
Perplexity Intuition (and Derivation)
Perplexity Intuition (and its derivation)
Never be perplexed again by perplexity.
You might have seen something like this in an NLP class:


Or


During the class, we don’t really spend time to derive the perplexity. Maybe perplexity is a basic concept that you probably already know? This post is for those who don’t.
In general, perplexity is a measurement of how well a probability model predicts a sample. In the context of Natural Language Processing, perplexity is one way to evaluate language models.
But why is perplexity in NLP defined the way it is?
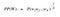
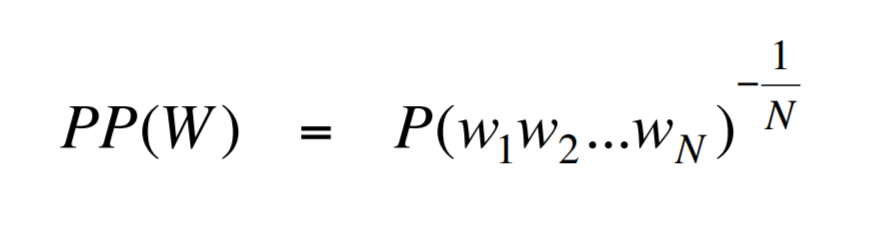
The perplexity of a discrete probability distribution is defined as:
where H(p) is the entropy of the distribution p(x) and x is a random variable over all possible events.
In the previous post, we derived H(p) from scratch and intuitively showed why entropy is the average number of bits that we need to encode the information. If you don’t understand H(p), please read this⇩before reading further.
Now we agree that H(p) =-Σ p(x) log p(x).
Then, perplexity is just an exponentiation of the entropy!
Yes. Entropy is the average number of bits to encode the information contained in a random variable, so the exponentiation of the entropy should be the total amount of all possible information, or more precisely, the weighted average number of choices a random variable has.
For example, if the average sentence in the test set could be coded in 100 bits, the model perplexity is 2¹⁰⁰ per sentence.