
編寫高質量Python程式碼的59個有效方法
這個週末斷斷續續的閱讀完了《Effective Python之編寫高質量Python程式碼的59個有效方法》,感覺還不錯,具有很大的指導價值。 下面將以最簡單的方式記錄這59條建議,並在大部分建議後面加上了說明和示例,文章篇幅大,請您提前備好瓜子和啤酒!
Python學習資料或者需要程式碼、視訊加Python學習群:960410445
1. 用Pythonic方式思考
第一條:確認自己使用的Python版本
(1)有兩個版本的python處於活躍狀態,python2和python3
(2)有很多流行的Python執行時環境,CPython、Jython、IronPython以及PyPy等
(3)在開發專案時,應該優先考慮Python3
第二條:遵循PEP風格指南
PEP8是針對Python程式碼格式而編訂的風格指南,參考: http://www.python.org/dev/peps/pep-0008
(1)當編寫Python程式碼時,總是應該遵循PEP8風格指南
(2)當廣大Python開發者採用同一套程式碼風格,可以使專案更利於多人協作
(3)採用一致的風格來編寫程式碼,可以令後續的修改工作變得更為容易
第三條:瞭解bytes、str、與unicode的區別
(1)python2提供str個unicode,python3中修改為bytes和str,bytes為原始的8位值,str包含unicode字元,在進行編碼轉換時使用decode和encode方法
(2)從檔案中讀取二進位制資料,或向其中寫入二進位制資料時,總應該以‘rb’或‘wb’等二進位制模式來開啟檔案
第四條:用輔助函式來取代複雜的表示式
(1)開發者很容易過度運用Python的語法特性,從而寫出那種特別複雜並且難以理解的單行表示式
(2)請把複雜的表示式移入輔助函式中,如果要反覆使用相同的邏輯,那更應該這麼做
第五條:瞭解切割序列的方法
(1)不要寫多餘的程式碼:當start索引為0,或end索引為序列長度時,應將其省略a[:]
(2)切片操作不會計較start與end索引是否越界,者使得我們很容易就能從序列的前端或後端開始,對其進行範圍固定的切片操作,a[:20]或a[-20:]
(3)對list賦值的時候,如果使用切片操作,就會把原列表中處在相關範圍內的值替換成新值,即便它們的長度不同也依然可以替換
第六條:在單詞切片操作內,不要同時指導start、end和step
(1)這條的目的主要是怕程式碼難以閱讀,作者建議將其拆解為兩條賦值語句,一條做範圍切割,另一條做步進切割
(2)注意:使用[::-1]時會出現不符合預期的錯誤,看下面的例子
msg = '謝謝'
print('msg:',msg)
x = msg.encode('utf-8')
y = x.decode('utf-8')
print('y:',y)
z=x[::-1].decode('utf-8')
print('z:', z)
輸出:

第七條:用列表推導式來取代map和filter
(1)列表推導要比內建的map和filter函式清晰,因為它無需額外編寫lambda表示式
(2)字典與集合也支援推導表示式
第八條:不要使用含有兩個以上表達式的列表推導式
第九條:用生成器表示式來改寫資料量較大的列表推導式
(1)列表推導式的缺點
在推導過程中,對於輸入序列中的每個值來說,可能都要建立僅含一項元素的全新列表,當輸入的資料比較少時,不會出現問題,但如果輸入資料非常多,那麼可能會消耗大量記憶體,並導致程式崩潰,面對這種情況,python提供了生成器表示式,它是列表推導和生成器的一種泛化,生成器表示式在執行的時候,並不會把整個輸出序列呈現出來,而是會估值為迭代器。
把實現列表推導式所用的那種寫法放在一對園括號中,就構成了生成器表示式
numbers = [1,2,3,4,5,6,7,8] li = (i for i in numbers) print(li)
>>>> <generator object <genexpr> at 0x0000022E7E372228>
(2)串在一起的生成器表示式執行速度很快
第十條:儘量用enumerate取代range
(1)儘量使用enumerate來改寫那種將range與下表訪問結合的序列遍歷程式碼
(2)可以給enumerate提供第二個引數,以指定開始計數器時所用的值,預設為0
color = ['red','black','write','green']
#range方法
for i in range(len(color)):
print(i,color[i])
#enumrate方法
for i,value in enumerate(color):
print(i,value)
第11條:用zip函式同時遍歷兩個迭代器
(1)內建的zip函式可以平行地遍歷多個迭代器
(2)Python3中的zip相當於生成器,會在遍歷過程中逐次產生元組,而python2中的zip則是直接把這些元組完全生成好,並一次性地返回整份列表、
(3)如果提供的迭代器長度不等,那麼zip就會自動提前終止
attr = ['name','age','sex']
values = ['zhangsan',18,'man']
people = zip(attr,values)
for p in people:
print(p)
第12條:不要在for和while迴圈後面寫else塊
(1)python提供了一種很多程式語言都不支援的功能,那就是在迴圈內部的語句塊後面直接編寫else塊
for i in range(3):
print('loop %d' %(i))
else:
print('else block!')
