
python學習日記(常用模組)
模組概念
什麼是模組
常見的場景:一個模組就是一個包含了python定義和宣告的檔案,檔名就是模組名字加上.py的字尾。
但其實import載入的模組分為四個通用類別:
1 使用python編寫的程式碼(.py檔案)
2 已被編譯為共享庫或DLL的C或C++擴充套件
3 包好一組模組的包
4 使用C編寫並連結到python直譯器的內建模組
為何要使用模組?
如果你退出python直譯器然後重新進入,那麼你之前定義的函式或者變數都將丟失,因此我們通常將程式寫到檔案中以便永久儲存下來,需要時就通過python test.py方式去執行,此時test.py被稱為指令碼script。
隨著程式的發展,功能越來越多,為了方便管理,我們通常將程式分成一個個的檔案,這樣做程式的結構更清晰,方便管理。這時我們不僅僅可以把這些檔案當做指令碼去執行,還可以把他們當做模組來匯入到其他的模組中,實現了功能的重複利用。
常用模組一
collections模組
在內建資料型別(dict、list、set、tuple)的基礎上,collections模組還提供了幾個額外的資料型別:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字來訪問元素內容的tuple
2.deque: 雙端佇列,可以快速的從另外一側追加和推出物件
3.Counter: 計數器,主要用來計數
4.OrderedDict: 有序字典
5.defaultdict: 帶有預設值的字典
namedtuple
namedtuple: 生成可以使用名字來訪問元素內容的tuple.
我們知道tuple可以表示不變集合,例如,一個點的二維座標就可以表示成:
p = (1, 2)
但是,看到(1, 2),很難看出這個tuple是用來表示一個座標的。
這時,namedtuple就派上了用場:
from collections import namedtuple Point = namedtuple('point',['x','y']) p = Point(1,2) print(p.x) print(p.y) # print(p.y+p.x) print(p[0]+p[1]) p = p._replace(x=100,y = 30)#更改值 print(p)

類似的,如果要用座標和半徑表示一個圓,也可以用namedtuple定義:
Circle = namedtuple('circle',['x','y','r']) c = Circle(0,0,2) print(c.x) print(c[2])#索引 c = c._replace(x=2,y=2,r=4) print(c)

deque
deque: 雙端佇列,可以快速的從另外一側追加和推出物件
使用list儲存資料時,按索引訪問元素很快,但是插入和刪除元素就很慢了,因為list是線性儲存,資料量大的時候,插入和刪除效率很低。
deque是為了高效實現插入和刪除操作的雙向列表,適合用於佇列和棧:
deque除了實現list的append()和pop()外,還支援appendleft()和popleft(),這樣就可以非常高效地往頭部新增或刪除元素。
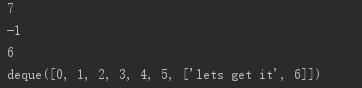
from collections import deque q = deque([1,2,3,4,5]) q.append(['lets get it',6]) q.append(7) q.appendleft(0) q.insert(0,-1) print(q.pop()) print(q.popleft()) print(q.index(['lets get it',6])) print(q) # for i in q: # print(i)
queue
佇列,先進先出
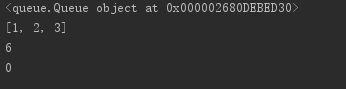
import queue q = queue.Queue() q.put([1,2,3]) q.put(6) print(q) print(q.get())#[1,2,3] print(q.get())#6 # print(q.get())#取不到,阻塞 print(q.qsize())#元素個數
OrderedDict
有序字典
使用dict時,Key是無序的。在對dict做迭代時,我們無法確定Key的順序。
如果要保持Key的順序,可以用OrderedDict:
from collections import OrderedDict d = dict([('k1',1),('k2',2),('k3',3)]) print(d)#普通字典,key無序 od = OrderedDict([('k1',1),('k2',2),('k3',3)]) print(od)#OderedDict的key有序

注意,OrderedDict的Key會按照插入的順序排列,不是Key本身排序:
from collections import OrderedDict od1 = OrderedDict() od1['x'] = 1 od1['y'] = 2 od1['z'] = 3 print(od1.keys())

defaultdict
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],將所有大於 66 的值儲存至字典的第一個key中,將小於 66 的值儲存至第二個key的值中。
即: {
'k1'
: 大於
66
,
'k2'
: 小於
66
}
一、普通字典方法
values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = {} for value in values: if value>66: if 'k1' in my_dict:#python3字典無has_key方法 # if my_dict.has_key('k1'): my_dict['k1'].append(value)#key存在,就向列表中新增value else: my_dict['k1'] = [value]#key不存在就建立一個列表儲存value else: if 'k2' in my_dict: # if my_dict.has_key('k2'): my_dict['k2'].append(value) else: my_dict['k2'] = [value] print(my_dict)

