
Google Cloud Spanner: the good, the bad and the ugly
Google Cloud Spanner: the good, the bad and the ugly


As a company that offers multiple cloud-based POS solutions to retailers, restaurateurs and ecommerce merchants around the globe, Lightspeed employs several different types of database platforms for a myriad of transactional, analytical and search use cases. Each of these database platforms have different strengths and weaknesses. So, when Google introduced Cloud Spanner to the market — promising features unheard-of in the space of relational databases, such as virtually unlimited
To provide a comprehensive overview of our hands-on evaluation of Cloud Spanner, as well as the evaluation criteria we used, we’ll cover these main topics:
- Our evaluation criteria
- Cloud Spanner in a nutshell
- Our evaluation
- Our final thoughts


1. Our evaluation criteria
Before delving into the specifics of Cloud Spanner and its similarities and differences with other solutions on the market, let’s talk about the principal use cases we had in mind when considering where to deploy Cloud Spanner within our infrastructure:
- As a replacement for a (predominant) traditional SQL database solution
- As an OLTP solution with Online Analytical Processing support
Note: For simplicity and ease of comparison, this article compares Cloud Spanner against MySQL variants of the GCP Cloud SQL and Amazon AWS RDS solution families.
Using Cloud Spanner as a replacement for a traditional SQL database solution
In a traditional database environment, when database query response times get close or even exceed pre-defined application thresholds (mostly due to an increase in the number of users and/or queries), there are several ways to bring response times down to acceptable levels. However, the majority of these solutions involve manual intervention.
For example, the first step one would initiate is to look at different performance related settings of the database and tweak them to best fit the applications’ use case patterns. If that proves insufficient, one may have the option to scale the database vertically or horizontally.
Vertically scaling an application entails upgrading the server instance, usually by adding more CPUs/cores, more RAM, faster storage, and so on. Adding more hardware resources translates into increased database performance, measured mostly in transactions per second and transaction latency for OLTP systems. Relational database systems (which benefit from a multithreading approach), such as MySQL, scale decently well vertically.
This approach has a few flaws, but the most obvious one is the maximum size of a server on the market. As soon as one reaches the limit of the biggest server instance, there is only one way to go: horizontal scaling.
Horizontal scaling is an approach where one adds more servers to the cluster, in order to ideally increase the performance linearly with the number of servers added. Most traditional database systems don’t scale well horizontally, or not at all. For example, MySQL can scale horizontally for read operations, by adding read slaves, but is unable to scale horizontally for write operations.
On the other hand, due to its nature, Cloud Spanner can easily scale horizontally with minimal intervention.
A fully featured RDBMS as a Service system needs to be evaluated from multiple angles. We took the most popular RDBMS on the cloud as our baseline — for Google, the GCP Cloud SQL and for Amazon, the AWS RDS. In our evaluation, we focused on the following areas:
- Feature match: the extent of the SQL, DDL, DML; connection libraries/connectors, transactional support, and so on.
- Development support: the ease of development and testing.
- Administration support: instance management — for example, scaling up/down and instance upgrades; SLA, backups and recovery; security/access control.
Using Cloud Spanner as an OLTP solution with Online Analytical Processing support
Although Google does not explicitly claim that Cloud Spanner is designed for analytical processing, it does share some attributes with other engines, such as Apache Impala & Kudu and YugaByte, which are designed for OLAP workloads.
Even if there was a only small chance that Cloud Spanner included a consistent horizontally scalable HTAP (Hybrid transactional/analytical processing) engine with a (somewhat) usable set of OLAP features, we felt it was worth looking into.
With that in mind, we looked at the following areas:
- Data loading, Partitioning support and Indexes
- Query and DML Performance
2. Cloud Spanner in a nutshell
Google Spanner is a clustered relational database management system (RDBMS) that Google uses for several of its own services. Google made it publicly available to Google Cloud Platform users in early 2017.
Here are some of Cloud Spanner’s attributes:
- Strongly consistent scale-out RDBMS cluster: uses hardware-assisted time synchronization to achieve data consistency.
- Cross-table transactional support: transactions can span across multiple tables — doesn’t have to be limited to a single table (unlike Apache HBase or Apache Kudu).