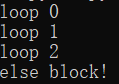
上面的寫法很容易讓人產生誤解:如果迴圈沒有正常執行完,那就執行else,實際上剛好相反
(2)不要再迴圈後面使用else,因為這種寫法既不直觀,又容易讓人誤解
第13條:合理利用try/except/else/finally結構中的每個程式碼塊
try:
#執行程式碼
except:
#出現異常
else:
#可以縮減try中程式碼,再沒有發生異常時執行
finally:
#處理釋放操作
2. 函式
第14條:儘量用異常來表示特殊情況,而不要返回None
(1)用None這個返回值來表示特殊意義的函式,很容易使呼叫者犯錯,因為None和0及空字串之類的值,在表示式裡都會貝評估為False
(2)函式在遇到特殊情況時應該丟擲異常,而不是返回None,呼叫者看到該函式的文件中所描述的異常之後,應該會編寫相應的程式碼來處理它們
第15條:瞭解如何在閉包裡使用外圍作用域中的變數
(1)理解什麼是閉包
閉包是一種定義在某個作用域中的函式,這種函式引用了那個作用域中的變數
(2)表示式在引用變數時,python直譯器遍歷各作用域的順序:
a. 當前函式的作用域
b. 任何外圍作用域(例如:包含當前函式的其他函式)
c. 包含當前程式碼的那個模組的作用域(也叫全域性作用域)
d. 內建作用域(也即是包含len及str等函式的那個作用域)
e. 如果上賣弄這些地方都沒有定義過名稱相符的變數,那麼就丟擲NameError異常
(3)賦值操作時,python直譯器規則
給變數賦值時,如果當前作用域內已經定義了這個變數,那麼該變數就會具備新值,若當前作用域內沒有這個變數,python則會把這次賦值視為對該變數的定義
(4)nonlocal
nonlocal的意思:給相關變數賦值的時候,應該在上層作用域中查詢該變數,nomlocal的唯一限制在於,它不能延申到模組級別,這是為了防止它汙染全域性作用域
(5)global
global用來表示對該變數的賦值操作,將會直接修改模組作用域的那個變數
第16條:考慮用生成器來改寫直接返回列表的函式
參考第九條
第17條:在引數上面迭代時,要多加小心
(1)函式在輸入的引數上面多次迭代時要當心,如果引數是迭代物件,那麼可能會導致奇怪的行為並錯失某些值
看下面兩個例子:
例1:
def normalize(numbers):
total = sum(numbers)
print('total:',total)
print('numbers:',numbers)
result = []
for value in numbers:
percent = 100 * value / total
result.append(percent)
return result
numbers = [15,35,80]
print(normalize(numbers))
輸出:
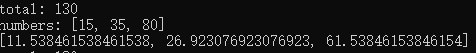
例2:將numbers換成生成器
def fun():
li = [15,35,80]
for i in li:
yield i
print(normalize(fun()))
輸出:

原因:迭代器只產生一輪結果,在丟擲過StopIteration異常的迭代器或生成器上面繼續迭代第二輪,是不會有結果的。
(2)python的迭代器協議,描述了容器和迭代器應該如何於iter和next內建函式、for迴圈及相關表示式互相配合
(3) 想判斷某個值是迭代器還是容器 ,可以拿該值為引數,兩次呼叫iter函式,若結果相同,則是迭代器,呼叫內建的next函式,即可令該迭代器前進一步
if iter(numbers) is iter(numbers):
raise TypeError('Must supply a container')
第18條:用數量可變的位置引數減少視覺雜訊
(1)在def語句中使用*args,即可令函式接收數量可變的位置引數
(2)呼叫函式時,可以採用*操作符,把序列中的元素當成位置引數,傳給該函式
(3)對生成器使用*操作符,可能導致程式耗盡記憶體並崩潰,所以只有當我們能夠確定輸入的引數個數比較少時,才應該令函式接受*arg式的變長引數
(4) 在已經接收*args引數的函式上面繼續新增位置引數 ,可能會產生難以排查的錯誤
第19條:用關鍵字引數來表達可選的行為
(1)函式引數可以按位置或關鍵字來指定
(2)只使用位置引數來呼叫函式,可能會導致這些引數值的含義不夠明確,而關鍵字引數則能夠闡明每個引數的意圖
(3)該函式新增新的行為時,可以使用帶預設值的關鍵字引數,以便與原有的函式呼叫程式碼保持相容
(4) 可選的關鍵字引數 總是應該以關鍵字形式來指定,而不應該以位置引數來指定
第20條:用None和文件字串來描述具有動態預設值的引數
import datetime
import time
def log(msg,when=datetime.datetime.now()):
print('%s:%s' %(when,msg))
log('hi,first')
time.sleep(1)
log('hi,second')
輸出:

兩次顯示的時間一樣,這是因為datetime.now()只執行了一次,也就是它只在函式定義的時候執行了一次,引數的預設值,會在每個模組載入進來的時候求出,而很多模組都在程式啟動時載入。我們可以將上面的函式改成:
import datetime
import time
def log(msg,when=None):
"""
arg when:datetime of when the message occurred
"""
if when is None:
when=datetime.datetime.now()
print('%s:%s' %(when,msg))
log('hi,first')
time.sleep(1)
log('hi,second')
輸出:

