
What I Learned Writing a Hacker News Clone
What I Learned Writing a Hacker News Clone


Earlier this month, I wrote an article titled “My Story as a Homeless Developer”. I received a ton of support from the community and connected with a lot of people who had experienced similar struggles before and also people who were going through those struggles currently. It was a great experience! I felt relieved to get my story out there and inspired to keep writing. I also was extremely motivated to keep growing as a developer.
Soon after publishing that article, I started making greater strides towards financial stability. I’m still figuring it out and I will get there but hope has been restored. The primary reason that article got as many views as it did, so quickly, is because of Hacker News. At the time of writing this, Hacker News accounted for 33k of the 70k views. Thirty-three thousand individuals that visit that site clicked on my post where I had shared the article and decided to read it.


The first thing I learned is that not everyone will shun you for sharing your story. A lot of users who visit Hacker News provided a ton of support. My LinkedIn profile filled up with kind wishes and advice. A few days after publishing the article, after the buzz had died down, I decided to be proactive in improving my skills and my portfolio. I had a ton of repositories in a variety of languages using many different frameworks and tools. The thing I was missing, was a solid example of an application that goes beyond the difficulty of those experiments. I needed to face a number of challenges to grow. Charging at these problems head-on would give me an idea of what I knew, what I didn’t know and what I needed to know.
So after a little bit of brainstorming, I decided to write a Hacker News clone. It seemed like a simple enough goal. The requirements were well-defined and I had done most of this before (or so I thought). I simply lacked the one portfolio piece that would put a lot of my skills into a single, easy-to-access, well written, nicely documented, completely tested, project. Some of those things aren’t currently there but I digress. I needed more of a challenge though, or so I thought. So I decided to use a language that I had just discovered.
That language is called Crystal. It’s a neat language that’s fairly new. It’s fast and it looks like Ruby. It’s statically-typed, general-purpose and open source. A new language, however, was not enough. It was similar to other languages I had used in the past. So, I wanted to include more functionality in the clone, that I considered useful because I thought that the clone, simply, was too easy.
This brings me to the real *first* thing that I learned.
Don’t aim *too* high, at first
I’m not saying you shouldn’t set goals that challenge you. You totally should aim for the stars, dream big and act on those dreams in an even bigger way. What I’m referring to, is design. To be more specific, like in my case, I learned that I could have benefited by splitting big goals into smaller goals. It’s a lesson I keep learning over and over and in different ways. If your problem is too big, split it up. If your codebase is cluttered, split it up (where it makes sense). If you are adding a ton of unrelated code, don’t have a single ‘commit’ with a vague ‘commit message’. I cannot stress how important it is to turn a challenge into smaller attainable challenges. This isn’t a one-size-fits-all philosophy to carry but it works when applied correctly.
In my case, I was facing new problems that I hadn’t solved before. I had used Crystal only for an application that was slightly more complicated than the “Hello, world!” tradition of programs. It was a new language and to make things harder, it was statically-typed and compiled. I had primarily been working with languages like Python, Lua, and PHP before. The language was the first obstacle.
The second obstacle was the framework. Crystal, being a newer language, had less established frameworks and documentation for those frameworks. I decided to use Kemal for my clone. It had functionality that was self-explanatory because of my experience with other frameworks. Some things weren’t so easy to figure out. It was difficult to find help with some issues in places where I’d normally look, such as Stack Overflow. In some cases, I actually had to dig through the source. To this day, after using it for many months professionally, I had never looked at any source of Flask, for example. For this project, I found myself looking at the source of an unfamiliar framework in an unfamiliar language.
The third and most challenging obstacle, which will be addressed better as time goes on, is the specific goals I had set for this project. To make my Hacker News clone more useful, I decided to add some functionality that I thought would be useful. You see, I had previous experience posting on Hacker News. I would link to things like projects of mine and get the analytical data that GitHub provides. I could link to a GitHub Page and write some functionality to track things such as views and activity on the site and in some cases, I even did that. But what about when your post was a question and didn’t link to anything external?
So with those thoughts in mind, I decided that my clone would give at *least* the view/click count for every post. I thought it would be awesome to challenge myself a bit more and make it so that this data is updated for users, live! How exciting! The “live” part was what turned this into a real challenge. It’s something that I am working on still. The project itself, at the time of this writing, is a rough proof-of-concept. It implements every feature that I decided to put into the “first-release bucket”. Besides updating views and click counts, live, for posts, I decided to make it so that comments on posts show up as they happen. I got it done but I learned that if I had set my goals a little bit lower and distributed them better in my todo-list, I could have written something better and skipped a step.
Releasing early-and-often though, as I seem to want to follow these days, is good. As quickly as I could, I implemented the features. You could log in, submit a post, sort the posts based on filters, interact with other users via comments, view profiles, and so on…
The fourth thing I learned is that migrations, models, views, API controllers, CSS styling as well as JavaScript to make this all smooth, piles up quickly. It can become a mess. I tried to break things out of the main source file when it made sense but I could have done so much better than that. If you are unfortunate enough to see the code as it is at the time of writing this, you will notice a few things. There’s a lot of code repetition, endpoints aren’t organized nor named in a way that makes codebase growth comfortable, and there are too many database queries going on. I’ll take this issue by issue and discuss the plans I’ve made to improve the application.
Code Repetition
When the project first started, it made sense to let a bad practice continue, until it became a problem. When I needed to check if a user was authenticated, I struggled for a few moments and then came up with a solution that was around three lines or so depending on the route. When I’d test the route, I’d be in a hurry to get to the next one so I could continue to check things off the list. I just wanted to release the thing even when I started on it. It was such a cool idea in my head and I wanted the world to see.


