
First impressions of MLflow
MLflow is one of the latest open source projects added to the Apache Spark ecosystem by databricks. Its first debut was at the Spark + AI Summit 2018. The source code is hosted in the mlflow GitHub repo and is still in the alpha release stage. The current version is 0.4.1 and was released on 08/03/2018.
However, this blog will dig further into MLflow and describe some specifics based on my first-hand experience and the study of the source code. I also provide suggestions on areas where I think MLflow can be improved.
What is MLflow
MLflow is described as an open source platform for the complete machine learning lifecycle. A complete machine learning lifecycle includes raw data ingestion, data analysis and preparation, model training, model evaluation, model deployment, and model maintenance. MLflow
- Log important parameters, metrics, and other data that is important to the machine learning model
- Track the environment a model is run on
- Run any machine learning codes on that environment
- Deploy and export models to various platforms with multiple packaging formats
MLflow is implemented as several modules, where each module supports a specific function.
MLflow components
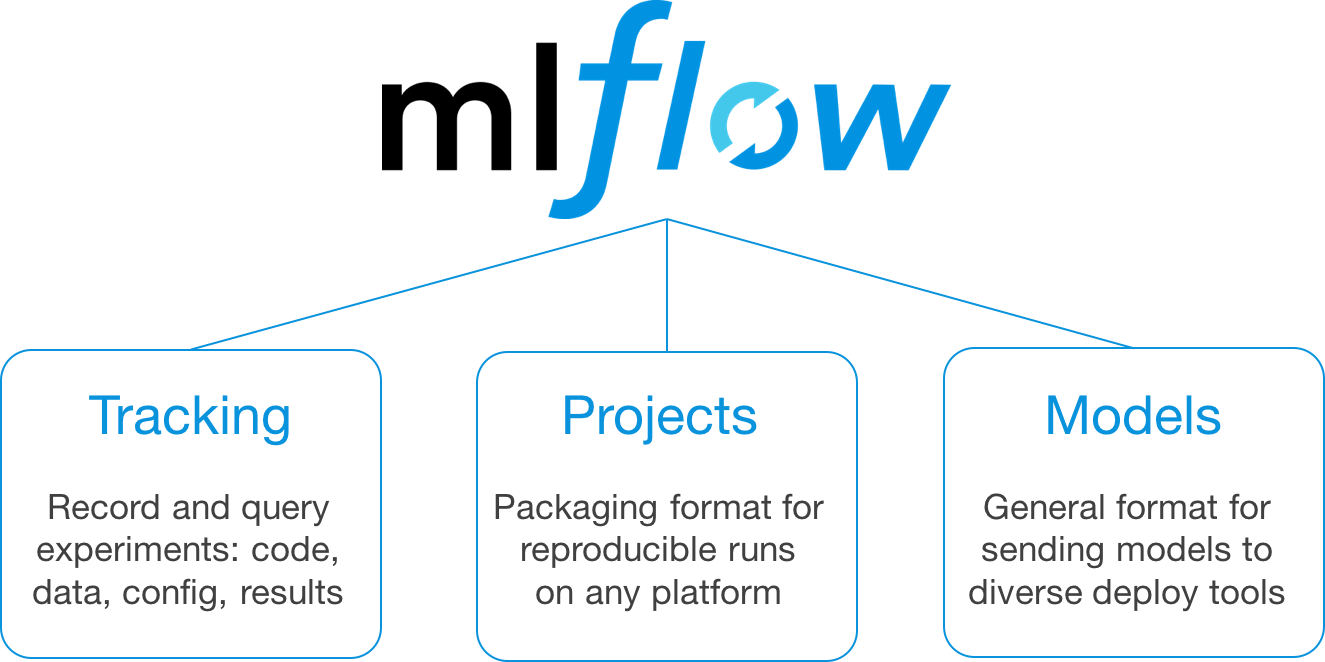
More information on each component can be found in the previous link as well as the link to the MLflow Documentation. The rest of this section gives a high-level overview of the features and implementation of each component.
Tracking
The Tracking component implements REST APIs and the UI for parameters, metrics, artifacts, and source logging and viewing. The back end is implemented with Flask and run on the gunicorn HTTP server while the UI is implemented with React.
The Python module for tracking is mlflow.tracking.
Each time users train a model on the machine learning platform, MLflow creates a Run and saves the RunInfo meta information onto a disk. Python APIs log parameters and metrics for a Run. The output of the run, such as the model, are saved in the artifacts for a Run. Each individual Run is grouped into an Experiment. The following class diagram shows classes that are defined in MLflow to support tracking functions.

The model training source code needs to call MLflow APIs to log the data to be tracked. For example, calling log_metric to log the metrics and log_param to log the parameters.