(1)引數的預設值,只會在程式載入模組並讀到本函式定義時評估一次,對於{}或[]等動態的值,這可能導致奇怪的行為
(2)對於以動態值作為實際預設值的關鍵字引數來說,應該把形式上的預設值寫為None,並在函式的文件字串裡面描述該預設值所對應的實際行為
第21條:用只能以關鍵字形式指定的引數來確保程式碼明確
(1)關鍵字引數能夠使函式呼叫的意圖更加明確
(2)對於各引數之間很容易混淆的函式,可以宣告只能以關鍵字形式指定的引數,以確保呼叫者必須通過關鍵字來指定它們。對於接收多個Boolean標誌的函式更應該這樣做
3. 類與繼承
第22條:儘量用輔助類來維護程式的狀態,而不要用字典或元組
作者的意思是:如果我們使用字典或元組儲存程式的某部分資訊,但隨著需求的不斷變化,需要逐漸的修改之前定義好的字典或元組結構,會出現多次的巢狀,過分膨脹會導致程式碼出現問題,而且難以理解。遇到這樣的情況,我們可以把巢狀結構重構為類。
(1)不要使用包含其他字典的字典,也不要使用過長的元組
(2)如果容器中包含簡單而又不可變的資料,那麼可以先使用namedtupe來表述,待稍後有需要時,再修改為完整的類
注意:namedtuple類無法指定各引數的預設值,對於可選屬性比較多的資料來說,namedtuple用起來不方便
(3)儲存內部狀態的字典如果變得比較複雜,那就應該把這些程式碼拆分為多個輔組類
第23條:簡單的介面應該接收函式,而不是類的例項
(1)對於連線各種python元件的簡單介面來說,通常應該給其直接傳入函式,而不是先定義某個類,然後再傳入該類的例項
(2)Python種的函式和方法可以像類那麼引用,因此,它們與其他型別的物件一樣,也能夠放在表示式裡面
(3)通過名為__call__的特殊方法,可以使類的例項能夠像普通的Python函式那樣得到呼叫
第24條:以@classmethod形式的多型去通用的構建物件
在python種,不僅物件支援多型,類也支援多型
(1)在Python程式種,每個類只能有一個構造器,也就是__init__方法
(2)通過@classmethod機制,可以用一種與構造器相仿的方式來構造類的物件
(3)通過類方法機制,我們能夠以更加通用的方式來構建並拼接具體的子類
下面以實現一套MapReduce流程計算檔案行數為例來說明:
(1)思路
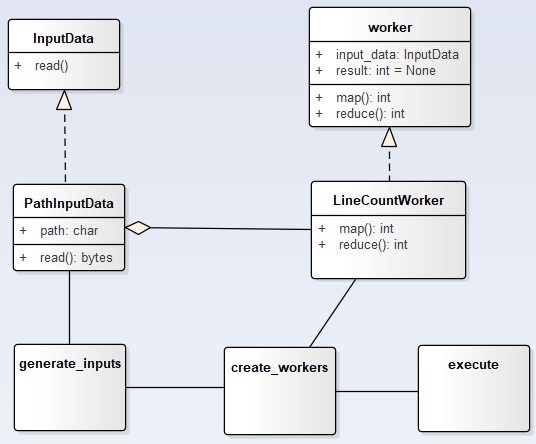
(2)上程式碼
import threading
import os
class InputData:
def read(self):
raise NotImplementedError
class PathInputData(InputData):
def __init__(self,path):
super().__init__()
self.path = path
def read(self):
return open(self.path).read()
class worker:
def __init__(self,input_data):
self.input_data = input_data
self.result = None
def map(self):
raise NotImplementedError
def reduce(self):
raise NotImplementedError
class LineCountWorker(worker):
def map(self):
data = self.input_data.read()
self.result = data.count('\n')
def reduce(self,other):
self.result += other.result
def generate_inputs(data_dir):
for name in os.listdir(data_dir):
yield PathInputData(os.path.join(data_dir,name))
def create_workers(input_list):
workers = []
for input_data in input_list:
workers.append(LineCountWorker(input_data))
return workers
def execute(workers):
threads = [threading.Thread(target=w.map) for w in workers]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
first,rest = workers[0],workers[1:]
for worker in rest:
first.reduce(worker)
return first.result
def mapreduce(data_dir):
inputs = generate_inputs(data_dir)
workers = create_workers(inputs)
return execute(workers)
if __name__ == "__main__":
print(mapreduce('D:\mapreduce_test'))
MapReduce
上面的程式碼在拼接各種元件時顯得非常費力,下面重新使用@classmethod來改進下
import threading
import os
class InputData:
def read(self):
raise NotImplementedError
@classmethod
def generate_inputs(cls,data_dir):
raise NotImplementedError
class PathInputData(InputData):
def __init__(self,path):
super().__init__()
self.path = path
def read(self):
return open(self.path).read()
