
The False Peril of Keras
The False Peril of Keras


What ever happened to hard work?
What ever happened writing your own activation function, and one-hotting your own variables. What does get_dummies() even do?
When I learned this trade — you hard coded each neuron in MatLab, wrangled your data by hand, and, by godm you would never use an algorithm you didn’t understand. I too, remember the days before XGBoost.
When I started working with machine learning practitioners nearly eight years ago now, Machine Learning in Java was still something that didn’t illicit snickers.
99% of the time now, when asked to solve a problem, these same folks now chose a blackbox model from Keras — and people like me declare the end times.
An Exclusionary Science
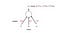
Machine Learning, at least for the first few decades of its existence, was a secret hidden in plain sight. As the basic tools of the trade (data wrangling, network building, and training regiments) were still far from commodities, the vast majority of work was centralized in a handful of labs.
If you were near Minsky or Papert, the places where DAPRA funding came easy, things were good back then. Most of your work was still theoretical, the relative lack of compute wasn’t a problem, as you were, in many ways, a mathematician.
Research outside of these centers was largely nonexistent — ideas were traded from lab to lab in an archaic language through the peer review process, code were rarely shared. You, as an individual contributor without a PHD had very little hope of getting access to their work, let alone understanding or contributing to it.
If I may be so brash, this was probably unavoidable. The internet was still nascent enough that the idea of transmitting research findings over something like arxiv or more radically in laymen's terms over a medium like twitter was a foreign thought. Additionally, much of the foundational math was hard enough that a PHD may have been needed to understand the never-ending stacks of symbols. Machine learning lived in its own silo.
However — not only did this silo limit those who could contribute, but also the scope of the problems that could be solved. As the craft of machine learning itself required an advanced degree, the hope solutions trickling into other disciplines was faint.
While sure, the vast majority of machine learning practitioners at this time could implement their own backpropagation algorithm, and whiteboard K-NN in a heartbeat — they were not prepared, on the whole, to solve truly meaningful problems.
The Case for Abstraction


In the mid-2000s this tide began to turn, with the introduction of Tensorflow, and soon after Keras — machine learning increasingly became commodified. Implementations of various architectures were now passed via documented python snippets, or even annotated Jupyter Notebooks, instead of dense publications.
What we are witnessing is the commodification of machine learning at an unprecedented rate. Additionally, as compute becomes cheaper and cheaper, generalized and unspecialized algorithms become increasingly powerful.
This is perhaps most evident if we look at growth at Google. As of 2012, deep learning at Google was concentrated entirely within Google Brain. In the short years since, it’s use within the company has grown exponentially, and it was being used in 1200+ different projects.
Now imagine what this impact looks like spread outside of Google, or even outside the bay. By accepting The best way we can help these people is by giving them the tools and knowledge to solve their own problems, using their own expertise and experience.
The further abstraction of libraries such as Keras are not destroying our work, but instead allowing its dissemination to those who can benefit most. For too long the ability to make impact with ML was a linear combination of domain expertise and obscure coding ability. Today, for the first time, we can leverage domain expertise alone.
And this is why I welcome Keras.

