
如何在30秒內建構Spark環境--使用docker-compose 踩坑實錄
如何在30秒內建構PySpark+Jupyter環境--使用docker-compose 踩坑實錄
- 前言
- 使用步驟
- 1. 下載這個專案
- 2. 進入專案的根目錄
- 3. 創造並執行PySpark+Jupyter的容器
- 4. 檢視MasterWebUI和WorkerWebUI
- 5. 在瀏覽器中開啟Jupyter Notebook
- 6. 執行`spark-example.ipynb`
- Dockerfile內容介紹
- 踩坑實錄
- 1. MasterWebUI及WorkerWebUI打不開
- 2. Notebook無法執行
- 3. AnalysisException: 'path file:/results/spark-result already exists.;'
- 4. docker-compose up:ERROR: Encountered errors while bringing up the project.
- 參考連結
- 結語
前言
本篇照著How To Have An Environment With Spark in Less Than 30 Seconds Thanks To Docker這個部落格的教學,並且使用它的GitHub:
筆者執行這個專案時一共踩了三個坑,不想重蹈覆轍的同學可以使用keineahnung2345/docker-blog-example這個填完坑的版本。
使用步驟
1. 下載這個專案
git clone https://github.com/bbvadata/docker-blog-example.git
如果想要使用填完坑的版本,請改用以下指令:
git clone -b all_merged https://github.com/keineahnung2345/docker-blog-example.git
2. 進入專案的根目錄
cd docker-blog-example
3. 創造並執行PySpark+Jupyter的容器
sudo docker-compose up
4. 檢視MasterWebUI和WorkerWebUI
- 到http://<your-host-ip>:8080檢視MasterWebUI
- 到http://<your-host-ip>:8081檢視WorkerWebUI
如果是連線到遠端電腦操作:
- 在bbvadata版下可能會打不開,解決辦法請參考踩坑實錄第一點。
- 在keineahnung2345版,.env檔中有:
需要把127.0.0.1替換成遠端電腦的ip,然後再重新執行上面的指令。HOSTIP=127.0.0.1
5. 在瀏覽器中開啟Jupyter Notebook
-
如果是使用bbvadata的版本,需要找出
docker-compose up輸出中類似:http://localhost:8888/?token=c8de56fa4deed24899803e93c227592aef6538f93025fe01
的字串,然後複製貼上到瀏覽器檢視Jupyter Notebook。
-
如果是使用keineahnung2345的版本,直接到http://<your-host-ip>:8888就可以檢視Jupyter Notebook。這是因為筆者己將密碼設為空字串。
如果還是希望有密碼保護,可以自行修改
.env這個檔案,在裡面加上:PASSWORD=xxx。
之後開啟Jupyter Notebook時,就會要求使用者輸入密碼。

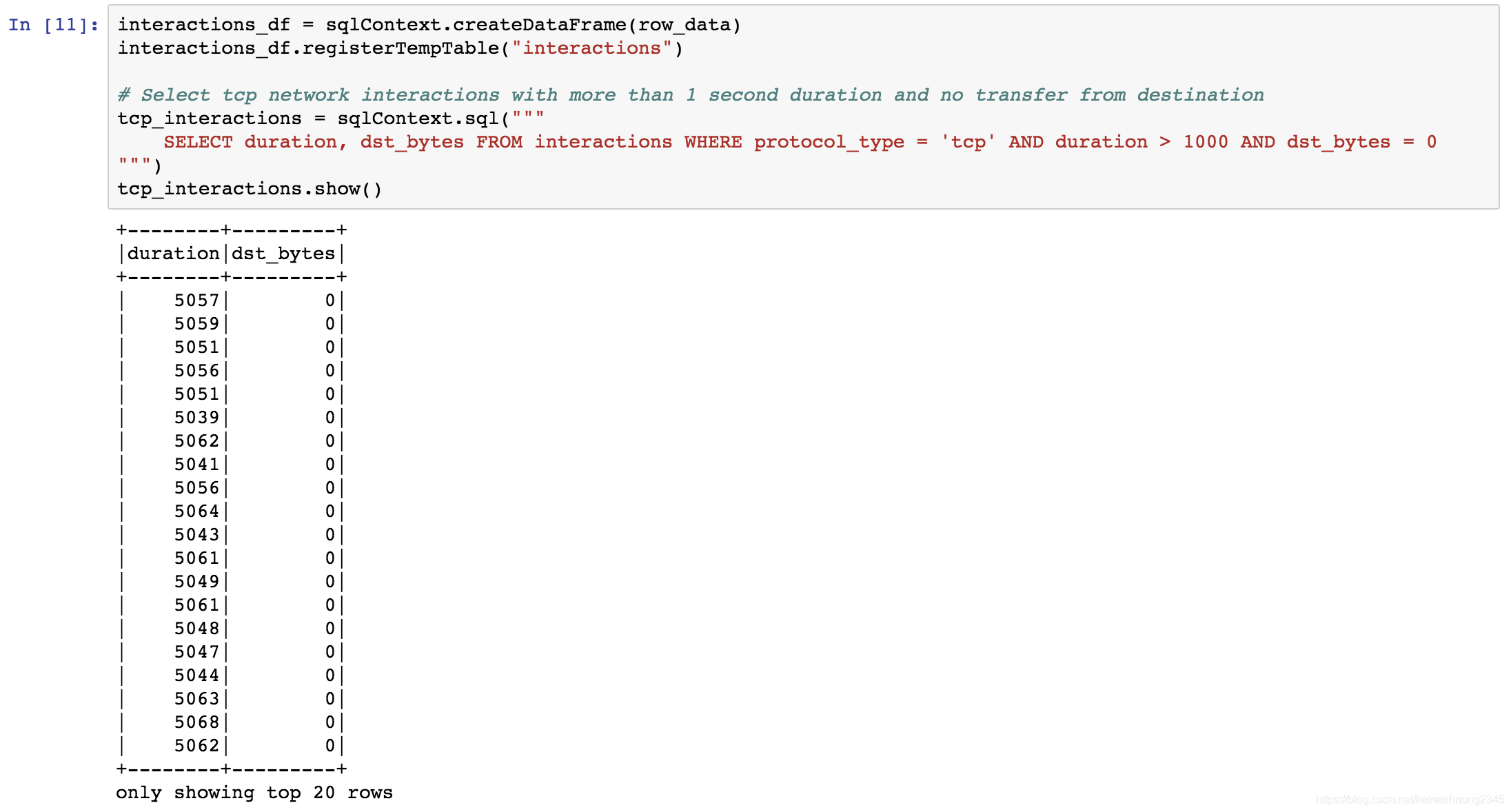
6. 執行spark-example.ipynb
使用bbvadata的版本執行時會報錯,發生原因及解決辦法可以參考踩坑實錄第二點。
以下預期的執行結果:
Dockerfile內容介紹
FROM debian:jessie
MAINTAINER EDGAR PEREZ SAMPEDRO <[email protected]>
#JAVA
# 自動驗證license
RUN echo oracle-java8-installer shared/accepted-oracle-license-v1-1 select true | /usr/bin/debconf-set-selections
# 更新倉庫
RUN echo "deb http://ppa.launchpad.net/webupd8team/java/ubuntu trusty main" | tee /etc/apt/sources.list.d/webupd8team-java.list
