
老男孩14期自動化運維day11隨筆和作業(一)
1.獨立程序間的通訊(比如不同應用,注意不是多程序的通訊)
(1)通過磁碟寫入,讀出
(2)建立socket
(3)通過broker(中介軟體代理,到broker也是通過建立的socket)
2.常見的訊息佇列
RabbitMQ ZeroMQ ActiveMQ kafka(日誌系統)
RabbitMq、ActiveMq、ZeroMq、kafka之間的比較:
轉載:https://blog.csdn.net/qq853632587/article/details/75009735
RabbitMQ使用(新增使用者,虛擬主機等)轉載:https://blog.csdn.net/kk185800961/article/details/55214474
3.RabbitMQ簡介
rabbitMQ是erlang開發的,在windows上和linux上都要裝erlang
openstack 預設用的rabbitmq
概念模型:
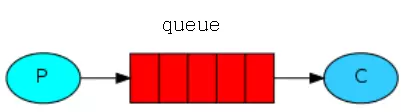
4.rabbitMQ簡單的使用
如果關閉rabbitMQ服務,資料會丟失,所以要對每一個佇列做訊息持久化 在producer里加
佇列持久化:channel.queue_declare(queue=‘hello’,durable=True)
訊息持久化:在chanel.basic_publish{
properties=pika.BasicProperties(delivery_mode=2,) }
使用rabbitmq通訊的原始碼加解析:
訊息公平分發
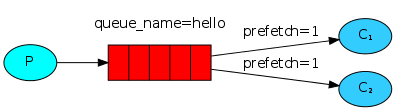
實現訊息公平分發程式碼如下
producer:
'''send端'''
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters('localhost')
)
channel=connection.channel() # 申明一個管道
# 申明queue
channel.queue_declare(queue='hello',durable=True) # 佇列持久化
channel.basic_publish( consumer:
注意消費者預設basic_consume中的要給生產者傳送“收到訊息”的確認資訊
no_ack=True # no acknowledgement 訊息處理完了之後,不給producer 說
保留no_ack=True 就是不確認 producer 不關心consumer是否處理完訊息
一般預設是要確認,且最好不用 no_ack,因為如果consumer斷了,producer好把訊息作為新訊息給下一個queue處理實現訊息輪詢
要想producer等consumer處理完當前訊息再給它發訊息的實現:
在consumer 中加入 channerl.basic_qos(prefetch_count=1)
#!/usr/bin/env python
# coding:utf-8
# Author:Yang
'''receive端'''
'''訊息公平分發'''
import pika
connection = pika.BlockingConnection(
pika.ConnectionParameters('localhost')
)
channel=connection.channel()
channel.queue_declare(queue='hello',durable=True) # 為什麼還要宣告?因為不知道消費者和生產者誰先啟動,所以要避免出錯才宣告
def callback(ch,method,properties,body):
print(ch,method,properties)
print(method)
print("[x] Received %r"%body)
ch.basic_ack(delivery_tag=method.delivery_tag) # 手動確認訊息
channel.basic_qos(prefetch_count=1) # 告訴producer 等我處理完這一條 再給我發下一條 實現訊息公平分發(可能因為這個配置不高的消費者處理不完那麼多訊息而堆積)
channel.basic_consume( # 消費訊息
callback, # 如果收到訊息,就呼叫CALLBACK函式來處理訊息 (回撥函式)
queue='hello'
# no_ack=True # no acknowledgement 訊息處理完了之後,不給producer 說
# 保留no_ack=True 就是不確認 producer 不關心consumer是否處理完訊息
# 一般預設是要確認,且最好不用 no_ack,因為如果consumer斷了,producer好把訊息作為新訊息給下一個queue處理實現訊息輪詢
)
print('[*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming() # 開始收(一直收)
如果要外網能連線rabbitMQ,開頭寫法為
credentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost',5672,'/',credentials))
注意:guest只能本地訪問
5.RabbitMq 訊息的訂閱、釋出
(1)fanout:所有bind到此exchange的queue都可以接收訊息
(2)direct:通過routingKey和exchange決定的那個唯一的queue可以接收訊息
(3)topic:所有複合routingKsy(此時可以是一個表示式)的routingKey所bind的queue可以接收訊息
(4)headers:通過headers來絕對把訊息發給哪些queue(很少用)
rabbitmq與activemq的訊息訂閱釋出不同點:
activemq最常用的topic訊息訂閱釋出,釋出者釋出資訊到topic ,消費者繫結topic並從topic拿資訊