- Primary key design driven tables: all tables must have a declared primary key (PK), which can be composed of multiple table columns. Table data is stored in PK order, which makes it very efficient and fast for PK lookups. Like other PK-based systems, the implementation needs to be modeled with caution and target use cases in mind to achieve the best performance. (https://cloud.google.com/spanner/docs/schema-and-data-model)
- Interleaved tables: tables can have physical dependencies with each other. Rows of a child table can be collocated with rows of the parent table. This approach speeds up lookups of relations that can be defined in the data modeling phase — for example, collocation of customers and their invoices.
- Indexes: Cloud Spanner supports secondary indexes. An index consists of the indexed columns and all PK columns. Optionally, an index can also contain other non-indexed columns. An index can be interleaved with a parent table to speed up queries. Several limitations apply to indexes, like the maximum number of additional columns stored within the index. Also querying via indexes may not be as straightforward as in other RDBMSs.
“Cloud Spanner chooses an index automatically only in rare circumstances. In particular, Cloud Spanner does not automatically choose a secondary index if the query requests any columns that are not stored in the index.“https://cloud.google.com/spanner/docs/secondary-indexes
- Service Level Agreement (SLA): single region deployments with 99,99% SLA; multi-region deployments with 99.999% SLA. While SLA itself is just an agreement and not any kind of guarantee, I believe the folks at Google do have some hard data to make such a strong claim. (For reference, the 99.999% translates to 26.3 seconds of service unavailability per month.)
Note: The Apache Tephra project adds extended transactional support to Apache HBase (also implemented within Apache Phoenix in Beta now).
3. Our evaluation
Ok, so we’ve all read Google’s claims about Cloud Spanner’s advantages — almost limitless horizontal scaling while maintaining strong consistency and very high SLA. Although these claims, by any means, are an extremely hard thing to achieve, it was not the purpose of our evaluation to refute them. Instead, let’s focus on other things most database users are concerned with: feature parity & usability.
We evaluated Cloud Spanner as a drop-in Sharded MySQL replacement
Both Google Cloud SQL and Amazon AWS RDS, the two most popular OLTP DBMS on the cloud market, have very large feature sets. However, to scale out those databases beyond the size of one node, you need to do application sharding. This approach creates additional complexity on both application and administration fronts. We looked at how Spanner fits in the scenario of unifying multiple shards into a single instance and the features (if any) that may need to be sacrificed.
Support for SQL, DML, and DDL & Connector and Libraries?
Firstly, when starting with any database, one needs to create a data model. If you think that you can plug Spanner’s JDBC into your favourite SQL tool, you’ll discover that you can query your data with it but cannot use it to perform table creation or able alteration (DDL), or any insert/update/delete operations (DML). Google’s official JDBC supports neither.
“At present, the drivers do not support DML or DDL statements.”Spanner documentation
The situation isn’t any better with the GCP console, where you can submit only SELECT queries. Fortunately, there exists a community JDBC driver with the support of DML and DDL including transactions github.com/olavloite/spanner-jdbc. While this community driver is extremely valuable, the absence of Google’s own JDBC driver is surprising. Fortunately, Google is offering fairly broad support of client libraries (based on gRPC): C#, Go, Java, node.js, PHP, Python, and Ruby.
The almost mandatory use of Cloud Spanner’s custom APIs (due to the lack of DDL and DML in the JDBC) result in some limitations to related areas of the code, such as connection pools or database linking frameworks (for example, Spring MVC). Typically, while using JDBC, one has the liberty of grabbing a favourite connection pool (for example, HikariCP, DBCP, C3PO,…) that is production tested and performs well. In the case of Spanner’s custom APIs, we have to rely on connection/session pools/frameworks that we built in-house.
Primary-Key (PK) oriented design permits Cloud Spanner to be very fast when data is accessed via the PK, but also results in some query challenges.
- You can’t update the Primary Key value; you must first delete the record with the original PK and re-insert it with the new value. (This is similar in other PK driven databases/storage engines.)
- Any UPDATE and DELETE statement must specify a PK in the WHERE clause, hence there can’t be blank DELETE all statements, but there must always be a subquery — for example: UPDATE xxx WHERE id IN (SELECT id FROM table1)
- Lack of an Auto-increment option or anything similar that creates a sequence for the PK field. For this to work, a corresponding value would need to be created on the application side.
Secondary Indexes?
Google’s Cloud Spanner has built-in support for secondary indexes. This is a very nice feature not always present in other technologies. Apache Kudu currently doesn’t support secondary indexes at all and Apache HBase doesn’t support indexes directly, but can add them through Apache Phoenix.
