
You Are (Probably) Here: Better Map Pins with DBSCAN & Random Forests
You Are (Probably) Here: Better Map Pins with DBSCAN & Random Forests
Users of Foursquare City Guide and Foursquare Swarm (in addition to users of the thousands of apps built by our API and data partners) routinely interact with our venues on a map. A map is the most natural backdrop against which to present geospatial data. Yet, the problem of determining where exactly to drop a venue’s map pin is a surprisingly difficult one. A common, but limiting, solution is to geocode a venue’s street address to a pair of latitude/longitude coordinates. At Foursquare, however, we have accumulated a massive location dataset that has allowed us to sidestep the geocoding approach altogether. In this post, we will describe how we harness the patterns inherent in user behavior to continually improve map pin placement over time.
Unbeholden to Geocoders
Geocoding venue addresses is not only expensive to do at scale, but also severely limited by the ability of geocoders to parse and error-correct a wide variety of international addresses. In addition, commercial geocoders’ address coverage and resolution vary widely across, and even within, countries. The point a geocoder returns could be the exact rooftop or doorstep coordinates in the best case, or an
A lot of place databases are essentially like “yellow pages” in that they contain basic information of the kind you might find listed in a business directory (or that you could call a place and get over the phone). Geocoding is often the only way that place records can be rendered on a map at scale. But at Foursquare, for every one of over twelve billion check-ins to date, we know where a user was physically located when they checked in at a specific venue.
From Filtering to Clustering
In the past, our approach to using these check-ins to place map pins was rather straightforward — for every venue, we simply computed the centroid of the latitude/longitude coordinates of its check-ins, and dropped the pin at that centroid. One problem with this approach is that GPS data is noisy, so not all check-ins are equal. Mobile phones report a horizontal accuracy along with latitude/longitude coordinates, where a numerically larger value corresponds to a higher error or lower confidence. When we noticed our centroids were thrown off by check-ins with large horizontal accuracy values, we naturally resorted to filtering them out, but that did not solve the entire problem either.
