輯,我將會在下篇文章進行詳細分析。下面我們來看一下 reselect 方法的邏輯。
|
|
reselect 方法總結下來其實只做了兩件事情,第一是查詢可用的 Invoker,並將其新增到 reselectInvokers 集合中。第二,如果 reselectInvokers 不為空,則通過負載均衡元件再次進行選擇。其中第一件事情又可進行細分,一開始,reselect 從 invokers 列表中查詢有效可用的 Invoker,若未能找到,此時再到 selected 列表中繼續查詢。關於 reselect 方法就先分析到這,繼續分析其他的 Cluster Invoker。
3.2.2 FailbackClusterInvoker
FailbackClusterInvoker 會在呼叫失敗後,返回一個空結果給服務提供者。並通過定時任務對失敗的呼叫進行重傳,適合執行訊息通知等操作。下面來看一下它的實現邏輯。
|
|
這個類主要由3個方法組成,首先是 doInvoker,該方法負責初次的遠端呼叫。若遠端呼叫失敗,則通過 addFailed 方法將呼叫資訊存入到 failed 中,等待定時重試。addFailed 在開始階段會根據 retryFuture 為空與否,來決定是否開啟定時任務。retryFailed 方法則是包含了失敗重試的邏輯,該方法會對 failed 進行遍歷,然後依次對 Invoker 進行呼叫。呼叫成功則將 Invoker 從 failed 中移除,呼叫失敗則忽略失敗原因。
以上就是 FailbackClusterInvoker 的執行邏輯,不是很複雜,繼續往下看。
3.2.3 FailfastClusterInvoker
FailfastClusterInvoker 只會進行一次呼叫,失敗後立即丟擲異常。適用於冪等操作,比如新增記錄。樓主日常開發中碰到過一次程式連續插入三條同樣的記錄問題,原因是新增記錄過程中包含了一些耗時操作,導致介面超時。而我當時使用的是 Dubbo 預設的 Cluster Invoker,即 FailoverClusterInvoker。其會在呼叫失敗後進行重試,所以導致插入服務提供者插入了3條同樣的資料。如果當時考慮使用 FailfastClusterInvoker,就不會出現這種問題了。當然此時介面仍然會超時,所以更合理的做法是使用 Dubbo 非同步特性。或者優化服務邏輯,避免超時。
其他的不多說了,下面直接看原始碼吧。
|
|
上面程式碼比較簡單了,首先是通過 select 方法選擇 Invoker,然後進行遠端呼叫。如果呼叫失敗,則立即丟擲異常。FailfastClusterInvoker 就先分析到這,下面分析 FailsafeClusterInvoker。
3.2.4 FailsafeClusterInvoker
FailsafeClusterInvoker 是一種失敗安全的 Cluster Invoker。所謂的失敗安全是指,當呼叫過程中出現異常時,FailsafeClusterInvoker 僅會列印異常,而不會丟擲異常。Dubbo 官方給出的應用場景是寫入審計日誌等操作,這個場景我在日常開發中沒遇到過,沒發言權,就不多說了。下面直接分析原始碼。
|
|
FailsafeClusterInvoker 的邏輯和 FailfastClusterInvoker 的邏輯一樣簡單,因此就不多說了。繼續下面分析。
3.2.5 ForkingClusterInvoker
ForkingClusterInvoker 會在執行時通過執行緒池建立多個執行緒,併發呼叫多個服務提供者。只要有一個服務提供者成功返回了結果,doInvoke 方法就會立即結束執行。ForkingClusterInvoker 的應用場景是在一些對實時性要求比較高讀操作(注意是讀操作,並行寫操作可能不安全)下使用,但這將會耗費更多的服務資源。下面來看該類的實現。
|
|
ForkingClusterInvoker 的 doInvoker 方法比較長,這裡我通過兩個分割線將整個方法劃分為三個邏輯塊。從方法開始,到分割線1之間的程式碼主要是用於選出 forks 個 Invoker,為接下來的併發呼叫提供輸入。分割線1和分割線2之間的邏輯主要是通過執行緒池併發呼叫多個 Invoker,並將結果儲存在阻塞佇列中。分割線2到方法結尾之間的邏輯主要用於從阻塞佇列中獲取返回結果,並對返回結果型別進行判斷。如果為異常型別,則直接丟擲,否則返回。
以上就是ForkingClusterInvoker 的 doInvoker 方法大致過程。我在分割線1和分割線2之間的程式碼上留了一個問題,問題是這樣的:為什麼要在 value >= selected.size() 的情況下,才將異常物件新增到阻塞佇列中?這裡來解答一下。原因是這樣的,在並行呼叫多個服務提供者的情況下,哪怕只有一個服務提供者成功返回結果,而其他全部失敗。此時 ForkingClusterInvoker 仍應該返回成功的結果,而非丟擲異常。在 value >= selected.size() 時將異常物件放入阻塞佇列中,可以保證異常物件不會出現在正常結果的前面,這樣可從阻塞佇列中優先取出正常的結果。
好了,關於 ForkingClusterInvoker 就先分析到這,接下來分析最後一個 Cluster Invoker。
3.2.6 BroadcastClusterInvoker
本章的最後,我們再來看一下 BroadcastClusterInvoker。BroadcastClusterInvoker 會逐個呼叫每個服務提供者,如果其中一臺報錯,在迴圈呼叫結束後,BroadcastClusterInvoker 會丟擲異常。看官方文件上的說明,該類通常用於通知所有提供者更新快取或日誌等本地資源資訊。這個使用場景筆者也沒遇到過,沒法詳細說明了,所以下面還是直接分析原始碼吧。
|
|
以上就是 BroadcastClusterInvoker 的程式碼,比較簡單,就不多說了。
4.總結
本篇文章較為詳細的分析了 Dubbo 叢集容錯方面的內容,並詳細分析了叢集容錯的幾種實現方式。叢集容錯對於 Dubbo 框架來說,是很重要的邏輯。叢集模組處於服務提供者和消費者之間,對於服務消費者來說,叢集可向其遮蔽服務提供者叢集的情況,使其能夠專心進行遠端呼叫。除此之外,通過叢集模組,我們還可以對服務之間的呼叫鏈路進行編排優化,治理服務。總的來說,對於 Dubbo 而言,叢集容錯相關邏輯是非常重要的。想要對 Dubbo 有比較深的理解,叢集容錯是繞不過去的。因此,對於這部分內容,大家要認真看一下。
好了,本篇文章就先到這,感謝大家的閱讀。
附錄:Dubbo 原始碼分析系列文章
| 時間 | 文章 |
|---|---|
| 2018-10-01 | Dubbo 原始碼分析 - SPI 機制 |
| 2018-10-13 | Dubbo 原始碼分析 - 自適應拓展原理 |
| 2018-10-31 | Dubbo 原始碼分析 - 服務匯出 |
| 2018-11-12 | Dubbo 原始碼分析 - 服務引用 |
| 2018-11-17 | Dubbo 原始碼分析 - 叢集容錯之 Directory |
| 2018-11-20 | Dubbo 原始碼分析 - 叢集容錯之 Router |
| 2018-11-24 | Dubbo 原始碼分析 - 叢集容錯之 Cluster |