二、defaultdict字典解決方法
from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] d = defaultdict(list) for value in values: if value > 66: d['k1'].append(value) else: d['k2'].append(value) print(d)

注意:使用dict時,如果引用的Key不存在,就會丟擲KeyError。如果希望key不存在時,返回一個預設值,就可以用defaultdict:
from collections import defaultdict di = defaultdict(lambda :'hello') di['k'] = '1' di['j'] print(di)

Counter
Counter類的目的是用來跟蹤值出現的次數。它是一個無序的容器型別,以字典的鍵值對形式儲存,其中元素作為key,其計數作為value。計數值可以是任意的Interger(包括0和負數)。Counter類和其他語言的bags或multisets很相似
from collections import Counter c = Counter('abcabcabcasdfsdfddddd') print(c) c1 = Counter([1,2,3,2,1,3,45612]) print(c1)

時間模組
關於
和時間有關係的我們就要用到時間模組。在使用模組之前,應該首先匯入這個模組。
#常用方法 1.time.sleep(secs) (執行緒)推遲指定的時間執行。單位為秒。 2.time.time() 獲取當前時間戳
表示時間的三種方式
在Python中,通常有這三種方式來表示時間:時間戳、元組(struct_time)、格式化的時間字串:
(1)時間戳(timestamp) :通常來說,時間戳表示的是從1970年1月1日00:00:00開始按秒計算的偏移量。我們執行“type(time.time())”,返回的是float型別。
(2)格式化的時間字串(Format String): ‘2008-08-08’


%y 兩位數的年份表示(00-99) %Y 四位數的年份表示(000-9999) %m 月份(01-12) %d 月內中的一天(0-31) %H 24小時制小時數(0-23) %I 12小時制小時數(01-12) %M 分鐘數(00=59) %S 秒(00-59) %a 本地簡化星期名稱 %A 本地完整星期名稱 %b 本地簡化的月份名稱 %B 本地完整的月份名稱 %c 本地相應的日期表示和時間表示 %j 年內的一天(001-366) %p 本地A.M.或P.M.的等價符 %U 一年中的星期數(00-53)星期天為星期的開始 %w 星期(0-6),星期天為星期的開始 %W 一年中的星期數(00-53)星期一為星期的開始 %x 本地相應的日期表示 %X 本地相應的時間表示 %Z 當前時區的名稱 %% %號本身python中時間日期格式化符號:
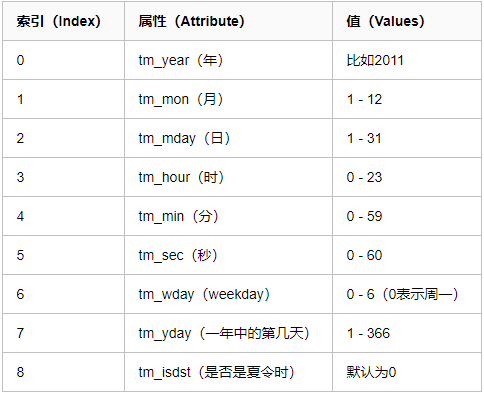
(3)元組(struct_time) :struct_time元組共有9個元素共九個元素:(年,月,日,時,分,秒,一年中第幾周,一年中第幾天等)
首先,我們先匯入time模組,來認識一下python中表示時間的幾種格式:
import time print(time.time())#時間戳 print(time.strftime('%Y-%m-%d %H:%M:%S'))#時間字串,字串格式化 print(time.localtime()) print(time.localtime(2000000000))#將時間戳轉換為struct_time

小結:時間戳是計算機能夠識別的時間;時間字串是人能夠看懂的時間;元組則是用來操作時間的
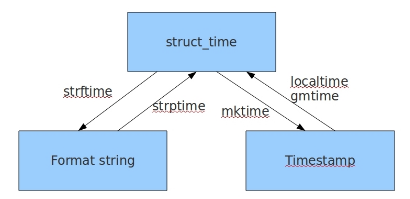
幾種格式之間的轉換
import time #時間戳-->結構化時間 #time.gmtime(時間戳) UTC時間,與英國倫敦當地時間一致 #time.localtime(時間戳) 當地時間 print(time.gmtime(150)) print(time.localtime(150)) #結構化時間-->時間戳 #time.mktime(結構化時間) t = time.localtime(150) print(time.mktime(t))