It is possible to simulate indexes in Kudu and HBase as a separate table with a different composition of primary keys, but atomicity of operations made to the parent table and linked index-tables needs to be done at the application level, and is not trivial to implement properly.
As mentioned in the Cloud Spanner overview, its indexes may have a behavior different from MySQL indexes. So, extra caution should be put on query building and profiling, to ensure appropriate index use where intended.
Views?
A very popular and useful object in a database is views. They can be used for a large number of use cases; my two favorites are as a logical abstraction layer and as a security layer. Unfortunately, Cloud Spanner does NOT support views. This is particularly limiting since there is not a column level granularity for access permissions, where views can be a viable workaround.
In the Cloud Spanner documentation, in the section that details quotas and limitations (spanner/quotas), there is one, in particular, that may be troublesome for some applications: out of the box, Cloud Spanner has a limit of a maximum of 100 databases per instance. Obviously, this can be a major setback for a database that is designed to scale out beyond 100 databases. Fortunately, after talking to our Google technical contact, this limit can be increased to almost any value via Google support.
Development support?
Cloud Spanner offers fairly decent programming language support to operate with its APIs. Officially supported libraries are in C#, Go, Java, node.js, PHP, Python, and Ruby. The documentation is reasonably detailed, but similarly to other cutting-edge technologies, the community is quite small compared to the most popular database technologies, which may cause more time spent when less common use cases or issues needs to be addressed.
So, what about Local Development support?
We didn’t find a way to create a Cloud Spanner instance in a local environment. The closest we got was a docker image of CockroachDB, which is similar in principle, but very different in practice. For example, CockroachDB can use PostgreSQL JDBC. As it is imperative for a development environment to be as close a match as possible to production, Cloud Spanner is not ideal as one needs to rely on a full Spanner instance. To save costs you can select a single region instance.
Administration support?
The creation of a Cloud Spanner instance is very easy. One just needs to choose between creating a single region or a multi-region instance and specify the region(s) and the number of nodes. After less than a minute, the instance is up and running.
A few rudimentary metrics are directly available on the Spanner page in the Google console. More detailed views are available via Stackdriver, where you can also set up metric thresholds and alerting policies.
Resource Access?
MySQL offers vast and very granular user permissions/roles settings. One can easily set up access to a specific table or even just to a subset of its columns. Cloud Spanner uses Google’s Identity & Access Management (IAM) tool, which only allows the setting of policies and permissions on a very high level. The most granular option is a permission on a database level, which doesn’t fit a large chunk of production use cases. This limitation forces you to add extra security measures in your code, infrastructure or both, in order to mitigate unauthorized use of Spanner’s resources.
Backups?
Simply put, backups are non-existent in Cloud Spanner. While Google’s high SLA claims may guarantee you will not lose any data, due to hardware or database failures, there’s no coming back from human error, application defects, and so on. We all know the rule: high availability doesn’t replace a sound backup strategy. For now, the only way you can back up data is to programmatically stream them out of the database to a separate storage environment.
Query Performance?
For data loading and query testing, we used Yahoo! Cloud Serving Benchmark. The table below presents the YCSB workload B with a ratio of 95% read and 5% write.

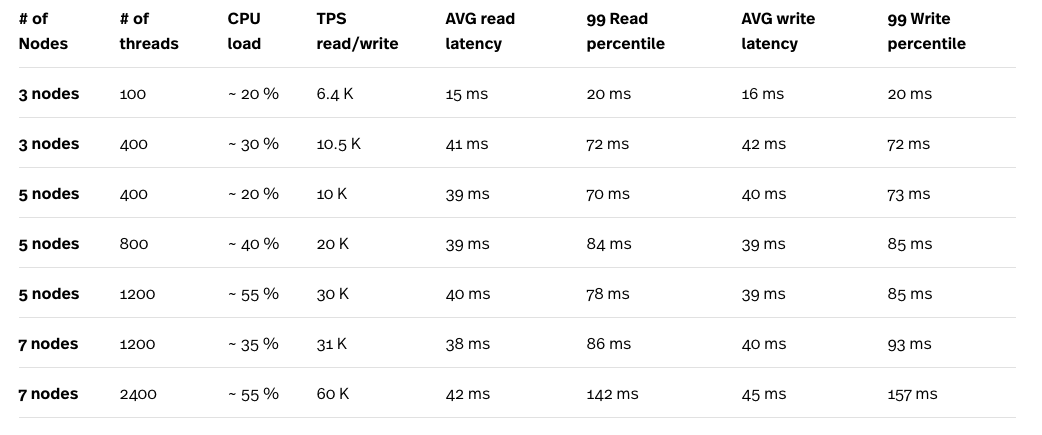
*The load test was running on a compute engine n1-standard-32 (32 vCPUs, 120 GB memory) and the test instance was never the bottleneck in the tests.
