
Storing Tweets in a Relational Database
As you can see, a single tweet has a wealth of information, and most of these keys correspond to nested dictionaries and lists. If you have not worked with the Twitter API before I would recommend familiarizing yourself with the search function, looking at the different filters you can apply. It should be immediately apparent that a single tweet easily generates five times as much data as we see in the body text. Here a request yields a maximum of 100 tweets, but you can imagine that we could chain requests using a loop (being careful to not surpass the rate-limit) to gather all the tweets for the last week.
Structuring the Database
The nature of our pizza obsession is such that it extends beyond what is being tweeted about our favorite greasy indulgence, to the users that are tweeting about it. Any time we have multiple classes of objects in our model that are related in some way, it is an indication that we may want to create a relational database
Our problem is as follows: the SQL database has tables which can contain integers and text, and are great for storing our tweets and associated user data. But we wish to do analysis in Python, which is an object oriented language, and so we want to be able to interact with tweets and users as objects. SQLAlchemy offers an easy way to design the architecture of our SQL database entirely in Python code, mapping out the relationships that we want in a simple way. Moreover, it then allows us to execute SQL queries from Python, basically translating the code for us, which will be useful for pulling from our database when we want to perform analysis later on. Lets look at our simple case:

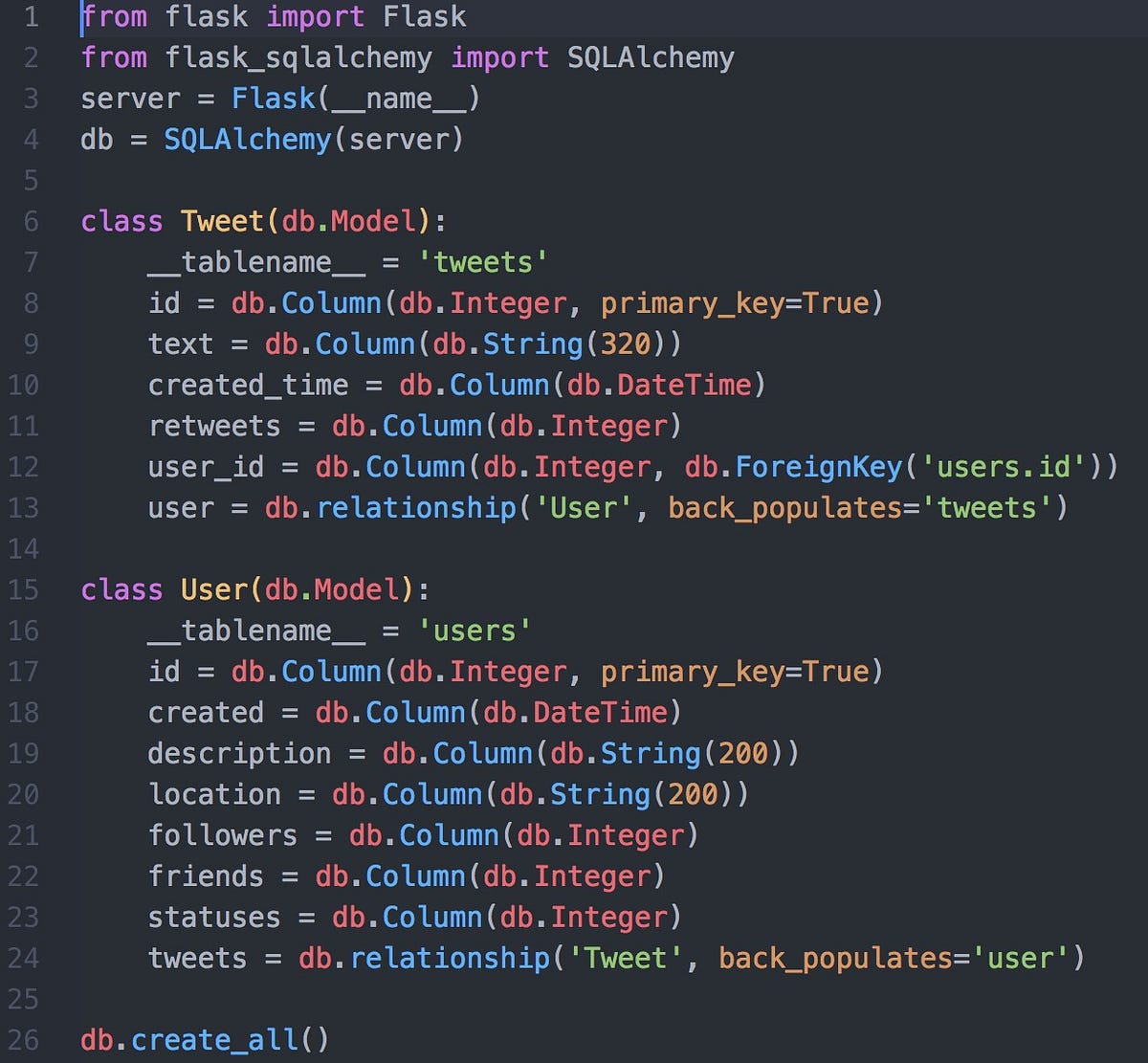
This python code establishes the models of our SQL database. The Tweet and User classes correspond to SQL tables with the listed columns. The relationship between users and tweets is one to many, and our tweets should have a user id so they can be attributed to their parent class. Now, when we want to populate these tables, we can simply create instances of the tweet and user classes, and pass in the attributes obtained by our Twitter API calls.
