
A3C — What It Is & What I Built
The 3 A’s of A3C
Actor-Critic
The basic actor-critic model stems from Deep Convolution Q-Learning which is where the agent implements q-learning, but instead of taking in a matrix of states as input, it takes in images and feeds them into a deep convolutional neural network.

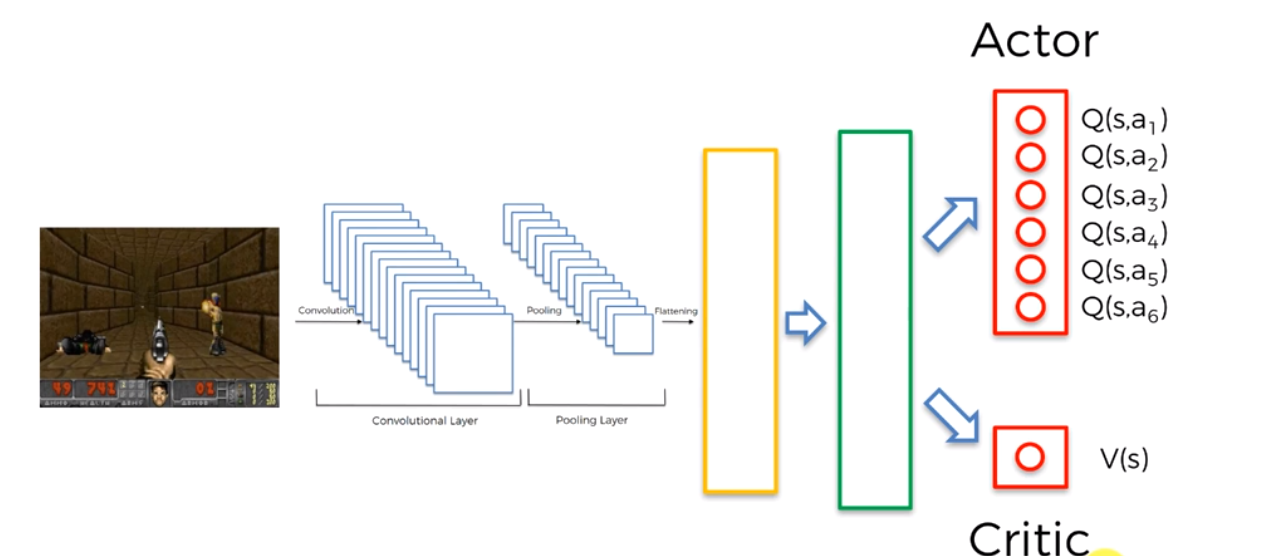
Don’t worry about the rectangles on the right side, they represent a deep neural network with all the nodes and connections. It’s just easier to explain and understand A3C this way.
In a regular Deep Convolution Q-Learning network, there would only be one output and that would be the q-values of the different actions. However in A3C, there are two outputs, one of the q-values for the different actions and the other to calculate the value of being in the state the agent is actually in.
Asynchronous
Think about the saying, “Two heads are better than one.” The whole idea behind that is two people working together are more likely to solve a problem quicker, faster, and overall better.

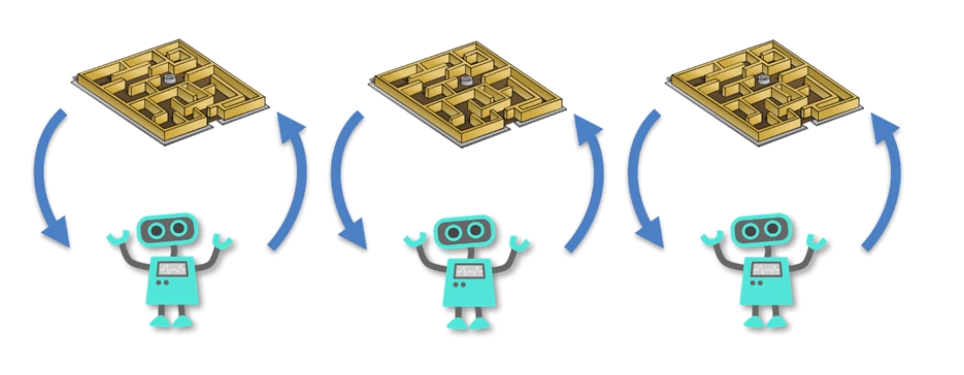
This word, “Asynchronous”, in A3C represents this exact idea with agents. Instead of there just being one agent trying to solve the problem, there are multiple agents working on the problem and sharing information with each other about what they’ve learned.
There’s also the added benefit that if one agent gets stuck performing a task sub optimally to get a reward over and over thinking that this is the best way, the other agents can share information and show this agent that there is a better way to solve the problem!

