
Two years of Elixir at The Outline


Two years of Elixir at The Outline
Two years ago this month, I started as a developer at The Outline. At the time, the site was just an idea that existed as a series of design mock ups and small prototypes. We had just three months to build a news website with some pretty ambitious design goals, as well as a CMS to create the visually expressive content that the designs demanded. We chose Elixir and Phoenix as the foundation of our website after being attracted to its currency model, reliability, and ergonomics.
Over this time, I have gained a major appreciation for Elixir, not only for the productivity it affords me, but of the business opportunities it has opened up for us. In these past two years, Elixir has gone from 1.3 to 1.7, and great improvements have been introduced by the core team:
- GenStage / Flow
- mix format
- Registry
- Syntax highlighting
- IEx debugging enhancements
- Exception.Blame and other stack trace improvements
- Dynamic Supervisor
As I reach this two year mark, I thought others might benefit from an explanation of why I love Elixir so much after two years, what I still struggle with, and some beginner mistakes that I made early on.
Highlights
Elixir is really fast.
90ms is a 90th percentile response time on The Outline. Our post page route is even faster! We got this performance out of the box, without really any tuning or fine-grained optimizations. For other routes that do not hit the database, we see response times measures in microseconds. This speed allows us to build features that I wouldn’t have even considered possible in other languages.


Caching? Who needs it!
Elixir is so fast that we haven’t had much need for CDN or service level caching. It’s been a luxury to not have to spend time debugging caching issues between Redis and memcached, which are issues that have kept me up into the wee hours of the morning in past roles. The lack of public cache opens up the path for dynamic content and user-based personalization on initial page load.
While we don’t cache routes at the CDN, we do cache some expensive database queries. For that we use light in-memory caching via ConCache, a wonderful library by Saša Jurić.
Server render your HTML with Phoenix
It seems like people get started with Phoenix writing JSON apis, and leave the HTML to Preact and other front end frameworks. A lot of the raw site performance we get from Elixir and Phoenix is from its ability to render HTML extremely quickly, on the order of microseconds. Phoenix allows us to have really fast server-rendered pages, and then we let Javascript kick in to add dynamic features. Before reaching for Vue.js or Svelte, consider going old school and rendering your HTML on the server, you might be delighted.
ExUnit is great
ExUnit gives you so much out of the box. In most of the other languages that I’ve used, testing frameworks are third-party, and setup is often a pain. ExUnit comes bundled with a code coverage tool, and its assertion diffs keep improving! Not only that, you can mix test — slowest to find your slowest tests, or mix test — failed to rerun only the tests that failed the last run.
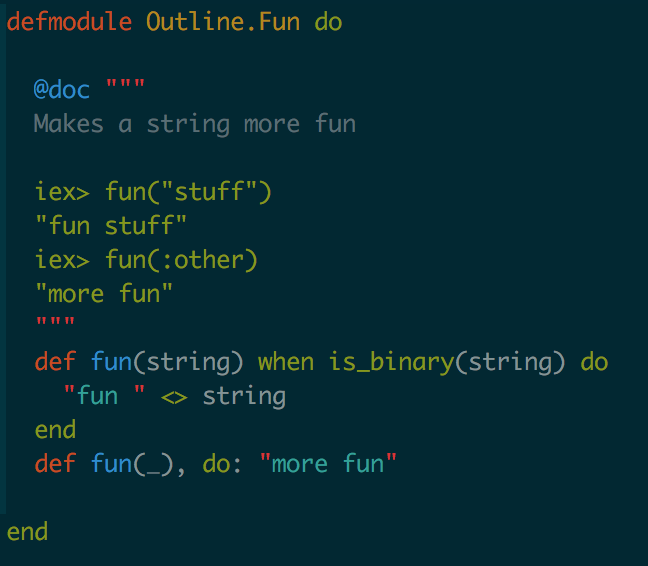
Doctests are easily my favorite part of ExUnit. For the uninitiated, doctests are tests that you write inline in your documentation. They get compiled and run when you do mix test. The power here is two-fold; you get code examples right next to the definition of your code and you know that the examples work.
First class documentation is something I take for granted
Having a consistent way to read docs across packages makes things really easy to find. I spent some time taking a data science and machine learning course in Python last month, and I realized exactly how spoiled I’ve been with Elixir documentation. It’s hard to measure the value that a consistent, familiar, and pervasive documentation system. The latest distillery release excepted, every Elixir library’s documentation has the same look and feel. My favorite part about Elixir documentation is the link right back to the source code. The way I usually read documentation is by trying to understand it through the text, and the if something isn’t clear I click the link to the source code and follow the code directly.
Phoenix Channels are such a great abstraction over WebSockets
Think of Phoenix Channels as controllers for Websockets. The socket registers topics which are analogous to a router. At The Outline, we were able to remove thousands of lines of JavaScript by moving code into the Channel. Moving mutable JavaScript into Elixir was a great feeling. It’s always been our goal to ship as little code to the client as possible, and keeping user state in Channels facilitates that in a way that I would not have considered if I was using Node.js or Ruby. The memory overhead of channels has been relatively low, and we didn’t need to make any changes to our infrastructure to support them.
The Community is wonderful!