import time #結構化時間-->字串時間 #time.strftime("格式定義","結構化時間") 結構化時間引數若不傳,則顯示當前時間 print(time.strftime('%Y-%m-%d %X')) print(time.strftime('%Y-%m-%d',time.localtime(150))) #字串時間-->結構化時間 #time.strptime(時間字串,字串對應格式) print(time.strptime('2018/10/01','%Y/%m/%d'))

import time #結構化時間 --> %a %b %d %H:%M:%S %Y串 #time.asctime(結構化時間) 如果不傳引數,直接返回當前時間的格式化串 print(time.asctime()) print(time.asctime(time.localtime(150))) #時間戳 --> %a %b %d %H:%M:%S %Y串 #time.ctime(時間戳) 如果不傳引數,直接返回當前時間的格式化串 print(time.ctime()) print(time.ctime(150))
計算時間間隔
#時間差 import time #字串轉成結構化 str_time1 = time.strptime('2018-12-8 22:00:00','%Y-%m-%d %H:%M:%S')#前一天時間 str_time2 = time.strptime('2018-12-9 8:00:00','%Y-%m-%d %H:%M:%S')#今天時間 #結構化轉成時間戳 time1 = time.mktime(str_time1) time2 = time.mktime(str_time2) t = time2 - time1#時間戳差 print(t) #時間戳轉回結構化 t1 = time.gmtime(time2 - time1) #結構化轉回字串 t2 = time.strftime('%H:%M:%S',time.gmtime(t)) print('時間間隔為:',t2)

random模組
import random # 隨機小數 print(random.random())#大於0小於1 之間的小數 print(random.uniform(1,3))#大於1小於3的小數 #隨機整數 print(random.randint(1,5))#大於等於1且小於等於5之間的整數 print(random.randrange(1,10,2))#大於等於1且小於等於10之間的奇數
import random #隨機選擇一個返回 print(random.choice(['libai','dufu','baijuyi'])) #隨機選擇多個返回,返滬的個數為函式的第二個引數 print(random.sample(['red','yellow','white','black','pink','blue'],3)) #打亂列表順序 li = [1,2,3,4,5,6] random.shuffle(li)#沒有返回值 print(li)