** The maximum number of threads within a single instance of YCSB is 400. Total of six parallel instances of YCSB benchmark had to be run to get the total of 2400 threads.
Looking at the benchmark results, particularly the combination of CPU load and TPS, we can clearly see that Cloud Spanner scales quite well. More load generated by more threads is compensated by more nodes in Cloud Spanner’s cluster. While the latency looks fairly high, especially when run with 2400 threads, to get more accurate numbers it may be worth re-testing with 6 smaller compute engine instances. Each instance would each run one YCSB benchmark instead of one big CE instance with 6 benchmarks in parallel. This way it may be easier to distinguish between Cloud Spanner query latencies, and the latency added by the network connection between Cloud Spanner and the CE instance running the benchmark.
How does Cloud Spanner perform as an OLAP?
Partitions?
Splitting data into physically and/or logically independent segments, called partitions, is a very popular concept inherent in most OLAP engines. Partitions can greatly improve query performance and database maintainability. Delving further into partitions would be an article(s) on its own, so let’s just mention the importance of having a partitioning and sub-partitioning scheme. The ability to split data into partitions and even further into sub-partitions is key to the performance of analytical queries.
Cloud Spanner doesn’t support partitions per-se. It divides data internally into splits based on the primary key ranges. The splitting is done automatically to balance the load across the Cloud Spanner cluster. A very handy Cloud Spanner feature, is load base splitting of the parent table (the table that is not interleaved with another). Spanner automatically detects if a split contains data that is read more frequently then the data in other splits and may decide to further split it. This way more nodes can be involved in the querying and this effectively also increases bandwidth.
Data Loading?
Cloud Spanner’s way to bulk data is the same as a normal load. To achieve maximum performance you’ll need to follow some best practices, including:
- Sort your data by primary key.
- Divide it into 10 *number of nodes separate sections.
- Create a set of worker tasks that upload the data in parallel.
Loading data this way makes use of all of Cloud Spanner nodes.
We used the YCSB workload A to generate a 10M rows data set.

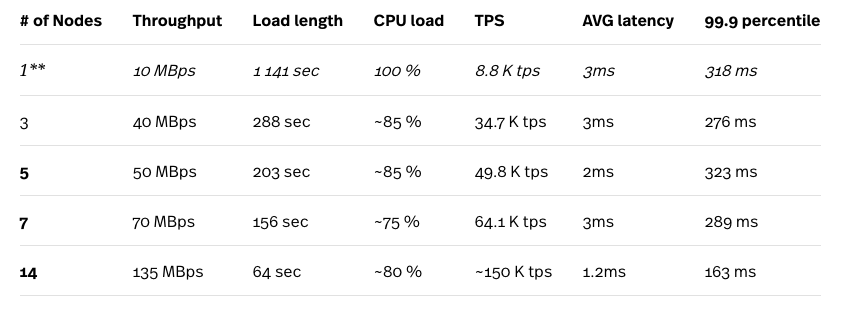
* The load test was running on a compute engine n1-standard-32 (32 vCPUs, 120 GB memory) and the test instance was never the bottleneck in the tests.
** 1-node setup is not recommended for any production load.
As mentioned above, Cloud Spanner automatically handles the splits based on their loads, so the results improved after several consecutive reruns of the test. The results presented here are the best results we obtained. Looking at the numbers above we can see how Cloud Spanner scales (well) with the increased number of nodes in the cluster. The numbers that stand out are the extremely low average latencies which are in contrast with results of mixed workloads (95% read 5% write), as described in the section above.
Scaling?
Scaling up and down the number of Cloud Spanner nodes is a one-click task. If you want to quickly load data, you may consider boosting the instance to the maximum (in our case it was 25 nodes in the US-EAST region) and then scale down to the number of nodes suitable for your usual load, once the data is in the database, while keeping in mind the 2TB/node limit.