Elixir has been a friendly and helpful community these past two years. I’ve received a ton of advice on the Elixir Slack channel when I’ve asked for help. I’ve also enjoyed attending at speaking at the NYC Elixir Meetup, as well as the Empex and Empex West conferences. I’ve met some great people through these events, including several leaders in the community, and I hope to meet more passionate people in the future!
I’d like to also call out both the ElixirTalk (hi Chris and Desmond) and Elixir Outlaws podcasts, which are fantastic and do a really great job of breaking down interesting problems in the ecosystem.
Things I still struggle with
Stack traces are not always the best
Sometimes you change a line in a controller or a view, and you end up with a stack trace in your 1000 line module that starts at line 1. The problem? Meta-programming! Despite all the great things that meta-programming gives us in terms of ergonomics, its makes certain types of exceptions really hard to pinpoint. Luckily, not all stack traces are this way, but it can be extremely frustrating when the stack trace leaves you empty handed.
Sometimes tests throw random warnings that I don’t know how to trace
Asynchronous and concurrent code is notoriously hard to debug. What’s harder to debug is asynchronous and concurrent code that you haven’t written. We have some lingering error messages that get printed during random test runs. Attempts to debug them have been futile, so they appear to be heisenbugs. I have a suspicion that our particular issue is with Phoenix Channels and Ecto Sandbox mode, but I haven’t quite narrowed it down. Please let me know if you have!
Working with Ecto Associations are still hard
While I’m really comfortable working with changesets and writing join queries in Ecto, breaking down my code for associations is still hard. Its pretty straightforward when dealing with simple associations, but when you have a data model that involves multiple entities, and you want to create new entities while associating them to existing entities, some things break down for me.
What I still does not feel natural to me is where to place code that deals withput_assoc and cast_assoc family of functions. My first tendency would be to put it in the changeset/2 function in the schema, but you do not always want that logic. Of course, you can have multiple changeset functions, but I haven’t found the right balance for that either. What I’ve started doing is moving association code outside of the schema and changeset, and into the bounded context thats building the association.
Beginner mistakes I made early on
Pattern matching all the things
What really drew me into Elixir at first was how wonderful it felt to pattern match in function heads. The utility of multiple function heads, if as an expression rather than a statement, and immutable data structures had me hooked really fast (especially coming from Javascript).
What ended up happening is that I would pattern match at every single opportunity. Without a static type system, pattern matching felt like a friendlier replacement, and I wanted to make use of it at every corner. The problem is that it’s not a type system, and using it as such has drawbacks that are not immediately obvious until you write a certain amount of Elixir code. When you pattern-match gratuitously, you over-specify your code, and you miss opportunities to apply generic code to wider domains, and make that code more difficult to refactor in the future.
While my love of pattern-matching has not gone away, it has become clearer to me when to pattern-match, and more importantly, what level of specificity should I pattern match on. Do I need to pattern-match on this struct, or will a map suffice? Does this private function need to pattern match it arguments when the shape is already clear in its only caller? These nuances become clearer as you write more code, and deciding when and when not to pattern-match is a matter of preference and style.
Trimming data too early in Phoenix Templates.
This is a problem that’s closely related with the desire to pattern-match. Once you start rendering more than the Hello World example of Phoenix, you’re gonna have to start passing data through nested views and templates to fully render a page. When you start passing data down, tend towards being additive rather than regressive.
# Here we’re possibly over pattern matching and over specifying.# If we want to pass more data down in the future, we have to# change this function in addition to its caller
def render(“parent.html”, %{content: content}) do render(“child.html”, %{content: content, extra: data})end# This way is less restrictive, and makes maintenance easier# in the future if we decide to pass more data
def render(“parent.html”, params) do render(“child.html”, Map.put(params, :extra, :data))end
You usually don’t need a GenServer!
When starting to learn about Elixir / Erlang, it’s so tempting to start writing GenServers, Tasks, processes, etc for the problem at hand. Before you do, please read Saša’s To spawn, or not to spawn?, which breaks down when you should reach for processes and when modules / functions are good enough.
Know when to leverage protocols
Knowing when to implement a protocol, such as Phoenix’s HTML.Safe protocol, can be extremely powerful. I wrote a bit about protocols in my last blog post, Beyond Functions in Elixir: Refactoring for Maintainability. In that post, I walk through implementing a custom Ecto.Type for Markdown, and then automatically converting it to HTML in your templates via protocols.
Not converting user data to well known shapes early enough
As soon as you get data from the external world, cast it into a well known shape. For this, Ecto.Changeset is your best friend. When I first started out, I resisted using changesets, as there is a bit of a learning curve, and it seemed easier to shove data right into the database. Don’t do this.
Ecto.Changeset is such a wonderful tool that will save you so much time, and there are many ways to learn it. I haven’t read the Ecto book, but I do recommend reading through the documentation as well as the free What’s new in Ecto 2.1?. José Valim also wrote an excellent blog post describing how to use Ecto Schemas and Changesets to map data between different domains, without those domains necessarily being backed by a database.
Things I’m interested in learning more about
- nerves — Craft and deploy bulletproof embedded software in Elixir
- raft — An Elixir implementation of the raft consensus protocol
- LiveView — Upcoming Phoenix compatible library from Chris McCord that blends Phoenix Channels and reactive html
Well, thank you for reading this far! These past two years have been a wonderful time. I’m excited to get more involved in the community, and to write more! Say hi on twitter https://twitter.com/davydog187 and let me know what else you’d like to hear about!