@classmethod
def generate_inputs(cls,data_dir):
for name in os.listdir(data_dir):
yield cls(os.path.join(data_dir,name))
class worker:
def __init__(self,input_data):
self.input_data = input_data
self.result = None
def map(self):
raise NotImplementedError
def reduce(self):
raise NotImplementedError
@classmethod
def create_workers(cls,input_list):
workers = []
for input_data in input_list:
workers.append(cls(input_data))
return workers
class LineCountWorker(worker):
def map(self):
data = self.input_data.read()
self.result = data.count('\n')
def reduce(self,other):
self.result += other.result
def execute(workers):
threads = [threading.Thread(target=w.map) for w in workers]
for thread in threads:
thread.start()
for thread in threads:
thread.join()
first,rest = workers[0],workers[1:]
for worker in rest:
first.reduce(worker)
return first.result
def mapreduce(data_dir):
inputs = PathInputData.generate_inputs(data_dir)
workers = LineCountWorker.create_workers(inputs)
return execute(workers)
if __name__ == "__main__":
print(mapreduce('D:\mapreduce_test'))
修改後的MapReduce
通過類方法實現多型機制,我們可以用更加通用的方式來構建並拼接具體的類
第25條:用super初始化父類
如果從python2開始詳細的介紹super使用方法需要很大的篇幅,這裡只介紹python3中的使用方法和MRO
(1)MRO即為方法解析順序,以標準的流程來安排超類之間的初始化順序,深度優先,從左至右,它也保證鑽石頂部那個公共基類的__init__方法只會執行一次
(2)python3中super的使用方法
python3提供了一種不帶引數的super呼叫方法,該方式的效果與用__class__和self來呼叫super相同
class A(Base):
def __init__(self,value):
super(__class__,self).__init__(value)
class A(Base):
def __init__(self,value):
super().__init__(value)
推薦使用上面兩種方法,python3可以在方法中通過__class__變數精確的引用當前類,而Python2中則沒有定義__class__方法
(3)總是應該使用內建的super函式來初始化父類
第26條:只在使用Mix-in元件製作工具類時進行多重繼承
python是面向物件的程式語言,它提供了一些內建的程式設計機制,使得開發者可以適當地實現多重繼承,但是,我們應該儘量避免多重繼承,若一定要使用,那就考慮編寫mix-in類,mix-in是一種小型的類,它只定義了其他類可能需要提供的一套附加方法,而不定義自己的 例項屬性,此外,它也不要求使用者呼叫自己的__init__函式
(1)能用mix-in元件實現的效果,就不要使用多重繼承來做
(2)將各功能實現為可插拔的mix-in元件,然後令相關的類繼承自己需要的那些元件,即可定製該類例項所具備的行為
(3)把簡單的行為封裝到mix-in元件裡,然後就可以用多個mix-in組合出複雜的行為了
第27條:多用public屬性,少用private屬性
python沒有從語法上嚴格保證private欄位的私密性,用簡單的話來說,我們都是成年人。
個人習慣:_XXX 單下劃代表protected;__XXX 雙下劃線開始的且不以_結尾表示private;__XXX__系統定義的屬性和方法
class People:
__name="zhanglin"
def __init__(self):
self.__age = 16
print(People.__dict__)
p = People()
print(p.__dict__)

會發現__name和__age屬性名都發生了變化,都變成了(_類名+屬性名), 只有在__XXX這種命名方式下才會發生變化,所以以這種方式作為偽私有說明
(1)python編譯器無法嚴格保證private欄位的私密性
(2)不要盲目地將屬性設為private,而是應該從一開始就做好規劃,並允許子類更多地訪問超類內部的api
(3)應該更多的使用protected屬性,並在文件中把這些欄位的合理用法告訴子類的開發者,而不是試圖用private屬性來限制子類訪問這些欄位
(4)只有當子類不受自己控制時,才可以考慮用private屬性來避免名稱衝突
第28條:繼承collections.abc以實現自定義的容器型別
collections.abc模組定義了一系列抽象基類,它們提供了每一種容器型別所應具備的常用方法,大家可以自己參考原始碼