os模組
os模組是與作業系統互動的一個介面
os.makedirs('dirname1/dirname2') 可生成多層遞迴目錄 os.removedirs('dirname1') 若目錄為空,則刪除,並遞迴到上一級目錄,如若也為空,則刪除,依此類推 os.mkdir('dirname') 生成單級目錄;相當於shell中mkdir dirname os.rmdir('dirname') 刪除單級空目錄,若目錄不為空則無法刪除,報錯;相當於shell中rmdir dirname os.listdir('dirname') 列出指定目錄下的所有檔案和子目錄,包括隱藏檔案,並以列表方式列印 os.remove() 刪除一個檔案 os.rename("oldname","newname") 重新命名檔案/目錄 os.stat('path/filename') 獲取檔案/目錄資訊 os.system("bash command") 執行shell命令,直接顯示 os.popen("bash command).read() 執行shell命令,獲取執行結果 os.getcwd() 獲取當前工作目錄,即當前python指令碼工作的目錄路徑 os.chdir("dirname") 改變當前指令碼工作目錄;相當於shell下cd os.path os.path.abspath(path) 返回path規範化的絕對路徑 os.path.split(path) 將path分割成目錄和檔名二元組返回 os.path.dirname(path) 返回path的目錄。其實就是os.path.split(path)的第一個元素 os.path.basename(path) 返回path最後的檔名。如何path以/或\結尾,那麼就會返回空值。即os.path.split(path)的第二個元素 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) 如果path是絕對路徑,返回True os.path.isfile(path) 如果path是一個存在的檔案,返回True。否則返回False os.path.isdir(path) 如果path是一個存在的目錄,則返回True。否則返回False os.path.join(path1[, path2[, ...]]) 將多個路徑組合後返回,第一個絕對路徑之前的引數將被忽略 os.path.getatime(path) 返回path所指向的檔案或者目錄的最後訪問時間 os.path.getmtime(path) 返回path所指向的檔案或者目錄的最後修改時間 os.path.getsize(path) 返回path的大小
注意:os.stat('path/filename') 獲取檔案/目錄資訊 的結構說明
stat 結構: st_mode: inode 保護模式 st_ino: inode 節點號。 st_dev: inode 駐留的裝置。 st_nlink: inode 的連結數。 st_uid: 所有者的使用者ID。 st_gid: 所有者的組ID。 st_size: 普通檔案以位元組為單位的大小;包含等待某些特殊檔案的資料。 st_atime: 上次訪問的時間。 st_mtime: 最後一次修改的時間。 st_ctime: 由作業系統報告的"ctime"。在某些系統上(如Unix)是最新的元資料更改的時間,在其它系統上(如Windows)是建立時間(詳細資訊參見平臺的文件)。stat 結構
os.sep 輸出作業系統特定的路徑分隔符,win下為"\\",Linux下為"/" os.linesep 輸出當前平臺使用的行終止符,win下為"\r\n",Linux下為"\n" os.pathsep 輸出用於分割檔案路徑的字串 win下為;,Linux下為: os.name 輸出字串指示當前使用平臺。win->'nt'; Linux->'posix'os模組的屬性
sys模組
sys模組是與Python直譯器互動的一個介面
sys.argv 命令列引數List,第一個元素是程式本身路徑 sys.exit(n) 退出程式,正常退出時exit(0),錯誤退出sys.exit(1) sys.version 獲取Python解釋程式的版本資訊 sys.path 返回模組的搜尋路徑,初始化時使用PYTHONPATH環境變數的值 sys.platform 返回作業系統平臺名稱
import sys try: sys.exit(1) except SystemExit as e: print(e)異常處理和status
序列化模組
概念
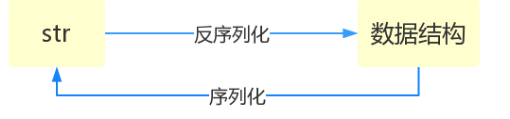
什麼叫序列化——將原本的字典、列表等內容轉化成一個字串的過程就是序列化。
比如,我們在python程式碼中計算的一個數據需要給另外一段程式使用,那我們怎麼給? 現在我們能想到的方法就是存在檔案裡,然後另一個python程式再從檔案裡讀出來。 但是我們都知道,對於檔案來說是沒有字典這個概念的,所以我們只能將資料轉換成字典放到檔案中。 你一定會問,將字典轉換成一個字串很簡單,就是str(dic)就可以辦到了,為什麼我們還要學習序列化模組呢? 沒錯序列化的過程就是從dic 變成str(dic)的過程。現在你可以通過str(dic),將一個名為dic的字典轉換成一個字串, 但是你要怎麼把一個字串轉換成字典呢? 聰明的你肯定想到了eval(),如果我們將一個字串型別的字典str_dic傳給eval,就會得到一個返回的字典型別了。 eval()函式十分強大,但是eval是做什麼的?e官方demo解釋為:將字串str當成有效的表示式來求值並返回計算結果。 BUT!強大的函式有代價。安全性是其最大的缺點。 想象一下,如果我們從檔案中讀出的不是一個數據結構,而是一句"刪除檔案"類似的破壞性語句,那麼後果實在不堪設設想。 而使用eval就要擔這個風險。 所以,我們並不推薦用eval方法來進行反序列化操作(將str轉換成python中的資料結構為什麼要有序列化模組
序列化的目的
1、以某種儲存形式使自定義物件持久化
2、將物件從一個地方傳遞到另一個地方
3、使程式更具維護性
json模組
JSON (JavaScript Object Notation) 是一種輕量級的資料交換格式。
Json模組提供了四個功能:dumps、dump、loads、load
Python3 中可以使用 json 模組來對 JSON 資料進行編解碼,它包含了兩個函式:
- json.dumps(): 對資料進行編碼。
- json.loads(): 對資料進行解碼。
在json的編解碼過程中,python 的原始型別與json型別會相互轉換,具體的轉化對照如下:
Python 編碼為 JSON 型別轉換對應表:
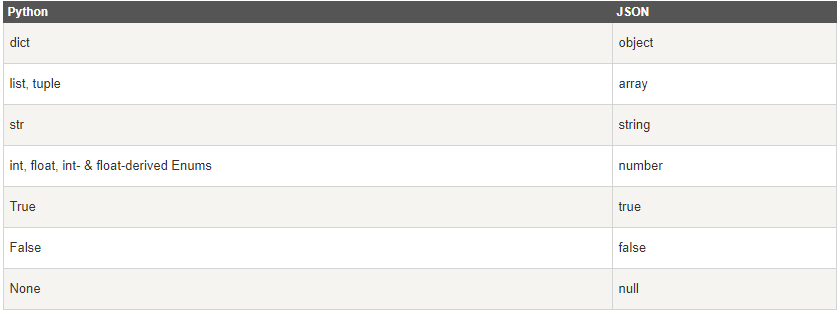
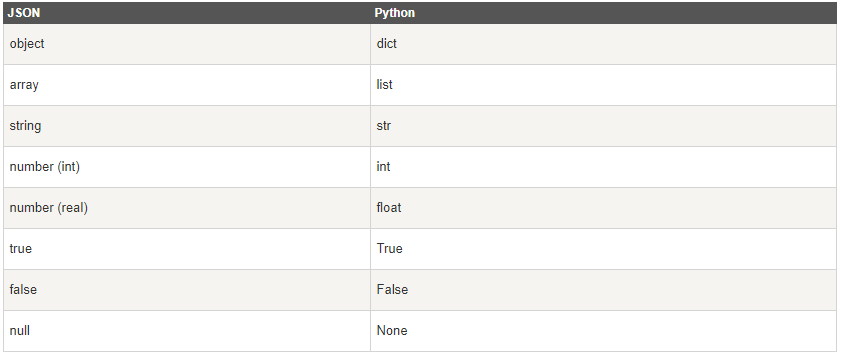
JSON 解碼為 Python 型別轉換對應表:
json.dumps 與 json.loads(字串)
import json dic = {'red':'apple','yellow':'orange'} str_dic = json.dumps(dic)#序列化,將字典轉化成字串 print(type(str_dic),str_dic) #注意,json轉換完的字串型別的字典中的字串是由""表示的 dic1 = json.loads(str_dic)#反序列化 #注意,要用json的loads功能處理的字串型別的字典中的字串必須由""表示 print(type(dic1),dic1)