We were reminded of this limit even with a much smaller database. After several runs of load tests, our database was about 155GB and when scaling down to 1 node instance we received the following error:

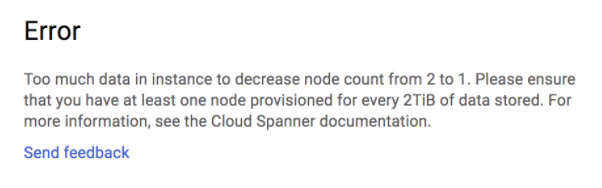
We managed to downscale from 25 to 2 instances, but were stuck with the 2 nodes.
Scaling up and down the number of nodes in a Cloud Spanner cluster can be automated through its REST API. This can be particularly useful to alleviate increased load on the system during busy hours.
OLAP query performance?
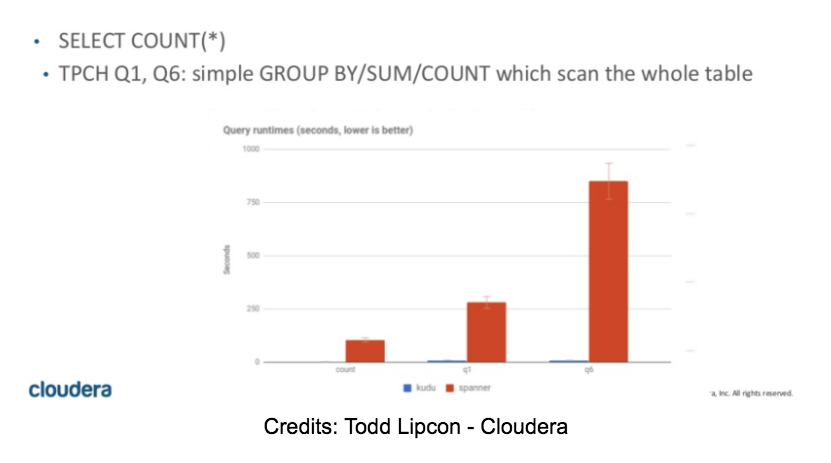
Initially, we planned to put a significant amount of time into this part of our Spanner evaluation. After just a few SELECT COUNTs, we immediately knew that the benchmarking would be short and that Spanner is NOT an OLAP suitable engine. No matter the number of nodes in the cluster, a simple selection of a number of rows on a 10M row table took between 55 to 60 seconds. Additionally, any query that required a bigger amount of memory to store intermediate results failed with an OOM error.
SELECT COUNT(DISTINCT(field0)) FROM usertable; — (10M distinct values)-> SpoolingHashAggregateIterator ran out of memory during new row.
Some numbers for TPC-H queries can be found in Todd Lipcon’s article Nosql-kudu-spanner-slides.html, slides 42 & 43. The numbers are consistent with our own findings (unfortunately).

4. Our final thoughts
With the current state of Cloud Spanner features, it’s hard to think of it as an easy replacement for an existing OLTP solution, especially once your needs outgrow it. One would have to invest a significant amount of time to build a solution around Cloud Spanner’s shortcomings.
When we started the Cloud Spanner evaluation, we expected its management features to be on par with, or at least not so far from, other Google SQL solutions. But, we were surprised by the complete lack of backups and very limited resource access control. Not to mention its lack of views, no local development environment, unsupported sequences, JDBC without DML and DDL support, and so on.
So, where does this leave someone who needs to scale-out a transactional database? There doesn’t yet seem to be one solution on the market that fits all use cases. There are plenty of closed and open source solutions (a few of which are mentioned in this article), each with its strengths and weaknesses, but none of them offer SaaS with 99.999% SLA and strong consistency. If high SLA is your primary objective and you’re not inclined to build your own multi-cloud solution, Cloud Spanner may be the solution you are looking for. But, you should be aware of all of its limitations.
To be fair, Cloud Spanner was only released for general availability in the Spring of 2017, so it’s reasonable to expect that some of its current shortcomings may eventually disappear (hopefully) and when that happens, it may be a game changer. After all, Cloud Spanner is not just a side project for Google. Google uses it as the backbone for other Google products. And when Google recently replaced Megastore on Google Cloud Storage with Cloud Spanner, it allowed Google Cloud Storage to become strongly consistent for object listing on a world-wide scale (which is still not the case for Amazon’s S3).
So, there’s still hope…we hope.