Streaming Tweets Live
Now that we have our database set up, we can begin to populate it. Note that when you first set up a relational database, it is crucial to make sure that all of the relationships are properly established. Here we simply need to add one tweet and make sure it has a user and vice versa, but when dealing with much more complex systems this can mean checking a lot of relationships. If the models are not behaving exactly as we like, we can simply drop our database, tweak the model file and re-create it.
The streaming API works a lot like the search api, with a couple exceptions. Once again I will point to the documentation, but we’ll walk through it.
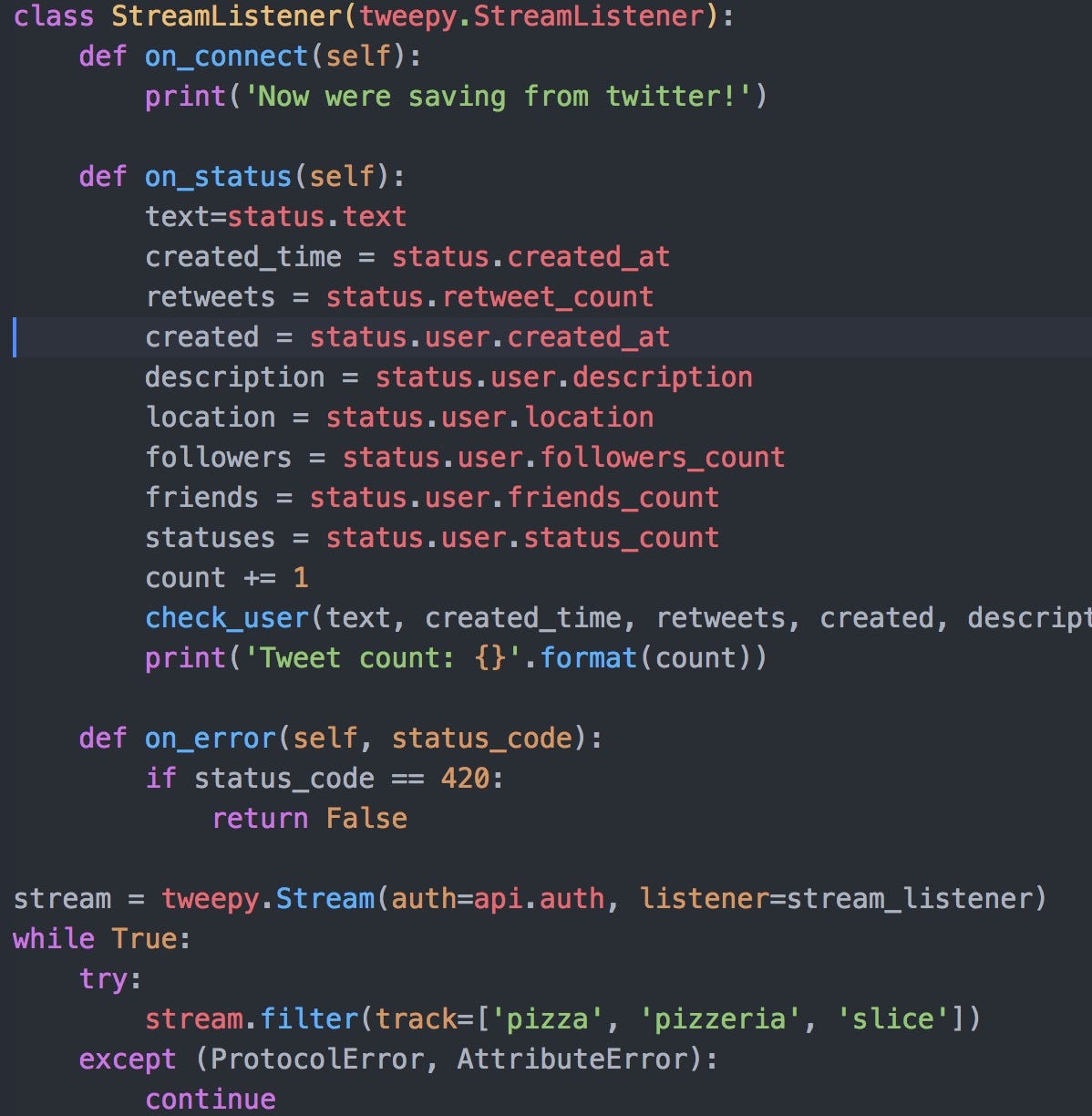
This is the general structure of a Streamlistener object. The different functions are executed when the listener encounters a status, error etc. There are many other types of functions that can be written, but for our case these will suffice. The contents of on_status allow us to extract the information we are interested in before calling the check_user function to instantiate our tweets and users with the passed attributes.