__all__ = ["Awaitable", "Coroutine",
"AsyncIterable", "AsyncIterator", "AsyncGenerator",
"Hashable", "Iterable", "Iterator", "Generator", "Reversible",
"Sized", "Container", "Callable", "Collection",
"Set", "MutableSet",
"Mapping", "MutableMapping",
"MappingView", "KeysView", "ItemsView", "ValuesView",
"Sequence", "MutableSequence",
"ByteString",
]
(1)如果定製的子類比較簡單,那就可以直接從Python的容器型別(如list、dict)中繼承
(2)想正確實現自定義的容器型別,可能需要編寫大量的特殊方法
(3)編寫自制的容器型別時,可以從collections.abc模組的抽象基類中繼承,那些基類能夠確保我們的子類具備適當的介面及行為
4. 元類及屬性
第29條:用純屬性取代get和set方法
(1)編寫新類時,應該用簡單的public屬性來定義其介面,而不要手工實現set和get方法
(2)如果訪問物件的某個屬性,需要表現出特殊的行為,那就用@property來定義這種行為
比如下面的示例:成績必須在0-100範圍內
class Homework:
def __init__(self):
self.__grade = 0
@property
def grade(self):
return self.__grade
@grade.setter
def grade(self,value):
if not (0<=value<=100):
raise ValueError('Grade must be between 0 and 100')
self.__grade = value
(3)@property方法應該遵循最小驚訝原則,而不應該產生奇怪的副作用
(4)@property方法需要執行得迅速一些,緩慢或複雜的工作,應該放在普通的方法裡面
(5)@property的最大缺點在於和屬性相關的方法,只能在子類裡面共享,而與之無關的其他類都無法複用同一份實現程式碼
第30條:考慮用@property來代替屬性重構
作者的意思是:當我們需要遷移屬性時(也就是對屬性的需求發生變化的時候),我們只需要給本類新增新的功能,原來的那些呼叫程式碼都不需要改變,它在持續完善介面的過程中是一種重要的緩衝方案
(1)@property可以為現有的例項屬性新增新的功能
(2)可以用@properpy來逐步完善資料模型
(3)如果@property用的太過頻繁,那就應該考慮徹底重構該類並修改相關的呼叫程式碼
第31條:用描述符來改寫需要複用的@property方法
首先對描述符進行說明,先看下面的例子:
class Grade:
def __init(self):
self.__value = 0
def __get__(self, instance, instance_type):
return self.__value
def __set__(self, instance, value):
if not (0 <= value <= 100):
raise ValueError('Grade must be between 0 and 100')
self.__value = value
class Exam:
math_grade = Grade()
chinese_grade = Grade()
science_grade = Grade()
if __name__ == "__main__":
exam = Exam()
exam.math_grade = 99
exam1 = Exam()
exam1.math_grade = 75
print('exam.math_grade:',exam.math_grade, 'is wrong')
print('exam1.math_grade:',exam1.math_grade, 'is right')
輸出:

會發現在兩個Exam例項上面分別操作math_grade時,導致了錯誤的結果,出現這種情況的原因是因為 該math_grade屬性為Exam類的例項 ,為了解決這個問題,看下面的程式碼
class Grade:
def __init__(self):
self.__value = {}
def __get__(self, instance, instance_type):
if instance is None:
return self
return self.__value.get(instance,0)
def __set__(self, instance, value):
if not (0 <= value <= 100):
raise ValueError('Grade must be between 0 and 100')
self.__value[instance] = value
class Exam:
math_grade = Grade()
chinese_grade = Grade()
science_grade = Grade()
if __name__ == "__main__":
exam = Exam()
exam.math_grade = 99
exam1 = Exam()
exam1.math_grade = 75
print('exam.math_grade:',exam.math_grade, 'is wrong')
print('exam1.math_grade:',exam1.math_grade, 'is right')
輸出:

上面這種實現方式很簡單,而且能夠正常運作,但它仍然有個問題,那就是會洩露記憶體,在程式的生命期內,對於傳給__set__方法的每個Exam例項來說,__values字典都會儲存指向該例項的一份引用,者就導致例項的引用計數無法降為0,從而使垃圾收集器無法將其收回。使用python的內建weakref模組,可解決上述問題。
