
Python Program Lexical Structure
You have now covered Python variables, operators, and data types in depth, and you’ve seen quite a bit of example code. Up to now, the code has consisted of short individual statements, simply assigning objects to variables or displaying values.
But you want to do more than just define data and display it! Let’s start arranging code into more complex groupings.
Here’s what you’ll learn in this tutorial: You’ll dig deeper into Python lexical structure. You’ll learn about the syntactic elements that comprise statements, the basic units that make up a Python program. This will prepare you for the next few tutorials covering control structures, constructs that direct program flow among different groups of code.
Take the Quiz: Test your knowledge with our interactive “Python Program Structure” quiz. Upon completion you will receive a score so you can track your learning progress over time.
Python Statements
Statements are the basic units of instruction that the Python interpreter parses and processes. In general, the interpreter executes statements sequentially, one after the next as it encounters them. (You will see in the next tutorial on conditional statements that it is possible to alter this behavior.)
In a REPL session, statements are executed as they are typed in, until the interpreter is terminated. When you execute a script file, the interpreter reads statements from the file and executes them until end-of-file is encountered.
Python programs are typically organized with one statement per line. In other words, each statement occupies a single line, with the end of the statement delimited by the newline character that marks the end of the line. The majority of the examples so far in this tutorial series have followed this pattern:
>>>>>> print('Hello, World!') Hello, World! >>> x = [1, 2, 3] >>> print(x[1:2]) [2]
Note: In many of the REPL examples you have seen, a statement has often simply consisted of an expression typed directly at the >>> prompt, for which the interpreter dutifully displays the value:
>>> 'foobar'[2:5] 'oba'
Remember that this only works interactively, not from a script file. In a script file, a literal or expression that appears as a solitary statement like the above will not cause output to the console. In fact, it won’t do anything useful at all. Python will simply waste CPU time calculating the value of the expression, and then throw it away.
Line Continuation
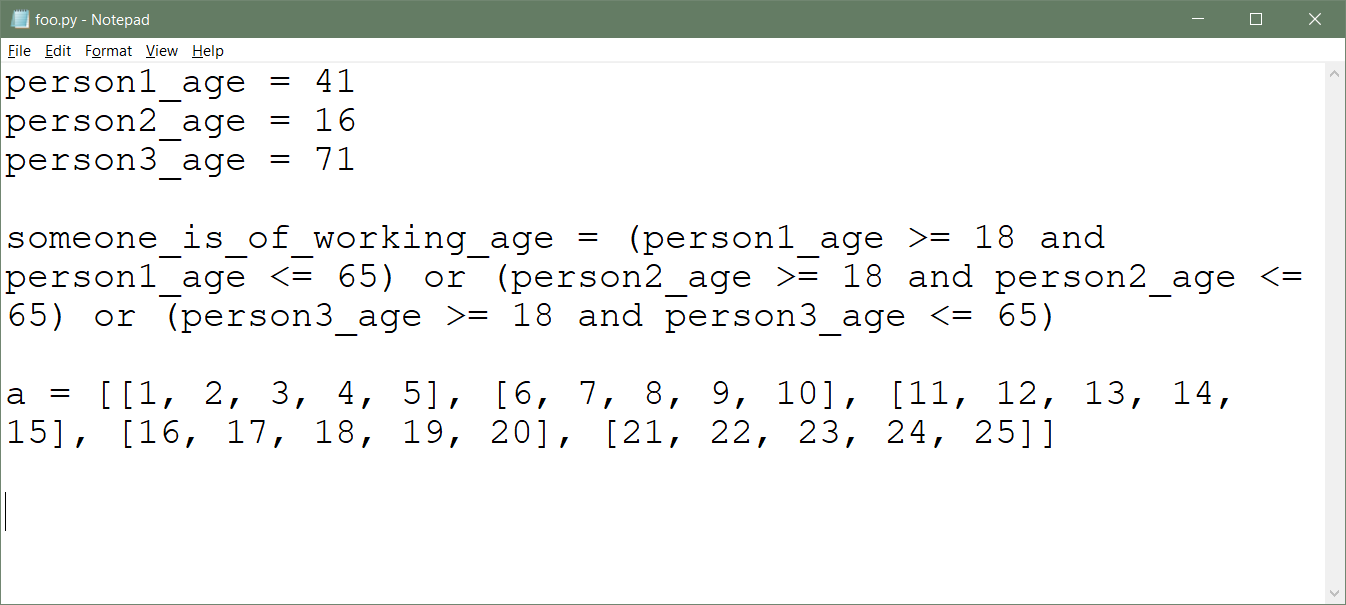
Suppose a single statement in your Python code is especially long. For example, you may have an assignment statement with many terms:
>>>>>> person1_age = 42 >>> person2_age = 16 >>> person3_age = 71 >>> someone_is_of_working_age = (person1_age >= 18 and person1_age <= 65) or (person2_age >= 18 and person2_age <= 65) or (person3_age >= 18 and person3_age <= 65) >>> someone_is_of_working_age True
Or perhaps you are defining a lengthy nested list:
>>>>>> a = [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15], [16, 17, 18, 19, 20], [21, 22, 23, 24, 25]] >>> a [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15], [16, 17, 18, 19, 20], [21, 22, 23, 24, 25]]
You’ll notice that these statements are too long to fit in your browser window, and the browser is forced to render the code blocks with horizontal scroll bars. You may find that irritating. (You have our apologies—these examples are presented that way to make the point. It won’t happen again.)
It is equally frustrating when lengthy statements like these are contained in a script file. Most editors can be configured to wrap text, so that the ends of long lines are at least visible and don’t disappear out the right edge of the editor window. But the wrapping doesn’t necessarily occur in logical locations that enhance readability:
Excessively long lines of code are generally considered poor practice. In fact, there is an official Style Guide for Python Code put forth by the Python Software Foundation, and one of its stipulations is that the maximum line length in Python code should be 79 characters.
Note: The Style Guide for Python Code is also referred to as PEP 8. PEP stands for Python Enhancement Proposal. PEPs are documents that contain details about features, standards, design issues, general guidelines, and information relating to Python. For more information, see the Python Software Foundation Index of PEPs.
As code becomes more complex, statements will on occasion unavoidably grow long. To maintain readability, you should break them up into parts across several lines. But you can’t just split a statement whenever and wherever you like. Unless told otherwise, the interpreter assumes that a newline character terminates a statement. If the statement isn’t syntactically correct at that point, an exception is raised:
>>>>>> someone_is_of_working_age = person1_age >= 18 and person1_age <= 65 or SyntaxError: invalid syntax
In Python code, a statement can be continued from one line to the next in two different ways: implicit and explicit line continuation.
Implicit Line Continuation
This is the more straightforward technique for line continuation, and the one that is preferred according to PEP 8.
Any statement containing opening parentheses ('('), brackets ('['), or curly braces ('{') is presumed to be incomplete until all matching parentheses, brackets, and braces have been encountered. Until then, the statement can be implicitly continued across lines without raising an error.