RUN echo "deb-src http://ppa.launchpad.net/webupd8team/java/ubuntu trusty main" | tee -a /etc/apt/sources.list.d/webupd8team-java.list
RUN apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys EEA14886
RUN apt-get update
# 安裝Java
RUN apt-get install oracle-java8-installer -y
RUN apt-get clean
# 安裝ANACONDA3前的準備
RUN apt-get update && \
apt-get install -y curl build-essential libpng12-dev libffi-dev && \
apt-get clean && \
rm -rf /var/tmp /tmp /var/lib/apt/lists/*
# 安裝ANACONDA3
ENV CONDA_DIR="/root/anaconda3"
ENV PATH="$CONDA_DIR/bin:$PATH"
RUN curl -sSL -o installer.sh https://repo.continuum.io/archive/Anaconda3-4.4.0-Linux-x86_64.sh && \
bash /installer.sh -b -f && \
rm /installer.sh
# 設定環境變數
ENV PATH "$CONDA_DIR/bin:$PATH"
# 安裝SPARK
ARG SPARK_ARCHIVE=https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz
RUN curl -s $SPARK_ARCHIVE | tar -xz -C /usr/local/
ENV SPARK_HOME /usr/local/spark-2.2.0-bin-hadoop2.7
ENV PATH $PATH:$SPARK_HOME/bin
# 建立自定義的CONDA環境pyspark
RUN conda create -n pyspark python=3.5
RUN ["/bin/bash", "-c", "source activate pyspark; apt-get install libstdc++; conda install jupyter;conda install ipykernel; python -m ipykernel install --user --name pyspark --display-name pyspark; source deactivate"]
ENV PATH "$CONDA_DIR/envs/pyspark/bin:$PATH"
# JUPYTER NOTEBOOK的設定
COPY jupyter_notebook_config.py /root/.jupyter/
EXPOSE 8888
# notebook檔案儲存的目錄
COPY notebooks /notebooks
# 設定環境變數
ENV JAVA_HOME /usr/lib/jvm/java-8-oracle
ENV PYSPARK_PYTHON /root/anaconda3/envs/pyspark/bin/python
# ENV PYSPARK_DRIVER_PYTHON_OPTS notebook
# ENV PYSPARK_DRIVER_PYTHON jupyter
ENV PYTHONPATH /usr/local/spark-2.2.0-bin-hadoop2.7/python/lib/py4j-0.10.4-src.zip:/usr/local/spark-2.2.0-bin-hadoop2.7/python:PYSPARK_DRIVER_PYTHON=ipython
# 一開始進入容器的工作目錄
WORKDIR "/notebooks"
# 進入容器後第一個執行的指令
CMD ["/bin/bash", "-c", "jupyter notebook --allow-root"]
踩坑實錄
1. MasterWebUI及WorkerWebUI打不開
如果是在本機執行應該不會發生這種情況。
筆者會碰到這個問題是因為筆者是連線到遠端的server,然後試圖在本地的瀏覽器開啟WebUI。