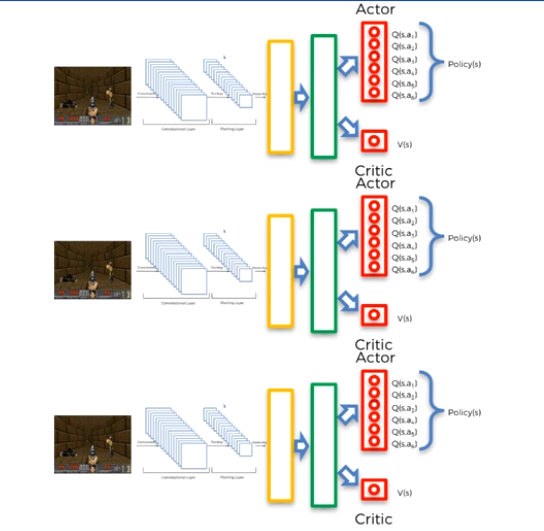
So now there are multiple agents training side by side to solve the problem they were given.
But what happened to the sharing experience part? Well they share experience by adding up of all of their individual critic values into a big shared one. By sharing this experience they can see what states have high rewards and what the other agents have explored in the environment.
This is like the barebones of A3C, but we’re going to go a step further into a version tweaked by the creator of PyTorch which is one of the best deep learning libraries out there. What he did was that instead of each agent having their own seperate network, there is only one neural network that all the agents share. This means that all the agents now share common weights and this leads to training being easier.
Advantage
Advantage = Q(s, a) — V(s)
This is the equation that this last A is based off of. What this is saying is that we want to figure out what is the difference between the q-value of an action we take and the value of the state we’re in.
How much better is the q-value than the known value?
The whole point is to always get better q-values to get more and more reward. When the advantage is high, the q-value is a lot better than the known value.
The neural network then wants to enforce this behaviour and update its weights so it keeps repeating these actions. If the advantage is low, then the neural network tries to prevent these actions from occurring again.
One More Step Needed — Memory!