For example, the nested list definition from above can be made much more readable using implicit line continuation because of the open brackets:
>>>>>> a = [ ... [1, 2, 3, 4, 5], ... [6, 7, 8, 9, 10], ... [11, 12, 13, 14, 15], ... [16, 17, 18, 19, 20], ... [21, 22, 23, 24, 25] ... ] >>> a [[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15], [16, 17, 18, 19, 20], [21, 22, 23, 24, 25]]
A long expression can also be continued across multiple lines by wrapping it in grouping parentheses. PEP 8 explicitly advocates using parentheses in this manner when appropriate:
>>>>>> someone_is_of_working_age = ( ... (person1_age >= 18 and person1_age <= 65) ... or (person2_age >= 18 and person2_age <= 65) ... or (person3_age >= 18 and person3_age <= 65) ... ) >>> someone_is_of_working_age True
If you need to continue a statement across multiple lines, it is usually possible to use implicit line continuation to do so. This is because parentheses, brackets, and curly braces appear so frequently in Python syntax:
Parentheses
-
Expression grouping
>>>>>> x = ( ... 1 + 2 ... + 3 + 4 ... + 5 + 6 ... ) >>> x 21
-
Function call
>>>>>> print( ... 'foo', ... 'bar', ... 'baz' ... ) foo bar baz
-
Method call
>>>>>> 'abc'.center( ... 9, ... '-' ... ) '---abc---'
-
Tuple definition
>>>>>> t = ( ... 'a', 'b', ... 'c', 'd' ... )
Curly Braces
-
Dictionary definition
>>>>>> d = { ... 'a': 1, ... 'b': 2 ... }
-
Set definition
>>>>>> x1 = { ... 'foo', ... 'bar', ... 'baz' ... }
Square Brackets
-
List definition
>>>>>> a = [ ... 'foo', 'bar', ... 'baz', 'qux' ... ]
-
Indexing
>>>>>> a[ ... 1 ... ] 'bar'
-
Slicing
>>>>>> a[ ... 1:2 ... ] ['bar']
-
Dictionary key reference
>>>>>> d[ ... 'b' ... ] 2
Note: Just because something is syntactically allowed, it doesn’t mean you should do it. Some of the examples above would not typically be recommended. Splitting indexing, slicing, or dictionary key reference across lines, in particular, would be unusual. But you can consider it if you can make a good argument that it enhances readability.
Remember that if there are multiple parentheses, brackets, or curly braces, then implicit line continuation is in effect until they are all closed:
>>>>>> a = [ ... [ ... ['foo', 'bar'], ... [1, 2, 3] ... ], ... {1, 3, 5}, ... { ... 'a': 1, ... 'b': 2 ... } ... ] >>> a [[['foo', 'bar'], [1, 2, 3]], {1, 3, 5}, {'a': 1, 'b': 2}]
Note how line continuation and judicious use of indentation can be used to clarify the nested structure of the list.
Explicit Line Continuation
In cases where implicit line continuation is not readily available or practicable, there is another option. This is referred to as explicit line continuation or explicit line joining.
Ordinarily, a newline character (which you get when you press Enter on your keyboard) indicates the end of a line. If the statement is not complete by that point, Python will raise a SyntaxError exception:
>>> s = File "<stdin>", line 1 s = ^ SyntaxError: invalid syntax >>> x = 1 + 2 + File "<stdin>", line 1 x = 1 + 2 + ^ SyntaxError: invalid syntax
To indicate explicit line continuation, you can specify a backslash (\) character as the final character on the line. In that case, Python ignores the following newline, and the statement is effectively continued on next line:
>>> s = \ ... 'Hello, World!' >>> s 'Hello, World!' >>> x = 1 + 2 \ ... + 3 + 4 \ ... + 5 + 6 >>> x 21
Note that the backslash character must be the last character on the line. Not even whitespace is allowed after it:
>>>>>> # You can't see it, but there is a space character following the \ here: >>> s = \ File "<stdin>", line 1 s = \ ^ SyntaxError: unexpected character after line continuation character
Again, PEP 8 recommends using explicit line continuation only when implicit line continuation is not feasible.
Multiple Statements Per Line
Multiple statements may occur on one line, if they are separated by a semicolon (;) character:
>>> x = 1; y = 2; z = 3 >>> print(x); print(y); print(z) 1 2 3
Stylistically, this is generally frowned upon, and PEP 8 expressly discourages it. There might be situations where it improves readability, but it usually doesn’t. In fact, it often isn’t necessary. The following statements are functionally equivalent to the example above, but would be considered more typical Python code:
>>>>>> x, y, z = 1, 2, 3 >>> print(x, y, z, sep='\n') 1 2 3
The term Pythonic refers to code that adheres to generally accepted common guidelines for readability and “best” use of idiomatic Python. When someone says code is not Pythonic, they are implying that it does not express the programmer’s intent as well as might otherwise be done in Python. Thus, the code is probably not as readable as it could be to someone who is fluent in Python.