rabbitmq的topic 是更細緻的訊息過濾,比如 釋出者釋出 mysql.info 消費者topic為mysql.*可以收到這個資訊
(1)fanout訂閱廣播:
為什麼叫廣播? 因為如果consumer沒有執行 是收不到producer的訊息的,就像廣播,沒有開啟收音機就聽不到
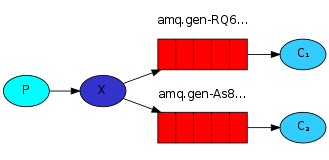
producer:
'''fanout 訂閱廣播producer'''
import sys
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost"))
channel=connection.channel()
channel.exchange_declare(exchange='logs', # 宣告exchange型別
exchange_type='fanout')
# 在producer端不用制定佇列名字 因為queue是繫結到exhcange上的,且queue的名字是隨機的
message="info:hello world!"
channel.basic_publish(
exchange='logs',
routing_key='',# 不用制定queue的名字
body=message
)
print("[x] Sent %r"%message)
connection.close()
consumer:
'''fanout訂閱廣播consumer'''
import pika
connection=pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel=connection.channel()
channel.exchange_declare(exchange='logs', # 宣告 exchange型別
exchange_type='fanout')
result = channel.queue_declare(exclusive=True) # exclusive(排他)引數是指不用指定queue的名字,rabbit會隨機分配一個名字,在消費者斷開後,自動將queue刪除
queue_name=result.method.queue # 拿到queue的名字
print('random queue_name',queue_name)
channel.queue_bind(exchange='logs', # 將queue繫結exchange
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
# 如果consumer沒有執行 是收不到producer的訊息的,就像廣播,沒有開啟收音機就聽不到
(2)direct 有選擇訊息接收
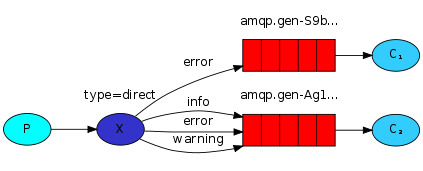
producer:
傳送訊息,並帶上該訊息的型別
'''有選擇接收 direct producer端'''
import sys
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
# argv[1]表示第一個引數,如果沒有引數 則預設傳送'info':helloworld
# 如果有一個引數以上,第一個引數是傳送的型別 例如"error",第二個引數到後面都是message
message=''.join(sys.argv[2:]) or 'hello world'
channel.basic_publish(
exchange='direct_logs',
routing_key=severity,
body=message
)
print("[x] sent %r:%r"%(severity,message))
connection.close()
# producer 傳送訊息 並帶上該訊息的型別
consumer:
consumer 定義從queue收到訊息的型別,然後只收該型別訊息,訊息型別是一個list
'''有選擇接收 direct consumer端'''
import sys
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
exchange_type='direct')
result=channel.queue_declare(exclusive=True) # 隨機queue
queue_name=result.method.queue
severities=sys.argv[1:] # 設定的執行引數 去除掉py檔名本身 (傳送命令格式例如 python direct_consumer.py waring error)
# severities就是[warning,error]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(
exchange='direct_logs',
queue=queue_name,
routing_key=severity
)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
# consumer 定義從queue收到訊息的型別,然後只收該型別訊息,訊息型別是一個list
(3)topic 更細緻的訊息過濾
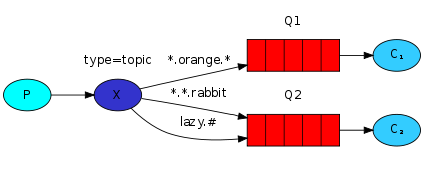
“#” 號收所有
*.mysql mysql在第二個 msyql. * mysql開頭 只有兩個
producer:
'''更細緻的訊息過濾 topic producer'''
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
consumer:
'''更細緻的訊息過濾 topic consumer'''
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
# # 號收所有
# *.mysql mysql在第二個
# msyql.* mysql開頭 只有兩個
6.RPC服務
remote procedure call(遠端程式呼叫) ----RPC服務 RPC