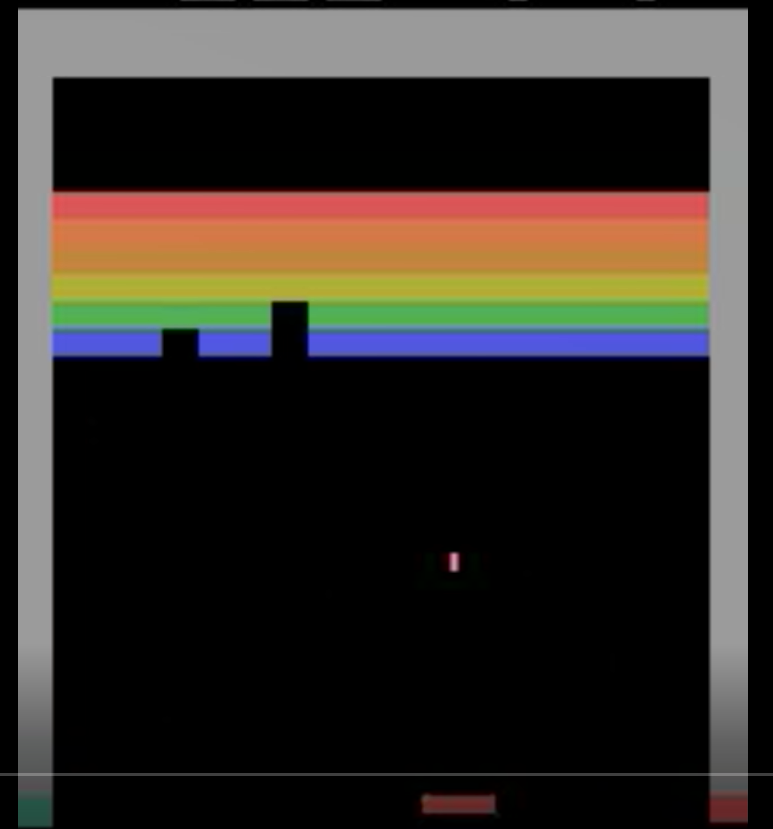
This is a screenshot I took directly from the training videos of my agent training. I want to ask you, can you tell which direction the ball is going?
Is it left, right, up, down? You literally cannot tell. There are ways that the regular A3C algorithm tackles this problem, but for my implementation, I used a Long Short Term Memory network (LSTM). This LSTM is what helps this neural network remember where the ball was in past frames so the agent can decide where to move the paddle so the ball can bounce off of it.
My Demo

This is the best result I got, training on my laptop with this algorithm! Even though it’s nothing crazy like Boston Dynamics training robots to do parkour or anything, it blows my mind everyday that this agent went from knowing absolutely nothing about the game to actually playing the game! Imagine about what we could do in the future with reinforcement learning algorithms!
Even now I’m most excited about reinforcement learning for drug design and nanotech design, what applications could rise in the future?
Here’s a bit of the code to show some of the more interesting parts of the algorithm are and how they’re implemented in code!

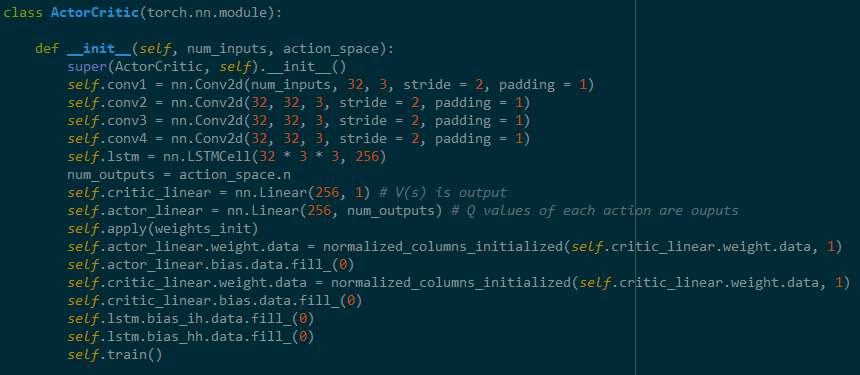
This is the initialization function of the Actor Critic model and this is where the convolution neural network, connections to the actor and critic models are made, as well as the LSTM cell!

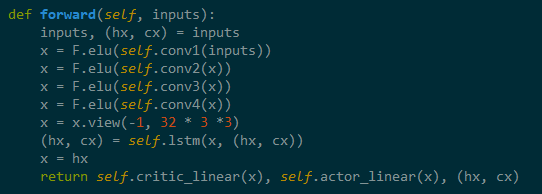
This function is also part of the ActorCritic class and this is where we forward propagate through the neural network and get the outputs of the Actor and the Critic!

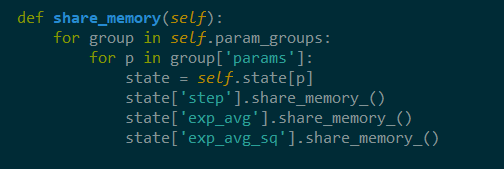
The share_memory function is where all the different agents share their memories with each other so that they can all learn from each other’s experiences!