If you find your code has multiple statements on a line, there is probably a more Pythonic way to write it. But again, if you think it’s appropriate or enhances readability, you should feel free to do it.
Comments
In Python, the hash character (#) signifies a comment. The interpreter will ignore everything from the hash character through the end of that line:
>>> a = ['foo', 'bar', 'baz'] # I am a comment. >>> a ['foo', 'bar', 'baz']
If the first non-whitespace character on the line is a hash, the entire line is effectively ignored:
>>>>>> # I am a comment. >>> # I am too.
Naturally, a hash character inside a string literal is protected, and does not indicate a comment:
>>>>>> a = 'foobar # I am *not* a comment.' >>> a 'foobar # I am *not* a comment.'
A comment is just ignored, so what purpose does it serve? Comments give you a way to attach explanatory detail to your code:
>>>>>> # Calculate and display the area of a circle. >>> pi = 3.1415926536 >>> r = 12.35 >>> area = pi * (r ** 2) >>> print('The area of a circle with radius', r, 'is', area) The area of a circle with radius 12.35 is 479.163565508706
Up to now, your Python coding has consisted mostly of short, isolated REPL sessions. In that setting, the need for comments is pretty minimal. Eventually, you will develop larger applications contained across multiple script files, and comments will become increasingly important.
Good commenting makes the intent of your code clear at a glance when someone else reads it, or even when you yourself read it. Ideally, you should strive to write code that is as clear, concise, and self-explanatory as possible. But there will be times that you will make design or implementation decisions that are not readily obvious from the code itself. That is where commenting comes in. Good code explains how; good comments explain why.
Comments can be included within implicit line continuation:
>>>>>> x = (1 + 2 # I am a comment. ... + 3 + 4 # Me too. ... + 5 + 6) >>> x 21 >>> a = [ ... 'foo', 'bar', # Me three. ... 'baz', 'qux' ... ] >>> a ['foo', 'bar', 'baz', 'qux']
But recall that explicit line continuation requires the backslash character to be the last character on the line. Thus, a comment can’t follow afterward:
>>>>>> x = 1 + 2 + \ # I wish to be comment, but I'm not. SyntaxError: unexpected character after line continuation character
What if you want to add a comment that is several lines long? Many programming languages provide a syntax for multiline comments (also called block comments). For example, in C and Java, comments are delimited by the tokens /* and */. The text contained within those delimiters can span multiple lines:
/* [This is not Python!] Initialize the value for radius of circle. Then calculate the area of the circle and display the result to the console. */
Python doesn’t explicitly provide anything analogous to this for creating multiline block comments. To create a block comment, you would usually just begin each line with a hash character:
>>>>>> # Initialize value for radius of circle. >>> # >>> # Then calculate the area of the circle >>> # and display the result to the console. >>> pi = 3.1415926536 >>> r = 12.35 >>> area = pi * (r ** 2) >>> print('The area of a circle with radius', r, 'is', area) The area of a circle with radius 12.35 is 479.163565508706
However, for code in a script file, there is technically an alternative.
You saw above that when the interpreter parses code in a script file, it ignores a string literal (or any literal, for that matter) if it appears as statement by itself. More precisely, a literal isn’t ignored entirely: the interpreter sees it and parses it, but doesn’t do anything with it. Thus, a string literal on a line by itself can serve as a comment. Since a triple-quoted string can span multiple lines, it can effectively function as a multiline comment.
Consider this script file foo.py:
"""Initialize value for radius of circle. Then calculate the area of the circle and display the result to the console. """ pi = 3.1415926536 r = 12.35 area = pi * (r ** 2) print('The area of a circle with radius', r, 'is', area)
When this script is run, the output appears as follows:
C:\Users\john\Documents\Python\doc>python foo.py The area of a circle with radius 12.35 is 479.163565508706
The triple-quoted string is not displayed and doesn’t change the way the script executes in any way. It effectively constitutes a multiline block comment.
