
Should we take the redux path?
I am part of the ‘New Features’ research team at Hike. Our aim is to develop and test out ideas that we think will delight our users. This means we need to move fast to deliver new features and also make frequent changes to these features in our constant chase to create an aha! user-experience. We prefer building these experiments in React Native as it allows us to build rapidly and across different platforms with the same code
When we kickstart a new project, there are certain questions which come up in our architecture discussions:
- This is an experimental feature which might get discarded, so should we spend our time on setting up any architecture?
- This application is just an MVP for now, just 1 or 2 screens and we need to build fast, should we skip Redux setup for now?
- How do we explain extra code setup time to Product managers?
The answer to these questions lies in Redux — Redux architecture helps to separate the application state from React. It creates a global store that resides at the top level of your application and feeds the state to all other components.
Now, let us dive into our learnings of Redux architecture:
Separation of concern
“In computer science, separation of concerns (SoC) is a design principle for separating a computer program into distinct sections, such that each section addresses a separate concern. A concern is a set of information that affects the code of a computer program.”
Redux adds Separation of Concern to app and separates it into four components:
- View components
- Action creators
- Store
- Reducers
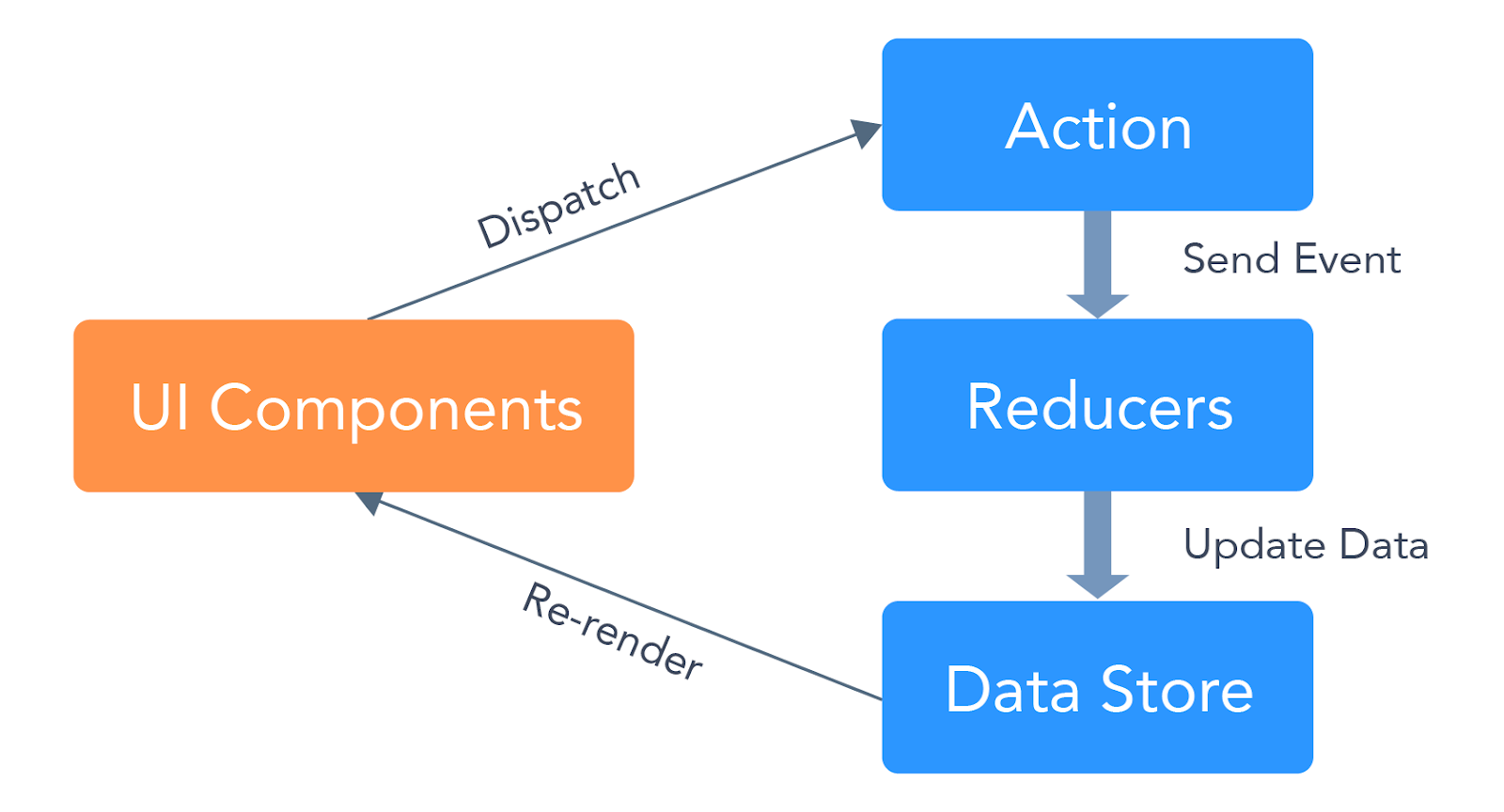
It gives responsibility to its components as follows:
A component/view is like a pure function (function that does not alter the data passed to it), it is responsible for rendering on screen based on data provided by store. It does not change data directly, however it calls the action creatorsin case of any event or interaction.
