
Marginally Interesting: Matrices, JNI, DirectBuffers, and Number Crunching in Java
One thing Java lacks is a fast matrix library. There things like JAMA and COLT (not using its LAPACK bindings), but compared to state-of-the-art implementations like ATLAS, they are orders of magnitude slower.
Therefore I’ve set out some time ago to write
Basically, there are two areas where the Java platform can give you quite a headache:
- Pass large amounts of data to native code.
- Lack of control about how good the JIT compiles code.
Passing Data to Native Code
For a number of reasons, producing highly tuned linear algebra code still requires a lot of low-level fiddling with machine code. If you want really fast code, you have to rely on libraries like ATLAS. The question is then how you pass the data from Java to ATLAS.
Maybe the easiest choice is to store the data in primitive type arrays
like double[] and then access them via JNI. Only that the
documentation is quite
explicit
about the fact that this will not work well for large arrays as you
typically will get a copy of the array, and afterwards, the result has
to be copied back.
The solutions proposed by Sun is to use direct buffers which permits to allocate a piece of memory outside of the VM which is then passed directly to native code.
This was also the solution adopted by our jblas library. However, it quickly turned out that the memory management for DirectBuffers is anything but perfect. As has already been pointed out by others, the main problem is that Java does not take the amount of DirectBuffers into account to compute its memory footprint. What this means is that if you allocate a large number of DirectBuffers, the JVM will happy fill all of your memory, and potentially the swap space without triggering a single garbage collection.
After this happened a few times to me I began wondering whether
DirectBuffers are garbage collected at all, but it seems that
everything is implement reasonably
well: the
memory allocated with direct buffers is managed by PhantomReferences
in order to be notified when the corresponding object is garbage
collected, and if you call System.gc() by hand often enough your
DirectBuffers eventually get garbage collected. That is, most of the
time, at least.
The problem is that there is hardly a way around this. Maybe it’s my fault because direct buffers were never intended to be allocated in large numbers. I guess the typical use would be to allocate a direct buffer of some size and then use that one fixed direct buffer to transfer data between the native code and the JVM.
The only problem is that this is basically the copying scenario which direct buffers should have helped to avoid… .
I’ve written a little program which compares the time it takes to copy an array using the GetDoubleArrayElements() function and using the bulk put and get functions of DoubleBuffer. The results look like this (on an Intel Core2 with 2 GHz):
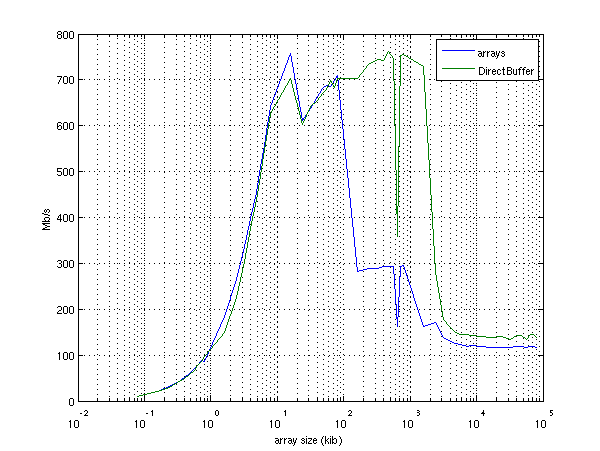
What is a bit funny (and also brings me directly to the second point)
is that GetDoubleArrayElements takes longer than DoubleBuffer.put()
and get() after a size of about 100kb. Both routines basically have to
deal with the same task of copying data from a Java primitive array
into a piece of raw memory. But for some reason, the DoubleBuffer
variant seems to be able to uphold a certain throughput for much
higher amounts of memory.
Code Optimization
The second point basically means that it’s more difficult than in a traditional compile language to control how fast your code becomes after it has been compiled JIT. In principle, there is no reason why this should be true, but I’ve observed a few funny effects which have caused me to doubt that the HotSpot technology is optimized for number crunching.
For example, as I’ve discussed elsewhere, copying data between arrays, or accessing DirectBuffers leads to drastically different performances on the same virtual machine depending on the byte-code compiler. For some reason, the eclipse compiler seems to produce code which leads to much faster machine code than Sun’s own compiler on Sun’s HotSpot JVM.
What this means that it is very hard to optimize code in Java, because you cannot be sure whether it will lead to efficient machine code by the JIT compiler of the virtual machine. With compile languages the situation is in principle similar, but at least you can control which compiler you use and optimize against that.
Summary
So I’m not quite sure what this means. Maybe some JVM guru can enlight me on what is happening here. And I don’t even see what is wrong with the way direct buffers are implemented, but on the bottom line, memory management for direct buffers is not very robust, meaning that your program will typically consume much more memory than it should.
Posted by at 2008-10-23 16:13:00 +0200
blog comments powered by Disqus