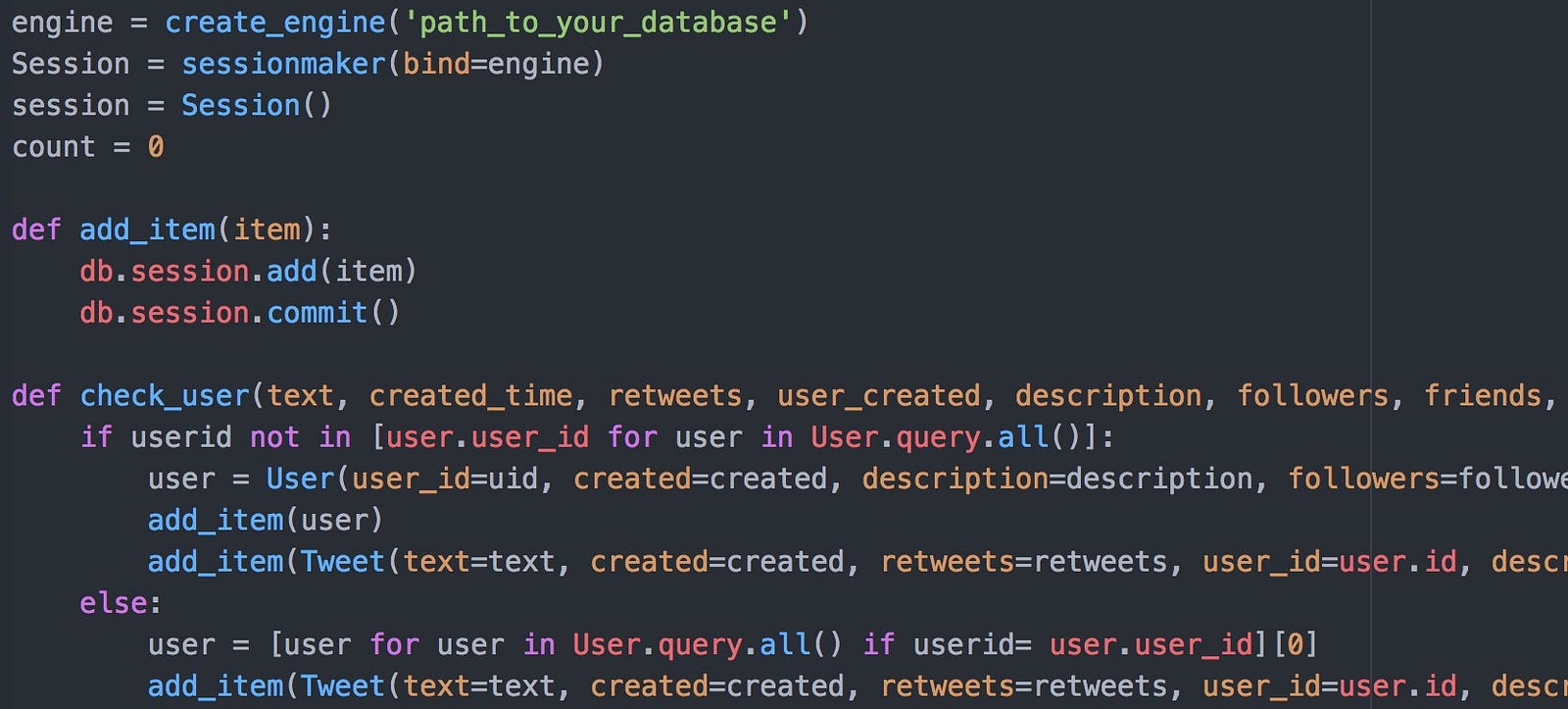
As you can see, we are creating our unique users and tweets at the same time, to ensure that they are linked via the user id. To make sure that we do not have duplicated users, we first need to check the user table to make sure that they are not already there. Then we add the objects to a session and commit them to the database. These two simple blocks of code comprise a simple
When you put all of this together, you have a powerful tool to pull tweets from the Twitter API and store them in a database, keeping the relationships between tweets and users. With SQLAlchemy, you will be able to write a query to return all the tweets of a given user. I hope this has been instructive, and I will leave a couple additional resources below. Soon, we will know everything anyone is saying about pizza on Twitter!