Although this works (and was once put forth as a Python programming tip by Guido himself), PEP 8 actually recommends against it. The reason for this appears to be because of a special Python construct called the docstring. A docstring is a special comment at the beginning of a user-defined function that documents the function’s behavior. Docstrings are typically specified as triple-quoted string comments, so PEP 8 recommends that other block comments in Python code be designated the usual way, with a hash character at the start of each line.
However, as you are developing code, if you want a quick and dirty way to comment out as section of code temporarily for experimentation, you may find it convenient to wrap the code in triple quotes.
Further Reading: You will learn more about docstrings in the upcoming tutorial on functions in Python.
For more information on commenting and documenting Python code, including docstrings, see Documenting Python Code: A Complete Guide.
Whitespace
When parsing code, the Python interpreter breaks the input up into tokens. Informally, tokens are just the language elements that you have seen so far: identifiers, keywords, literals, and operators.
Typically, what separates tokens from one another is whitespace: blank characters that provide empty space to improve readability. The most common whitespace characters are the following:
| Character | ASCII Code | Literal Expression |
|---|---|---|
| space | 32 (0x20) |
' ' |
| tab | 9 (0x9) |
'\t' |
| newline | 10 (0xa) |
'\n' |
There are other somewhat outdated ASCII whitespace characters such as line feed and form feed, as well as some very esoteric Unicode characters that provide whitespace. But for present purposes, whitespace usually means a space, tab, or newline.
Whitespace is mostly ignored, and mostly not required, by the Python interpreter. When it is clear where one token ends and the next one starts, whitespace can be omitted. This is usually the case when special non-alphanumeric characters are involved:
>>>>>> x=3;y=12 >>> x+y 15 >>> (x==3)and(x<y) True >>> a=['foo','bar','baz'] >>> a ['foo', 'bar', 'baz'] >>> d={'foo':3,'bar':4} >>> d {'foo': 3, 'bar': 4} >>> x,y,z='foo',14,21.1 >>> (x,y,z) ('foo', 14, 21.1) >>> z='foo'"bar"'baz'#Comment >>> z 'foobarbaz'
Every one of the statements above has no whitespace at all, and the interpreter handles them all fine. That’s not to say that you should write them that way though. Judicious use of whitespace almost always enhances readability, and your code should typically include some. Compare the following code fragments:
>>>>>> value1=100 >>> value2=200 >>> v=(value1>=0)and(value1<value2)>>>
>>> value1 = 100 >>> value2 = 200 >>> v = (value1 >= 0) and (value1 < value2)
Most people would likely find that the added whitespace in the second example makes it easier to read. On the other hand, you could probably find a few who would prefer the first example. To some extent, it is a matter of personal preference. But there are standards for whitespace in expressions and statements put forth in PEP 8, and you should strongly consider adhering to them as much as possible.
Note: You can juxtapose string literals, with or without whitespace:
>>>>>> s = "foo"'bar''''baz''' >>> s 'foobarbaz' >>> s = 'foo' "bar" '''baz''' >>> s 'foobarbaz'
The effect is concatenation, exactly as though you had used the + operator.
In Python, whitespace is generally only required when it is necessary to distinguish one token from the next. This is most common when one or both tokens are an identifier or keyword.
For example, in the following case, whitespace is needed to separate the identifier s from the keyword in:
>>> s = 'bar' >>> s in ['foo', 'bar', 'baz'] True >>> sin ['foo', 'bar', 'baz'] Traceback (most recent call last): File "<pyshell#25>", line 1, in <module> sin ['foo', 'bar', 'baz'] NameError: name 'sin' is not defined
Here is an example where whitespace is required to distinguish between the identifier y and the numeric constant 20:
>>> y is 20 False >>> y is20 SyntaxError: invalid syntax
In this example, whitespace is needed between two keywords:
>>>>>> 'qux' not in ['foo', 'bar', 'baz'] True >>> 'qux' notin ['foo', 'bar', 'baz'] SyntaxError: invalid syntax
Running identifiers or keywords together fools the interpreter into thinking you are referring to a different token than you intended: sin, is20, and notin, in the examples above.