Action creators are responsible for dispatching action events.
Reducers receive these dispatched events and updates the state of data store.
Store is responsible for storing the data associated with the app.
Let me explain this with a simple example:
In the Hike app, we have a screen that shows friends list, with the total count on top.

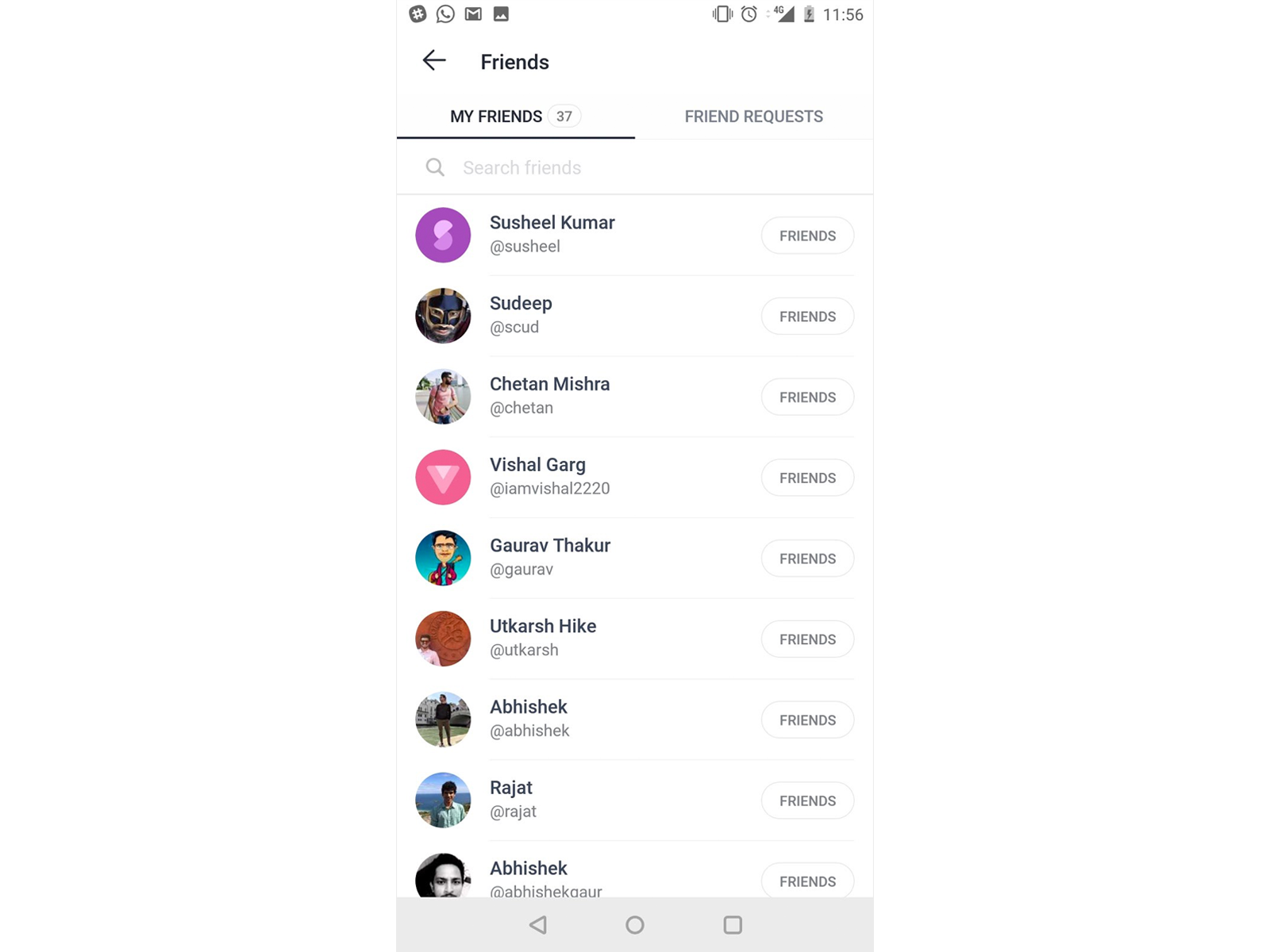
Here, we have 3 React components:
- FriendRow, the view containing a name and some other properties of each friend
- FriendsHeader, the view containing ‘My friends’ and total count
- ContainerView, view that merge both FriendsHeader and loop through friends data array to render each FriendRow
The basic approach to build it is to fetch friends data in the containerView and pass it as props to the child components: FriendRow and FriendsHeader.
Now, what if this friends data is also needed in some other component across the app.
Like we have another ‘Compose Chat’ screen which also shows friends list, what do we do now. We have two options:
- Fetch the friends data again in ComposeChat component. But, this will create data redundancy and syncing issues
- Another is, we can fetch ‘Friends data’ in the topmost component (Main app Container) and pass it to the ‘ComposeChat’ and ‘FriendList’. Also, we have to pass the functions needed to update the friends’ data to keep components in sync. This will make the topmost component bloated with a lot of methods and data which is not used by it directly.
Let’s see how we approach this problem using redux architecture:
- Data Store keeps the friends’ data fetched. Data can be fetched in any component if empty.
- An action creator to store and update the friends’ data.
3. Reducers listen to the action events and update the friends’ data.
4. FriendsContainer maps to friends data in store and re-renders on data change. It also fetches the data if it is not already present.
5. Similarly ‘Compose Chat’ can also use the friends’ data and any update will be reflected in both places.