class Grade:
def __init(self):
self.__value = weakref.WeakKeyDictionary()
(1)如果想複用@property方法及其驗證機制,那麼可以自己定義描述符
(2)WeakKeyDictionary可以保證描述符類不會洩露記憶體
(3)通過描述符協議來實現屬性的獲取和設定操作時,不要糾結於__getattribute__的方法具體運作細節
第32條:用__getattr__、__getattribute__和__setattr__實現按需生成的屬性
如果某個類定義了__getattr__,同時系統在該類物件的例項字典中又找不到待查詢的屬性,那麼就會呼叫這個方法
惰性訪問的概念:初次執行__getattr__的時候進行一些操作,把相關的屬性載入進來,以後再訪問該屬性時,只需從現有的結果中獲取即可
程式每次訪問物件的屬性時,Python系統都會呼叫__getattribute__,即使屬性字典裡面已經有了該屬性,也以讓會觸發__getattribute__方法
(1)通過__getattr__和__setattr__,我們可以用惰性的方式來載入並儲存物件的屬性
(2)要理解__getattr__和__getattribute__的區別:前者只會在待訪問的屬性缺失時觸發,,而後者則會在每次訪問屬性時觸發
(3)如果要在__getattribute__和__setattr__方法中訪問例項屬性,那麼應該直接通過super()來做,以避免無限遞迴
第33條:用元類來驗證子類
元類最簡單的一種用途,就是驗證某個類定義的是否正確,構建複雜的類體系時,我們可能需要確保類的風格協調一致,確保某些方法得到了覆寫,或是確保類屬性之間具備某些嚴格的關係。
下例判斷類屬性中是否含有name屬性:
#驗證某個類的定義是否正確
class Meta(type):
def __new__(meta,name,bases,class_dict):
print('class_dict:',class_dict)
if not class_dict.get('name',None): #判斷類屬性中是否含有name屬性
raise AttributeError('must has name attribute')
return type.__new__(meta,name,bases,class_dict)
class A(metaclass=Meta):
def __init__(self):
self.chinese_grade = 90
self.math_grade = 99
if __name__ == '__main__':
a = A()
輸出:
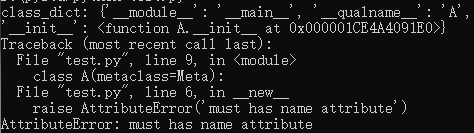
(1)通過元類,我們可以在生成子類物件之前,先驗證子類的定義是否合乎規範
(2)python系統把子類的整個class語句體處理完畢之後,就會呼叫其元類的__new__方法
第34條:用元類來註冊子類
元類還有一個用途就是在程式中自動註冊型別,對於需要反向查詢(reverse lookup)的場合,這種註冊操作很有用
看下面的例子:對物件進行序列化和反序列化
import json
register = {}
class Meta(type):
def __new__(meta,name,bases,attr_dic):
cls = type.__new__(meta,name,bases,attr_dic)
print('create class in Meta:', cls)
register[cls.__name__] = cls
return cls
class Serializable(metaclass=Meta):
def __init__(self,*args):
self.args = args
def serialize(self):
return json.dumps({'class':self.__class__.__name__, 'args':self.args})
def deserilize(self,json_data):
json_dict = json.loads(json_data)
classname = json_dict['class']
args = json_dict['args']
return register[classname](*args)
class Point2D(Serializable):
def __init__(self,x,y):
super().__init__(x,y)
self.x = x
self.y = y
def add(self):
return self.x + self.y
if __name__ == "__main__":
p = Point2D(2,5)
data = p.serialize()
print('serialize_data:',data)
new_point2d = p.deserilize(data)
print('new_point2d:',new_point2d)
print(new_point2d.add())
輸出:

(1)通過元類來實現類的註冊,可以確保所有子類就都不會洩露,從而避免後續的錯誤
第35條:用元類來註解類的屬性
(1)藉助元類,我們可以在某個類完全定義好之前,率先修改該類的屬性
(2)描述符與元類能夠有效的組合起來,以便對某種行為做出修飾,或在程式執行時探查相關資訊
(3)如果把元類與描述符相結合,那就可以在不使用weakref模組的前提下避免記憶體洩漏
5. 併發與並行
併發和並行的關鍵區別在於能不能提速,若是並行,則總任務的執行時間會減半,若是併發,那麼即使可以看似平行的方式分別執行多條路徑,依然不會使總任務的執行速度得到提升,用Python語言編寫併發程式,是比較容易的,通過系統呼叫、子程序和C語言擴充套件等機制,也可以用Python平行地處理一些事務,但是,要想使併發式的python程式碼以真正平行的方式來執行,卻相當困難。
