
HumL: Better Text Intelligence with Humans in the Loop
HumL: Better Text Intelligence with Humans in the Loop


In his recent book Deep Thinking, former chess world champion Garry Kasparov reflects on his second match against IBM Deep Blue as a way to present some provocative ideas about the artificial intelligence(AI) space. As he develops his ideas, Kasparov concludes that the immediate future of AI systems is going to be based on human-machine collaboration models that combine the deep analytical capabilities of AI systems with undecipherable human cognition skills such as intuition and common sense. Despite the advances in AI methods, most effective AI systems today require a high degree of human supervision. However, the human component is often seen as an external factor to the AI architecture. Recently, researchers from the
Dictionaries and ontologies are an important of many artificial intelligence(AI) systems particularly in the natural language processing(NLP) space. Typically, we build dictionaries to guide algorithms to recognize the correct patterns in unstructured text. However, keeping dictionaries up to date is far from being an easy endeavor and very often fall out of sync as new content arrives. To address this challenge, IBM proposed a technique that employs a lightweight neural language model coupled with tight human supervision to assist the user in building and maintaining a domain-specific dictionary from an input text corpus. They called this approach human-in-the-loop(HumL) and is based on a classic deep learning technique known as the explore/exploit paradigm.
HumL
The HumL model operates using an input composed of a text corpus and a specific set of dictionary seed-examples. The model has two main phases: explore and exploit. The explore phase tries to identify similar instances to the dictionary entries that are present in the input text corpus, using term vectors from the neural language model to calculate a similarity score. The exploit phase tries to construct more complex multi-term phrases based on the instances already in the input dictionary.
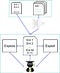
Explore
As explained previously, the goal of the explore phase is to uses the instances available in the input dictionary to identify similar candidates that are already present in the corpus vocabulary. Specifically, the IBM team relied on the word2vec algorithm to detect similarities between entries in the dictionary and the text corpus. Conceptually, semantically similar words should appear close to each other in the feature space. Therefore, the problem of calculating the similarity between two instances is a matter of calculating the distance between two instances in the given feature space. HumL uses the standard cosine similarity measure which is applied on the vectors of the instances.
Exploit
The exploit phase tries to identify more complex phrases that don’t exist in the corpus vocabulary by analyzing the structure of the instances in the input dictionary. HumL accomplishes that using two phrase generation algorithms:
1) The first algorithm modifies the phrases by replacing single terms with similar terms from the text corpus, e.g., “abnormal behavior” can be modified to “strange behavior”;
2) The second algorithm extends the instances with terms from the text corpus that are related to the terms in the instance, e.g., “abnormal blood clotting problems” may not appear in a large text corpus, but “abnormal blood count”, “blood clotting” and “clotting problems” appear several times in the corpus and can be used to build the more complex instance.
HumL in Action
The IBM team evaluated HumL on different text analytic scenarios particularly in the health care field. One of the test scenarios tackle the problem of identifying adversed drug reactions in user generated data. As input, the system used a text corpus from the http://askapatient.com that blog posts describing patient experiences with different medication drugs. HumL used an evaluation process divided in 10 iterations, where after each iteration counted how many new instances are discovered in the top 50 proposed candidates by the algorithm. The accepted instances are then added in the dictionary and used for the next iteration.

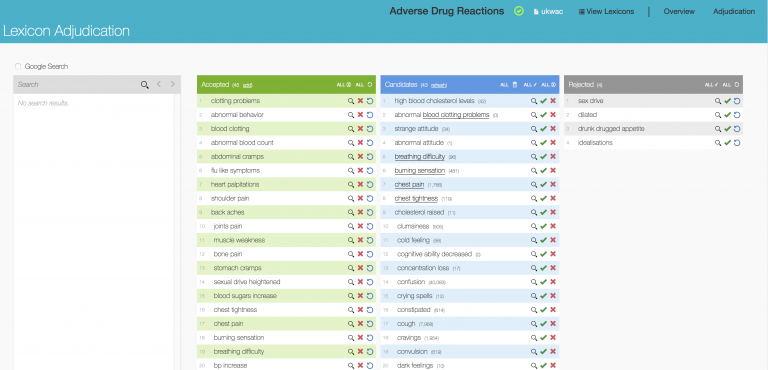
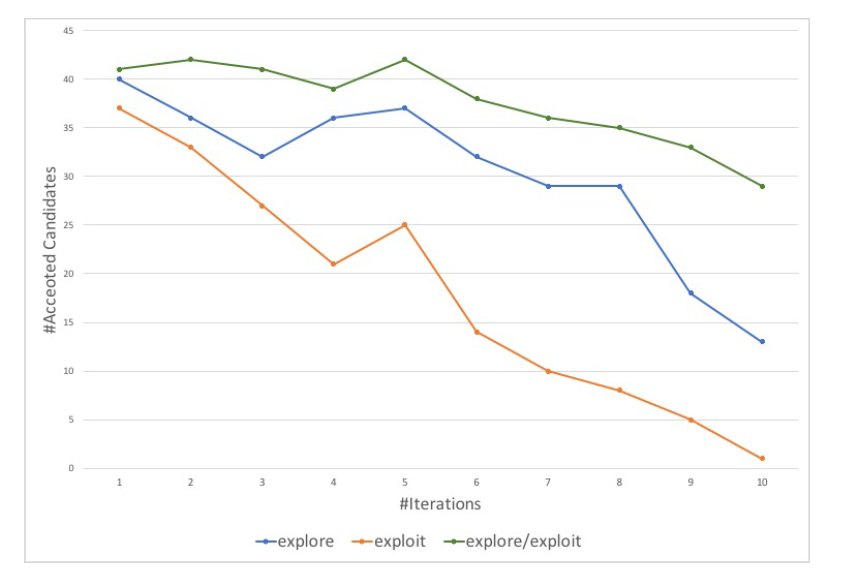
The results showed that using the explore/exploit approach we are able to discover significantly more instances in each iteration compared to the other approaches. Another interesting observation is that using the explore approach the number of newly discovered instances quickly decreases as the number of available instances in the whole corpus is decreasing in each iteration.

The HumL research showed that incorporating human feedback in text analytic algorithms can yield significant performance improvements. This result is more remarkable if we consider that HumL used a very basic statistical approach that didn’t require much more than simple tokenization. We should expect to see more sophisticated versions of the HumL models using advanced architectures such as Recurrent Neural Networks (RNN), Long Short Term Memory Networks (LSTM), and bidirectional LSTM.