
Self Attention需要掌握的基本原理
字面意思理解,self attention就是計算句子中每個單詞的重要程度。
1. Structure
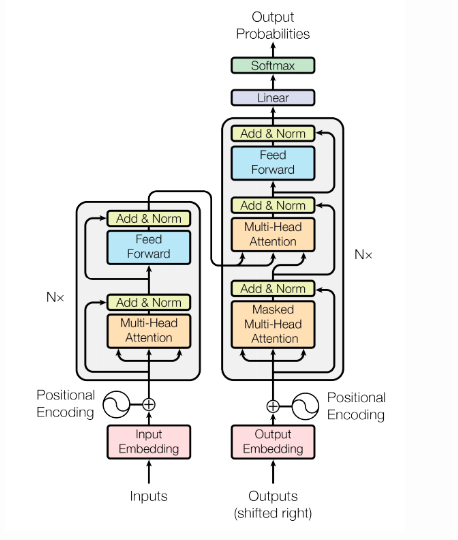
通過流程圖,我們可以看出,首先要對輸入資料做Embedding
1. 在編碼層,輸入的word-embedding就是key,value和query,然後做self-attention得到編碼層的輸出。這一步就模擬了圖1中的編碼層,輸出就可以看成圖1中的h。
2. 然後模擬圖1中的解碼層,解碼層的關鍵是如何得到s,即用來和編碼層做attention的query,我們發現,s與上個位置的真實label y,上個位置的s,和當前位置的attention輸出c有關,換句話說,位置i的s利用了所有它之前的真實label y資訊,和所有它之前位置的attention的輸出c資訊。label y資訊我們全都是已知的,而之前位置的c資訊雖然也可以利用,但是我們不能用,因為那樣就又不能並行了(因為當前位置的c資訊必須等它之前的c資訊都計算出來)。於是我們只能用真實label y來模擬解碼層的rnn。前面說過,當前位置s使用了它之前的所有真實label y資訊。於是我們可以做一個masked attention,即對真實label y像編碼層的x一樣做self-attention,但每個位置的y只與它之前的y有關(mask),這樣,self-attention之後每個位置的輸出綜合了當前位置和它之前位置的所有y資訊,即可做為s(query)。
3. 得到編碼層的key和value以及解碼層的query後,下面就是模仿vanilla attention,利用key和value以及query再做最後一個attention。得到每個位置的輸出。
總結起來就是,x做self-attention得到key和value,y做masked self-attention得到query,然後key,value,query做vanilla-attention得到最終輸出。
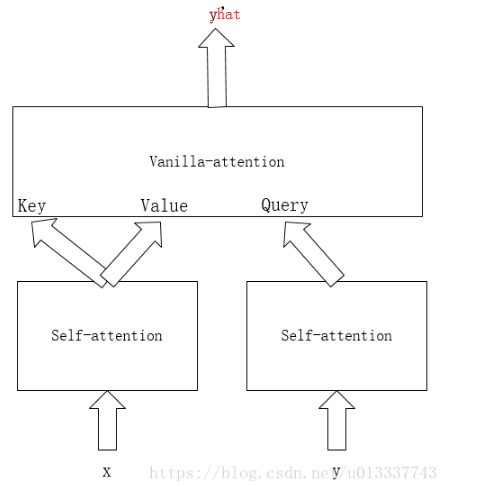
attention中計算Query和Key的相似度,相似度計算方法主要有4中:

2. position embedding
self-attention各個位置可以說是相互獨立的,輸出只是各個位置的資訊加權輸出,並沒有考慮各個位置的位置資訊。因此,Google提出一種pe演算法:
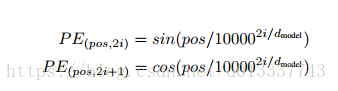
即在偶數位置,此word的pe是sin函式,在奇數位置,word的pe是cos函式。
論文說明了此pe和傳統的訓練得到的pe效果接近。並且因為 sin(α+β)=sinα cosβ+cosα sinβ 以及 cos(α+β)=cosα cosβ−sinα sinβ,位置 p+k 的向量可以用位置 p 的向量的線性變換表示,這也說明此pe不僅可以表示絕對位置,也能表示相對位置。
最後的embedding為word_embedding+position_embedding。
3. multi-head attention
首先embedding做h次linear projection,每個linear projection的引數不一樣,然後做h次attention,最後把h次attention的結果拼接做為最後的輸出。
多個attention便於模型學習不同子空間位置的特徵表示,然後最終組合起來這些特徵,而單頭attention直接把這些特徵平均,就減少了一些特徵的表示可能。
4. Scaled Dot-Product
論文計算query和key相似度使用了dot-product attention,即query和key進行點乘(內積)來計算相似度。
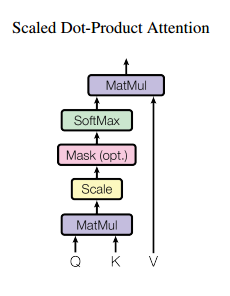
之所以用內積除以維度的開方,論文給出的解釋是:假設Q和K都是獨立的隨機變數,滿足均值為0,方差為1,則點乘後結果均值為0,方差為dk。也即方差會隨維度dk的增大而增大,而大的方差導致極小的梯度(我認為大方差導致有的輸出單元a(a是softmax的一個輸出)很小,softmax反向傳播梯度就很小(梯度和a有關))。為了避免這種大方差帶來的訓練問題,論文中用內積除以維度的開方,使之變為均值為0,方差為1。
5. Prediction
訓練的時候我們知道全部真實label,但是預測時是不知道的。可以首先設定一個開始符s,然後把其他label的位置設為pad,然後對這個序列y做masked attention,因為其他位置設為了pad,所以attention只會用到第一個開始符s,然後用masked attention的第一個輸出做為query和編碼層的輸出做普通attention,得到第一個預測的label y,然後把預測出的label加入到初始序列y中的相應位置,然後再做masked attention,這時第二個位置就不再是pad,那麼attention層就會用到第二個位置的資訊,依此迴圈,最後得到所有的預測label y。其實這樣做也是為了模擬傳統attention的解碼層(當前位置只能用到前面位置的資訊)。
Summary
self-attention層的好處是能夠一步到位捕捉到全域性的聯絡,解決了長距離依賴,因為它直接把序列兩兩比較(代價是計算量變為 O(n2),當然由於是純矩陣運算,這個計算量相當也不是很嚴重),而且最重要的是可以進行平行計算。
相比之下,RNN 需要一步步遞推才能捕捉到,並且對於長距離依賴很難捕捉。而 CNN 則需要通過層疊來擴大感受野,這是 Attention 層的明顯優勢。
self-attention其實和cnn,rnn一樣,也是為了對輸入進行編碼,為了獲得更多的資訊。所以應把self-attention也看成網路中的一個層加進去。
Refrence
2. attention model–Neural machine translation by jointly learning to align and translate論文解讀