
Windows下使用sbt打包scala工程
阿新 • • 發佈:2018-12-29
1.windows下安裝sbt及scala的IDE:https://blog.csdn.net/weixin_42247685/article/details/80390858
2.新建scala_sbt工程
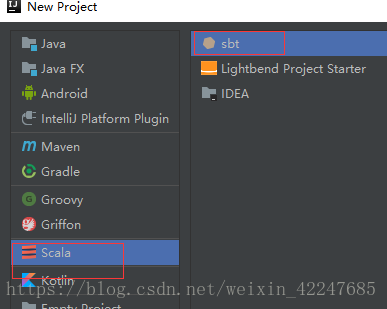
3.新建例項scala指令碼:

指令碼內容:
import java.io.File import org.apache.spark.sql.{Row, SaveMode, SparkSession} object helloWorld { def main(args:Array[String]): Unit = { //val warehouseLocation = new File("spark-warehouse").getAbsolutePath val spark = SparkSession .builder() .appName("Spark Hive Example") //.config("spark.sql.warehouse.dir", warehouseLocation) .enableHiveSupport() .getOrCreate() import spark.implicits._ import spark.sql sql("SELECT count(*) FROM dwb.dwb_trde_cfm_ordr_goods_i_d where pt = '2018-07-15'").show() } }
上面內容複製後會一堆報錯,不用管,因為依賴還沒有新增。
4.IDE中sbt相關的設定修改下:
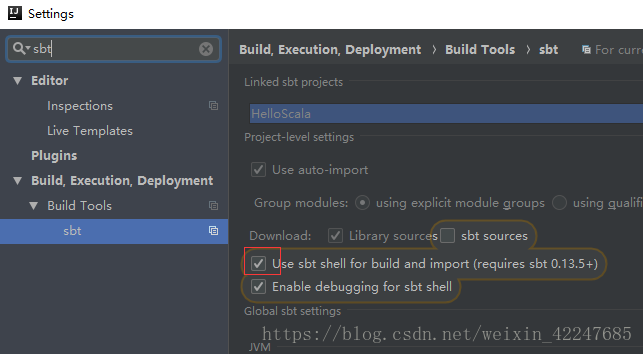
5.在build.sbt檔案中新增下面的程式碼:

name := "Graph"
version := "0.1"
scalaVersion := "2.11.9"
updateOptions := updateOptions.value.withCachedResolution(true)
fullResolvers := Seq(
"Pdd" at "http://maven-pdd.corp.yiran.com:8081/repository/maven-public/",
"Local Maven" at Path.userHome.asFile.toURI.toURL + ".m2/repository",
"Ali" at "http://maven.aliyun.com/nexus/content/groups/public/",
"Repo1" at "http://repo1.maven.org/maven2/"
)
libraryDependencies += "org.rogach" %% "scallop" % "3.1.1"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.1" % "provided"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.1.1" % "provided"
libraryDependencies += "org.apache.spark" %% "spark-mllib" % "2.1.1" % "provided"
libraryDependencies += "org.apache.spark" %% "spark-hive" % "2.1.1" % "provided"
//libraryDependencies += "org.apache.httpcomponents" % "httpclient" % "4.5.6"
//libraryDependencies += "net.liftweb" %% "lift-json" % "3.3.0"
libraryDependencies += "org.testng" % "testng" % "6.14.3" % Test
libraryDependencies += "org.scalatest" %% "scalatest" % "3.0.5" % Test
test in assembly := {}
//mainClass in assembly := Some("com.pdd.bigdata.risk.rimo.feature.Application")
assemblyMergeStrategy in assembly := {
case PathList( 上面程式碼中註釋的地方改成自己的類名和工程名。
這是右下角會彈出是否import的提示,選擇自動import,等待載入完畢。
6.在project下新增紅框處的file檔案
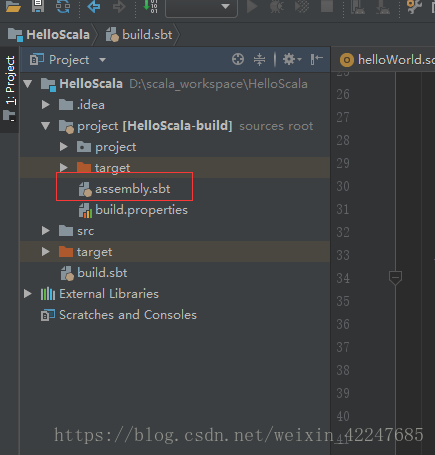
檔案內容:
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "0.14.7")完畢後所有報錯會消失

7.讓IDE顯示Tool Buttons(左圖),在IDE右側雙擊箭頭處的assembly自動打包(右圖),打包完成後在sbt_shell中會提示打包路徑。
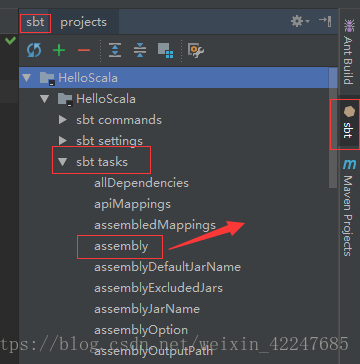
8.將打包的jar包上傳至spark叢集,然後執行下面命令:
spark-submit \
--class work._01_Graph_mallid_buyerid.step01_buildGraph \
--master yarn \
--deploy-mode cluster \
--files /etc/bigdata/conf/spark/hive-site.xml \
/home/buming/work/spark_scala/HelloScala-assembly-0.1.jar
注意:1.class後面是自己的類名。2.最後一行是jar包在spark上的路徑(pwd可以檢視)3.--deploy-mode 指定執行模式。