可以先閱讀我之前的部落格,相信會有幫組: python究竟要不要使用多執行緒
第36條:用subprocess模組來管理子程序
在多年的發展過程中,Python演化出了多種執行子程序的方式,其中包括popen、popen2和os.exec*等,然而,對於至今的Python來說,最好且最簡單的子程序管理模組,應該是內建的subprocess模組
第37條:可以用執行緒來執行阻塞式I/O,但不要用它做平行計算
(1)因為受全域性解釋鎖(GIL)的限制,所以多條Python執行緒不能在多個CPU核心上面平行地執行位元組碼
(2)儘管受制於GIL,但是python的多執行緒功能依然很有用,它可以輕鬆地模擬出同一時刻執行多項任務的效果
(3)通過python執行緒,我們可以平行地執行多個系統呼叫,這使得程式能夠在執行阻塞式I/O操作的同時,執行一些運算操作
第38條:線上程中使用Lock來防止資料競爭
class LockingCounter:
def __init__(self):
self.lock = threading.Lock()
self.count = 0
def increment(self, offset):
with self.lock:
self.count += offset
第39條:用Queue來協調各執行緒之間的工作
作者舉了一個照片處理系統的例子:
需求:該系統從數碼相機裡面持續獲取照片、調整其尺寸,並將其新增到網路相簿中。
實現:使用三階段的管線實現,需要4個自定義的deque訊息佇列,第一階段獲取新照片,第二階段把下載好的照片傳給縮放函式,第三階段把縮放後的照片交給上傳函式
問題:該程式雖然可以正常執行,但是每個階段的工作函式都會有差別,這使得前一階段可能會拖慢後一階段的進度,從而令整條管線遲滯,後一階段會在其迴圈語句中,反覆查詢輸入佇列,以求獲取新的任務,而任務卻遲遲未到達,這將令後一階段陷入飢餓,會白白浪費CPU時間,效率特低
內建的queue模組的Queue類可以解決上述問題,因為其get方法會持續阻塞,直到有新的資料加入
import threading
from queue import Queue
class ClosableQueue(Queue):
SENTINEL = object()
def close(self):
self.put(SENTINEL)
def __iter__(self):
while True:
item = self.get()
try:
if item is self.SENTINEL:
return
yield item
finally:
self.task_done()
class StoppabelWoker(threading.Thread):
def __init__(self,func,in_queue,out_queue):
self.func = func
self.in_queue = in_queue
self.out_queue = out_queue
def run(self):
for item in self.in_queue:
result = self.func(item)
self.out_queue.put(result)
(1)管線是一種優秀的任務處理方式,它可以把處理流程劃分未若干個階段,並使用多條python執行緒來同時執行這些任務
(2)構建併發式的管線時,要注意許多問題,其中包括:如何防止某個階段陷入持續等待的狀態之中,如何停止工作執行緒,以及如何防止記憶體膨脹等
(3)Queue類所提供的機制,可以cedilla解決上述問題,它具備阻塞式的佇列操作,能夠指定緩衝區的尺寸,而且還支援join方法,這使得開發者可以構建出健壯的管線
第40條:考慮用協程來併發地執行多個函式
(1)協程提供了一種有效的方式,令程式看上去好像能夠同時執行大量函式
(2)對於生成器內的yield表示式來說,外部程式碼通過send方法傳給生成器的那個值就是該表示式所要具備的值
(3)協程是一種強大的工具,它可以把程式的核心邏輯,與程式同外部環境互動時所使用的程式碼相隔離
第41條:考慮用concurrent.futures來實現真正的平行計算
參考之前的部落格: 網路爬蟲必備知識之concurrent.futures庫
6. 內建模組
第42條:用functools.wrap定義函式修飾器
為了維護函式的介面,修飾之後的函式,必須保留原函式的某些標準Python屬性,例如__name__和__module__,這個時候我們需要使用functools.wraps來確保修飾後函式具備正確的行為
第43條:考慮以contextlib和with語句來改寫可複用的try/finally程式碼
(1)可以用with語句來改寫try/finally塊中的邏輯,以提升複用程度,並使程式碼更加整潔
import threading
lock = threading.Lock()
lock.acquier()
try:
print("lock is held")
finally:
lock.release()
可以直接使用下面的語法:
import threading
lock = threading.Lock()
with lock:
print("lock is held")
(2)內建的contextlib模組提供了名叫為contextmanager的修飾器,開發者只需要用它來修飾自己的函式,即可令該函式支援with語句
from contextlib import contextmanager
@contextmanager
def file_open(path):
''' file open test'''
try:
fp = open(path,"wb")
yield fp
except OSError:
print("We had an error!")