服務就是本地傳送執行指令到遠端主機,傳送到遠端,遠端主機返回結果給本地主機 既是消費者又是生產者
7.RabbitMQ實現RPC服務
整個rpc服務的流程為:

先啟動server 再啟動client
(1) server 宣告 rpc_queue 往裡面收要處理的資料,client通過rpc_queue發資料,包含 server處理完資料要返回結果使用的一個隨機queue的指標(reply_to)和 一個隨機生成的corr_id
(2) server 從rpc_queue拿到資料 進行處理,處理完後呼叫回撥函式,通過 隨機的queue 傳送帶有 corr_id 和 結果的訊息傳給client
(3) client 收到訊息 呼叫回撥函式 展示結果
注意:生成corr_id的作用在於,確保返回的資料是這次呼叫遠端函式的結果,比如一個函式處理5分鐘,一個函式處理2分鐘,處理的快的先返回了,為了
防止這種情況,需要加入corr_id來確認是否為函式呼叫的正確結果
rpc_client.py
''' rpc client rpc服務的客戶端'''
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.credentials = pika.PlainCredentials('guest', 'guest')
self.connection = pika.BlockingConnection(pika.ConnectionParameters('localhost', 5672, '/', self.credentials))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True) # server端執行完的結果 用一個隨機生成的queue接收(就是callback_queue)
self.callback_queue = result.method.queue
self.channel.basic_consume(self.on_response, no_ack=True,# 用來收server端執行的結果 on_response 是回撥函式,收到訊息則執行
queue=self.callback_queue)
def on_response(self, ch, method, props, body):# 回撥函式
if self.corr_id == props.correlation_id: # 如果client端生成的隨機id與server端返回的隨機id一致 則將返回的訊息賦給body
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4()) # uuid模組,呼叫uuid.uuid4() 可以生成一個唯一的隨機id
self.channel.basic_publish(exchange='',
routing_key='rpc_queue', # 傳送資料的時候使用rpc_queue
properties=pika.BasicProperties(
reply_to=self.callback_queue, # props裡制定了server端執行完要返回結果通過的queue為上面隨機生成的queue
correlation_id=self.corr_id, # 帶上生成的隨機id為引數
),
body=n)
while self.response is None:
self.connection.process_data_events() # 這句是死迴圈接受server返回的資訊,沒有結果不用一直等待,是表示使用非阻塞式的connection.start_consuming
print("no msg..")
return self.response.decode()
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call('a')
print(" [.] Got %r" % response)
rpc_server.py
''' rpc server rpc服務的服務端'''
import pika
import time
credentials = pika.PlainCredentials('guest', 'guest')
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost',5672,'/',credentials))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue') # 同樣宣告 從rpc_queue裡收到要server端處理的資料
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
def on_request(ch, method, props, body): # 回撥函式 收到client端發來的資訊進行處理,處理完之後時呼叫就給client髮結果了
n=body.decode()
print(" [.] fib(%s)" % n)
response = n
ch.basic_publish(exchange='',
routing_key=props.reply_to, # 獲取client傳來的props裡定義的返回結果使用的queue (client props屬性裡reply_to的一個隨機queue)
properties=pika.BasicProperties(correlation_id= props.correlation_id), # 獲取client裡傳來props裡的隨機id
body=response)
ch.basic_ack(delivery_tag=method.delivery_tag) # server端處理完訊息要給client發一個確認
channel.basic_consume(on_request, queue='rpc_queue')
print(" [x] Awaiting RPC requests")
channel.start_consuming()