All this tends to be rather academic because it isn’t something you’ll likely need to think about much. Instances where whitespace is necessary tend to be intuitive, and you’ll probably just do it by second nature.
You should use whitespace where it isn’t strictly necessary as well to enhance readability. Ideally, you should follow the guidelines in PEP 8.
Deep Dive: Fortran and Whitespace
The earliest versions of Fortran, one of the first programming languages created, were designed so that all whitespace was completely ignored. Whitespace characters could be optionally included or omitted virtually anywhere—between identifiers and reserved words, and even in the middle of identifiers and reserved words.
For example, if your Fortran code contained a variable named
total, any of the following would be a valid statement to assign it the value50:total = 50 to tal = 50 t o t a l=5 0This was meant as a convenience, but in retrospect it is widely regarded as overkill. It often resulted in code that was difficult to read. Worse yet, it potentially led to code that did not execute correctly.
Consider this tale from NASA in the 1960s. A Mission Control Center orbit computation program written in Fortran was supposed to contain the following line of code:
DO 10 I = 1,100In the Fortran dialect used by NASA at that time, the code shown introduces a loop, a construct that executes a body of code repeatedly. (You will learn about loops in Python in two future tutorials on definite and indefinite iteration).
Unfortunately, this line of code ended up in the program instead:
DO 10 I = 1.100If you have a difficult time seeing the difference, don’t feel too bad. It took the NASA programmer a couple weeks to notice that there is a period between
1and100instead of a comma. Because the Fortran compiler ignored whitespace,DO 10 Iwas taken to be a variable name, and the statementDO 10 I = 1.100resulted in assigning1.100to a variable calledDO10Iinstead of introducing a loop.Some versions of the story claim that a Mercury rocket was lost because of this error, but that is evidently a myth. It did apparently cause inaccurate data for some time, though, before the programmer spotted the error.
Virtually all modern programming languages have chosen not to go this far with ignoring whitespace.
Whitespace as Indentation
There is one more important situation in which whitespace is significant in Python code. Indentation—whitespace that appears to the left of the first token on a line—has very special meaning.
In most interpreted languages, leading whitespace before statements is ignored. For example, consider this Windows Command Prompt session:
C:\Users\john>echo foo foo C:\Users\john> echo foo foo
Note: In a Command Prompt window, the echo command displays its arguments to the console, like the print() function in Python. Similar behavior can be observed from a terminal window in macOS or Linux.
In the second statement, four space characters are inserted to the left of the echo command. But the result is the same. The interpreter ignores the leading whitespace and executes the same command, echo foo, just as it does when the leading whitespace is absent.
Now try more or less the same thing with the Python interpreter:
>>>>>> print('foo') foo >>> print('foo') SyntaxError: unexpected indent
Say what? Unexpected indent? The leading whitespace before the second print() statement causes a SyntaxError exception!
In Python, indentation is not ignored. Leading whitespace is used to compute a line’s indentation level, which in turn is used to determine grouping of statements. As yet, you have not needed to group statements, but that will change in the next tutorial with the introduction of control structures.
Until then, be aware that leading whitespace matters.
Conclusion
This tutorial introduced you to Python program lexical structure. You learned what constitutes a valid Python statement and how to use implicit and explicit line continuation to write a statement that spans multiple lines. You also learned about commenting Python code, and about use of whitespace to enhance readability.
Next, you will learn how to group statements into more complex decision-making constructs using conditional statements.
Take the Quiz: Test your knowledge with our interactive “Python Program Structure” quiz. Upon completion you will receive a score so you can track your learning progress over time.