finally:
print("Closing file")
fp.close()
if __name__ == "__main__":
with file_open("contextlibtest.txt") as fp:
fp.write("Testing context managers".encode("utf-8"))
(3)情景管理器可以通過yield語句向with語句返回一個值,此值會賦給由as關鍵字所指定的變數
第44條:用copyreg實現可靠pickle操作
(1)內建的pickle模組,只適合用來彼此信任的程式之間,對相關物件執行序列化和反序列化操作
(2)如果用法比較複雜,那麼pickle模組的功能可能就會出現問題,我們可以用內建的copyreg模組和pickle結合起來使用,以便為舊資料新增缺失的屬性值、進行類的版本管理、並給序列化之後的資料提供固定的引入路徑
第45條:應該用datetime模組來處理本地時間,而不是time模組
(1)不要用time模組在不同時區之間進行轉換
(2)如果要在不同時區之間,可靠地執行轉換操作,那就應該把內建的datetime模組與開發者社群提供的pytz模組打起來使用
(3)開發者總是應該先把時間表示為UTC格式,然後對其執行各種轉換操作,最後再把它轉回本地時間
第46條:使用內建演算法和資料結構
(1)雙向佇列 collections.deque
(2)有序字典 dollections.OrderDict
(3)帶有預設值的有序字典 collections.defaultdict
(4)堆佇列(優先順序佇列)heapq.heap
(5)二分查詢 bisect模組中的bisect_left函式等提供了高效的二分折半搜尋演算法
(6)與迭代器有關的工具 itertools模組
第47條:在重視精度的場合,應該使用decimal
(1)decimal模組中的Decimal類預設提供28個小數位,以進行定點數字運算,還可以按照開發射所要求的精度及四捨五入
第48條:學會安裝由Python開發者社群所構建的模組
7. 協作開發
第49條:為每個函式、類和模組編寫文件字串
第50條:用包來安排模組,並提供穩固的API
(1)只要把__init__.py檔案放入含有其他原始檔的目錄裡,就可以將該目錄定義為包,目錄中的檔案,都將成為包的子模組,該包的目錄下面,也可以含有其他的包
(2)把外界可見的名稱,列在名為__all__的特殊屬性裡,即可為包提供一套明確的API
第51條:為自編的模組定義根異常,以便呼叫者與API相隔離
意思就是單獨用個模組提供各種異常API
第52條:用適當的方式打破迴圈依賴關係
(1)調整引入順序
(2)先引入、再配置、最後執行
只在模組中給出函式、類和常量的定義,而不要在引入的時候真正去執行那些函式
(3)動態引入:在函式或方法內部使用import語句
第53條:用虛擬環境隔離專案,並重建其依賴關係
參考之前的部落格: Python之用虛擬環境隔離專案,並重建依賴關係
8. 部署
第54條:考慮用模組級別的程式碼來配置不同的部署環境
(1)可以根據外部條件來決定模組的內容,例如,通過sys和os模組來查詢宿主作業系統的特性,並以此來定義本模組中的相關結構
第55條:通過repr字串來輸出除錯資訊
第56條:通過unittest來測試全部程式碼
這個在後面會單獨寫篇部落格對unittest單元測試模組進行詳細說明
第57條:考慮用pdb實現互動除錯
第58條:先分析效能,然後再優化
(1)優化python程式之前,一定要先分析其效能,因為python程式的效能瓶頸通常很難直接觀察出來
(2)做效能分析時,應該使用cProfile模組,而不要使用profile模組,因為前者能夠給出更為精確的效能分析資料
第59條:用tracemalloc來掌握記憶體的使用及洩露情況
在Python的預設實現中,也就是Cpython中,記憶體管理是通過引用計數來處理的,另外,Cpython還內建了迴圈檢測器,使得垃圾回收機制能夠把那些自我引用的物件清除掉
(1)使用內建的gc模組進行查詢,列出垃圾收集器當前所知道的每個物件,該方法相當笨拙
(2)python3.4提供了內建模組tracemalloc可以打印出Python系統在執行每一個分配記憶體操作時所具備的完整堆疊資訊
文章到這裡就全部結束了,感謝您這麼有耐心的閱讀!