Initial setup might take a day or two, but all incremental changes become easy and very fast. Any new component dependent on friends data can be added or removed without the need to worry about any data sync issues or rearranging component.
Each section is independently testable, Ensures high quality
Each view can be easily unit tested, as it becomes independent of data. A view function returns the same component for the same data state. It makes your app predictable and there are fewer chances of any rendering issues.
Each component can be deeply tested with different types of data possible. In-depth testing ensures a high-quality code.
Also, the reducer functions and actions can be tested independently.
Issues we faced with Redux
Excess Boilerplate codeInitial setup time is definitely more, with lot of strange terms & weird entities: thunk, reducers, actions, middlewares, mapStateToProps, mapDispatchToProps etc. Learning all this takes more time and needs practice. There are too many files, and one small view change might require changes in four different files.
Singleton Redux StoreIn Redux, the data store is singleton, however components can have multiple instances. Though most of the times this isn’t a problem, however, in certain cases it can create a few issues. As an example, imagine a component with two instances, when data in any of these instances is updated, the change gets reflected in the other instance as well. In many a cases, this may not be desirable, and one would need to maintain separate copies for each instance.
Conclusion
So, if we were to look at our key question again — is it worth spending that extra time setting up Redux architecture? Yes, as it helps save time and effort when the application scales. Frequent design changes can be easily made and tested, ensuring high quality. There is an excess of boilerplate code, but that makes your code modularised. So each module can be independently tested and bugs can be identified at the development stage.