The MLflow tracking server currently uses a file system to persist all Experiment data. The directory structure looks like:
mlruns
bb b 0
bb b 7003d550294e4755a65569dd846a7ca6
b bb b artifacts
b b bb b test.txt
b bb b meta.yaml
b bb b metrics
b b bb b foo
b bb b params
b bb b param1
bb b meta.yaml
Every Run can be viewed through the UI browser that connects to the tracking server.

Users can search and filter models with metrics and params, and compare and retrieve model details.
Projects
The Projects component defines the specification on how to run the model training code. It includes the platform configuration, the dependencies, the source code, and the data that allow the model training to be executed through MLflow. The following code is an example provided by MLflow.
name: tutorial
conda_env: conda.yaml
entry_points:
main:
parameters:
alpha: float
l1_ratio: {type: float, default: 0.1}
command: "python train.py {alpha} {l1_ratio}"
The mlflow run command looks for the MLproject file for the spec and downloads the dependencies, if needed. It then runs the model training with the source code and the data specified in the MLproject.
mlflow run mlflow/example/tutorial -P alpha=0.4
The MLproject specifies the command to run the source code. Therefore, the source code can be in any language, including Python. Projects can be run on many machine learning platforms, including TensorFlow, PySpark, scikit-learn, and others. If the dependent Python packages are available to download by Anaconda, they can be added to the conda.yaml file and MLflow sets up the packages automatically.
Models
The Models component defines the general model format in the MLmodel file as follows:
artifact_path: model
flavors:
python_function:
data: model.pkl
loader_module: mlflow.sklearn
sklearn:
pickled_model: model.pkl
sklearn_version: 0.19.1
run_id: 0927ac17b2954dc0b4d944e6834817fd
utc_time_created: '2018-08-06 18:38:16.294557'
It specifies different flavors for different tools to deploy and load the model. This allows the model to be saved in its original binary persistence output from the platform training the model. For example, in scikit-learn, the model is serialized with the Python pickle package. The model can then be deployed to the environment that understands this format. With the sklearn flavor, if the environment has the scikit-learn installed, it can directly load the model and serve. Otherwise, with the python_function flavor, MLflow provides the mlflow.sklearn Python module as the helper to load the model.
So far, MLflow supports models load, save, and deployment with scikit-learn, TensorFlow, SageMaker, H2O, Azure, and Spark platforms.
With MLflow‘s modular design, the current Tracking, Projects, and Models components touch most parts of the machine learning lifecycle. You can also choose to use one component but not the others. With its REST APIs, these components can also be easily integrated into other machine learning workflows.
Experiencing MLflow
Installing MLflow is quick and easy if Anaconda has been installed and a virtual environment has been created. pip install mlflow installs the latest MLflow release.
To train the model with TensorFlow, run pip install tensorflow to install the latest version of TensorFlow.
A simple example to train a TensorFlow model with following code tf-example.py is:
import tensorflow as tf
from tensorflow import keras
import numpy as np
import mlflow
from mlflow import tracking
# load dataset
dataset = np.loadtxt("/Users/wzhuang/housing.csv", delimiter=",")
# save the data as artifact
mlflow.log_artifact("/Users/wzhuang/housing.csv")
# split the features and label
X = dataset[:, 0:15]
Y = dataset[:, 15]
# define the model
first_layer_dense = 64
second_layer_dense = 64
model = keras.Sequential([
keras.layers.Dense(first_layer_dense, activation=tf.nn.relu,
input_shape=(X.shape[1],)),
keras.layers.Dense(second_layer_dense, activation=tf.nn.relu),
keras.layers.Dense(1)
])
# log some parameters
mlflow.log_param("First_layer_dense", first_layer_dense)
mlflow.log_param("Second_layer_dense", second_layer_dense)
optimizer = tf.train.RMSPropOptimizer(0.001)
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae'])
# train
model.fit(X, Y, epochs=500, validation_split=0.2, verbose=0)
# log the model artifact
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)
mlflow.log_artifact("model.json")
The first call to the tracking API starts the tracking server and logs all of the data sent through the current and subsequent APIs. This logged data can then be viewed in the MLflow UI. From the previous example, it’s easy to just call the logging APIs in any place you want to track.
Packaging this project is also very simple by creating an MLproject file such as:
name: tf-example
conda_env: conda.yaml
entry_points:
main:
command: "python tf-example.py"
name: tf-example
channels:
- defaults
dependencies:
- python=3.6
- numpy=1.14.3
- pip:
- mlflow
- tensorflow
Then mlflow run tf-example runs the project on any environment. It first creates a conda environment with the required Python packages installed and then runs the tf-example.py inside that virtual environment. As expected, the run result is also logged to the MLflow tracking server.