有兩個方法可以解決這個問題:
-
將
docker-compose.yml中的以下兩個欄位:
spark-master→environment→SPARK_PUBLIC_DNS
spark-master→environment→SPARK_PUBLIC_DNS
改為那臺遠端server的ip。 -
將以上兩個欄位改成
${HOSTIP},然後建立一個.env檔,裡面寫入HOSTIP=<your-host-ip>。
具體情況可以參考SPARK_PUBLIC_DNS: use host ip rather than 127.0.0.1。
2. Notebook無法執行
這是因為原版的Dockerfile中的環境變數設定錯誤,導致由它建構出來的docker映象edgarperezsampedro/blog_docker中的環境變數也是錯的。
具體情況請參考Fix CONDA_DIR and give priority to pyspark。
首先修正Dockerfile這個檔案:
- 將第26行的
ENV CONDA_DIR="/conda"改為ENV CONDA_DIR="/root/anaconda3" - 將第32行的
ENV PATH "$PATH:/root/anaconda3/bin"改為ENV PATH "$CONDA_DIR/bin:$PATH" - 在第43行下面加入
ENV PATH "$CONDA_DIR/envs/pyspark/bin:$PATH"
然後自己建構一個docker image,使用以下指令:
docker build . -t <your-image-name>
筆者己經做過了這一步,建好了一個名叫keineahnung2345/edgarperezsampedro-blog_docker:20181126的docker映象。
如要使用,可以將docker-compose.yml中的:
services:
jupyter-debian:
image: edgarperezsampedro/blog_docker
改成:
services:
jupyter-debian:
image: keineahnung2345/edgarperezsampedro-blog_docker:20181126
就會直接拉取修改過的docker映象。
3. AnalysisException: ‘path file:/results/spark-result already exists.;’
因為程式執行會產生spark-result這個資料夾,如果多次執行的時候就會報錯,說明該資料夾己經存在。
筆者的解決辦法是將原來的:
tcp_interactions.write.format('csv').save("/results/spark-result", sep='|', header=True)
改為:
tcp_interactions.write.format('csv').mode('overwrite').save("/results/spark-result", sep='|', header=True)
如此一來,如果執行時發現檔案夾己經存在,就會自動覆寫,而不會報錯。
4. docker-compose up:ERROR: Encountered errors while bringing up the project.
會發生這個錯誤其實是筆者粗心所致,在docker-compose up:ERROR: Encountered errors while bringing up the project.錯誤及解決方式中有詳細的說明。
參考連結
How To Have An Environment With Spark in Less Than 30 Seconds Thanks To Docker
bbvadata/docker-blog-example
keineahnung2345/docker-blog-example
SPARK_PUBLIC_DNS: use host ip rather than 127.0.0.1
Fix CONDA_DIR and give priority to pyspark
docker-compose up:ERROR: Encountered errors while bringing up the project.錯誤及解決方式
結語
本文還有個續篇:使用docker stack建構跨主機PySpark+Jupyter叢集。
該篇延續了本篇單機版的PySpark叢集,建構了跨機器的版本,並且加入visualizer,讓我們可以在網頁中監控docker的執行狀況。