
Making AI Art with Style Transfer using Keras
Content Loss
The purpose of the content loss is to make sure that the generated image x retains some of the “global” characteristics of the content image, p. For example, in our case, we want to make sure that the generated image looks like the cat in p. This means that shapes such as the cat’s face, ears, and eyes ought to be recognizable. To achieve this, the content loss function is defined as the mean squared error between the feature representations of p


Here,
- F and P are matrices with a number of rows equal to N and a number of columns equal to M
- N is the number of filters in layer l and M is the number of spatial elements in the feature map (height times width) for layer l
- F contains the feature representation of xfor layer l
- P contains the feature representation of p for layer l
Style Loss
On the other hand, the style loss is designed to preserve stylistic characteristics of the style image, a. Rather than using the difference between feature representations, the authors use the the difference between Gram matrices from selected layers, where the Gram matrix is defined as:

The Gram matrix is a square matrix that contains the dot products between each vectorized filter in layer l.The Gram matrix can therefore be thought of as a non-normalized correlation matrix for filters in layer l.
Then, we can define the loss contribution from layer l as
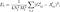

where A is the Gram matrix for the style image a and G is the Gram matrix for the generated image x.
Ascending layers in most convolutional networks such as VGG have increasingly larger receptive fields. As this receptive field grows, more large-scale characteristics of the input image are preserved. Because of this, multiple layers should be selected for “style” to incorporate both local and global stylistic qualities. To create a smooth blending between these different layers, we can assign a weight w to each layer, and define the total style loss as:
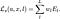

Putting It All Together
Lastly, we just need to assign weighting coefficients to each of the content and style loss respectively, and we’re done!

This is a nice, clean formulation that allows us to tune the relative influence of both the content and style images on the generated image, using ⍺ and ß. Based on the authors’ recommendations and my own experience, ⍺ = 1 and ß = 10,000 works fairly well.