MLflow also comes with a server implementation where the sklearn and other types of models can be deployed and served. The MLflow github README.md illustrates its usage. However, to deploy and serve the model built by the previous example requires new code that understands Keras models. This is beyond this blog’s scope.
To summarize, the experience with MLflow is smooth. There were several bugs here and there but overall I was satisfied with what the project claims to be. Of course, because MLflow is still in its alpha phase, bugs and the lack of some features are to be expected.
Areas where MLflow can be enhanced
MLflow provides an open source solution to track the data science processing, package, and deploy machine learning model. As it claims, it targets the management of the machine learning lifecycle. The current alpha version releases the Tracking, Projects, and Models components that tackle individual stages of the machine learning workflow. The tool is compact in Python language while providing APIs and a UI to be integrated easily with any machine learning platform.
However, there are still many places that MLflow can be improved. There are also new features that are required for the tool to fully manage and monitor all aspects of the lifecycle of machine learning.
At the databricks’ meetup on 07/19/2018, several items were mentioned in the longer-term road map of MLflow according to the presentation. There are four categories: improving current components, a new MLflow Data component, hyperparameter tuning, and language and library integrations. Some items are really important so they need more explanation.
Implementing a database back end for the Tracking component is included in the first category. As previously mentioned, the MLflow tracking server logs information for every run in the local file system. This looks like a quick and easy implementation. A better solution would be using a database as the tracking store. When the number of machine learning runs grows, databases have obvious advantages with data queries and retrieval.
Model metadata support is also included in the first category. This is extremely important. The current Tracking component does not describe the model, and all runs are viewed as a flatten list ordered by date. The tool allows the search based on the parameters and metrics, but it’s not enough. I would like to quickly retrieve the models by model name, algorithm, platform, and so on. This requires metadata input when a model training is tracked. The Tracking server logs the file name of the source code, but this does not provide any value in identifying a model. Instead, it should allow the input of a description of the model. Furthermore, the access control is also essential and can be part of the metadata. And model management should also have versioning support.
In the second category, MLflow will introduce a new Data component. It will build on top of Spark‘s Data Source API and allows projects to load data from many formats. This can be viewed as an effort to tighten the MLflow relationship with Spark. What should be done further is, of course, maintaining the metadata for the data.
In the fourth category, the integration with R and Java is also important. Although Python is one of the most adopted languages in machine learning, there are still many data scientists using R and other languages. MLflow needs to provide R and Java APIs so those machine learning workflows can be managed as well.
There are other important features not included in the current roadmap. From my viewpoint, the following list of items are also needed and can help complete MLflow as a full machine learning data and model management tool.
Register APIs
MLflow provides the APIs to log run information. These APIs must be called inside of the model training source code and they are called at runtime. This approach becomes inconvenient. You either want to track the previous runs without these APIs or runs without access to the source code. To solve this problem, a set of REST APIs that can be called after the run to register the run information would be very helpful. The run information, such as parameters, metrics, and artifacts, can be part of the JSON input.
UI view enhancement
In the
ExperimentsUI view, theParametersandMetricscolumns display all parameters and metrics for all runs. The row becomes unfriendly, long, and difficult to view when more types of parameters and metrics are tracked. Instead, for each run, the view should display a hyperlink to the detailed run info where the parameters and metrics are shown only for that run.Artifact location
MLflow can take artifacts from either local or GitHub. It would be a great improvement to support the load and save data, source code, and model from other sources like S3 Object Storage, HDFS, Nexus, and so on.
Import and export
After the tracking store is implemented with a database as the back end, the next thing will be to support the import and export of all experiments stored in different databases.
Run projects remotely
The
Projectscomponent specifies the command to run the project and the command is displayed in the tracking UI. But because the project can run only on the specific machine learning platform, which can be different from the tracking server, you still must connect to the platform remotely and issue the command line. TheMLprojectspecification should include the platform information such as the hostname and credentials. With this information, the tracking UI should add an action to kick off the run through the UI.Tuning
Adding the parameter tuning functionality through the tracking UI is an important feature. You will be allowed to change the parameters and kick off the run if the project is tracked by the
Projectscomponent.Common model format
The
Modelscomponent definesflavorsfor a model. However, every model is still stored in its original format only understood by that training tool. There is a gap between the model development and production. Portable Format for Analytics is a specification that can help bridge the gap.MLmodecan be improved to understand PFA or convert models into PFA for easy deploying models to PFA-enabled platforms.Pipeline integration
A complete machine learning lifecycle also includes data preparation and other pipelines. MLflow so far only tracks the training step. The
MLprojectcan be enhanced to include the specifications of other pipelines. Some pipelines can be shared by projects as well.
Summary
In this blog, I’ve described MLFlow and provided some specifics based on my experience in using the project. I’ve explained some features of MLflow and also provided suggestions on areas where I think MLflow can be improved.