I should have followed DRY from the beginning. Don’t repeat yourself! I could have written middleware that did what I needed it to do and then simply applied it to the routes that needed the functionality (which ended up being most of them). That’s one of the first things I will be doing in the first refactor of this project. I probably should get a copy of The Pragmatic Programmer and actually finish reading it this time. The Wikipedia linked to from “DRY”, above”, states that it is formulated in the text by the authors of the book.
Endpoint naming and organization
Could you believe I’ve worked professionally before, writing APIs? REST is an architecture style I had sworn by as a new member on the team at Pioneer but it was something I had yet to fully realize in an application. On that team, I worked on small parts of a huge application. I stayed on those parts for the majority of my employment. With this project, I was writing it myself, from scratch.
A RESTful API, as stated on Wikipedia, should have a Uniform Interface.
It simplifies and decouples the architecture, which enables each part to evolve independently.
In this project’s codebase, the endpoints are defined in relevantly named source files. Registering and Logging Out are defined in “auth.cr”. What about logging in? You will find that functionality implemented inside of “user.cr”. When I refactor this part, I will likely organize all of those actions into parts of the “/user” endpoint. That’s because they all are doing something that is almost completely related to a “User”. I can break the code into more manageable chunks with more files in a concise folder-structure, too. I may have a folder “src/user/auth/” where I handled registering, logging in as well as logging-out a user.

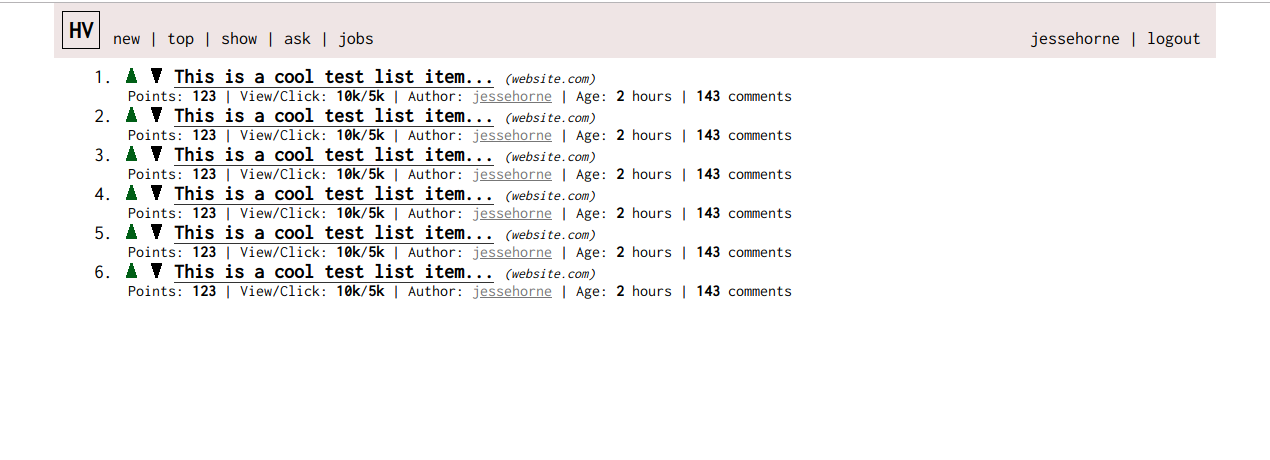
Too many queries
This is one of my first times having to put my thoughts on “scaling” into practice. At the time of writing this, there are too many queries going on. If there were a hundred users using this application, it would drive me crazy to know how many database queries were being made every few seconds. Currently, a client will refresh the view of posts every 10 seconds. Every time this happens, each post, in a loop, is determined to have been seen or not seen by the user. Each time it checks, it runs a query. It runs a query to fetch the posts (according to the current filter). This is a lot of work for the server.
Now, I will say that I do not have a ton of experience solving problems like this. So I can’t write on it too much, yet. Once I figure it out, I definitely plan on documenting my findings and hopefully helping others learn about my mistakes. I know that I can use a combination of Redis and MySQL or Postgres, even, to give queries a bit of extra speed (data would be stored in RAM at times where normally they would always be stored on the hard drive). For now, I will stop here.
The last part of this article is my asking for a little help. I would love to learn from people that have solved problems like these before. If you have suggestions on where I should begin my search, like a book, course, articles, or whatever, feel free to share. Whatever the feedback, on this article, the project, or whatever… Feel free to share! I encourage it!
I’d like to let people use this application as is and also see how it grows. I plan on doing a bit of refactoring with it. Having people with their own ideas and experience who are interested in the project would help in many, many ways. I’d be grateful and super excited to see interest from anyone! To get this hosted though requires funding that I do not currently have. If you read the article I linked to at the beginning of this post, you’d know I’m coming out of homelessness. I decided to toy with the idea of crowdfunding the costs of hosting. I set the goal to a reasonable but higher amount than what would likely be needed and the reasoning for that is explained on the GoFundMe page, linked below.
I appreciate your time reading this article and I hope that this has been valuable to someone out there. I’m still learning but my goal is to give back to the community in some way. This is a start, I think! I can’t wait to see what comes of this project.