As we visualized check-ins at one venue after another, we noticed the underlying pattern in human behavior that generates check-ins staring right back at us. Most users check in when they’re physically inside a venue. But sometimes, they check in from the parking lot, or from across the street as they walk in or out. Less frequently, they might cheat at the Foursquare Swarm game and check in from somewhere else altogether in order to get coins, unlock stickers, or become mayor. We can usually detect fraudulent check-ins, but regardless, the key observation here is that check-ins are inherently clustered, with some outliers.
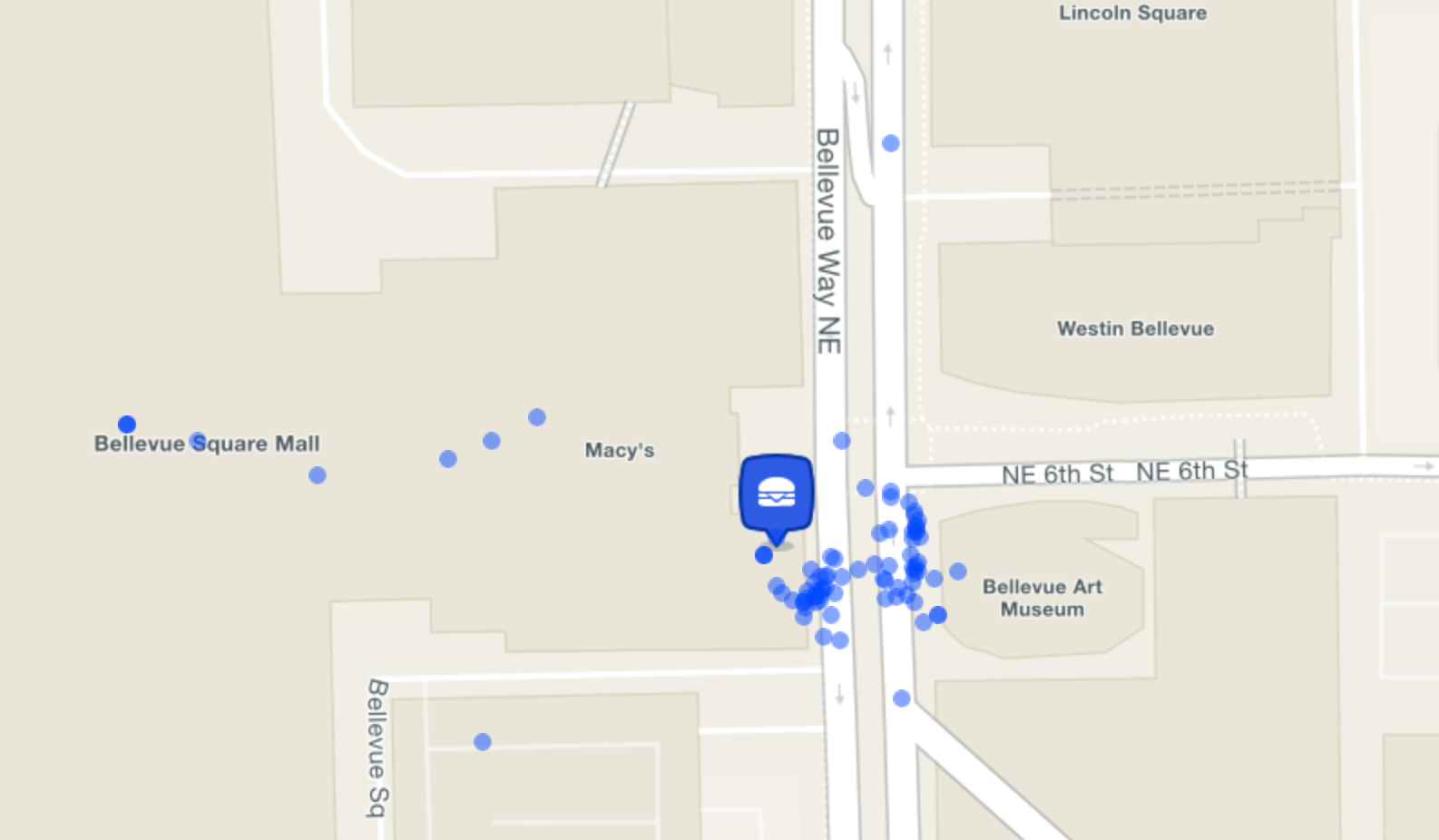
Our new approach, therefore, was to identify clusters in the check-ins, and use the centroid of just the “dominant,” or largest, cluster as the map pin location. Ideally, this cluster should consist of the check-ins that originated from inside the venue itself. There will typically be smaller clusters corresponding to legitimate check-ins from the parking lot or across the street. The rest are noise for our purposes.
Combining DBSCAN and Random Forests
Having reduced our situation to a flavor of clustering problem, our goal became to build a system that was robust to outliers and which made no assumptions about the size or shape of individual clusters or how many clusters there were in the data. We identified DBSCAN, a clustering algorithm that is well known and tested in the industry, as being an effective option for our purposes. DBSCAN (Density-Based Spatial Clustering of Applications with Noise) is a highly versatile algorithm, and, as the name suggests, it is particularly well suited to datasets that contain noise in a way that more popular clustering methods, such as k-means, are not. At its core, once again as its name suggests, DBSCAN is density-based, and especially when operating in two-dimensional space, the algorithm reflects the intuition by which our brains visually pick out clusters of points.
The DBSCAN algorithm takes two parameters, canonically referred to as MinPts and Eps. Without going into too much detail, MinPts is a number of neighboring points and Eps is a radius, and together, they intuitively describe the density criteria for points to form a cluster. The fact that there are only two parameters should technically make it easy to evaluate different models, but the catch is that the distribution of check-in densities in the real world varies greatly as a function of venue shape and size, which in turn are a function of category or chain, and location. So, the check-ins at a suburban Target look very different from the check-ins at a bar in Manhattan. There is no single value of MinPts and Eps that would work globally.