json.dump 與 json.load(檔案)
如果你要處理的是檔案而不是字串,你可以使用 json.dump() 和 json.load() 來編碼和解碼JSON資料。
import json dic = {'red':'apple','yellow':'orange'} #寫入資料,dump方法接收一個檔案控制代碼,直接將字典轉換成json字串寫入檔案 with open('f.test','w') as f: json.dump(dic,f) #讀取資料,load方法接收一個檔案控制代碼,直接將檔案中的json字串轉換成資料結構返回 with open('f.test') as f: f1 = json.load(f) print(type(f1),f1)

dump(ensure_ascii)
如果ensure_ascii為true(預設值),則保證輸出將所有傳入的非ASCII字元轉義。如果ensure_ascii為false,則這些字元將按原樣輸出。
import json f = open('f.test','w',encoding='utf-8') json.dump({'國家':'中國'},f) # ret = json.dumps({'國家':'中國'}) # f.write(ret+'\n')#一行一行的寫進去 json.dump({'國籍':'美國'},f,ensure_ascii=False) # ret = json.dumps({'國籍':'美國'},ensure_ascii=False) # f.write(ret+'\n') f.close() with open('f.test',encoding='utf-8') as f: print(f.readlines())

dump(其他引數)
ident:
如果indent是非負整數或字串,那麼JSON陣列元素和物件成員將使用該縮排級別進行漂亮列印。縮排級別為0,為負,或""僅插入換行符。 None(預設值)選擇最緊湊的表示。使用正整數縮排縮排每個級別的許多空格。如果indent是一個字串(例如"\t"),則該字串用於縮排每個級別。
sort_keys:
如果sort_keys為true,則字典的輸出將按鍵排序。(預設值:)False
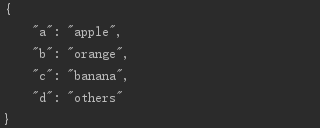
import json dic = dic = {'a':'apple','b':'orange','c':'banana','d':'others'} s = json.dumps(dic,indent='\t',sort_keys=True) print(s)
pickle模組
json & pickle 模組
用於序列化的兩個模組
- json,用於字串和Python資料型別間進行轉換
- pickle,用於python特有的型別和python資料型別間進行轉換
pickle模組提供了四個功能:dumps、dump(序列化,存)、loads(反序列化,讀)、load (不僅可以序列化字典,列表...可以把python中任意的資料型別序列化)
import pickle dic = {'red':'apple','yellow':'orange'} s = pickle.dumps(dic) print(type(s),s)#二進位制bytes型別 s1 = pickle.loads(s) print(type(s1),s1)

import pickle import time struc_time = time.localtime(150) print(struc_time) f = open('pickle_file','wb')#要以bytes型別寫進檔案 pickle.dump(struc_time,f) f.close() f = open('pickle_file','rb') struc_time1 = pickle.load(f) print(struc_time1)

既然pickle如此強大,為什麼還要學json呢?
說明一下,json是一種所有的語言都可以識別的資料結構。
如果我們將一個字典或者序列化成了一個json存在檔案裡,那麼java程式碼或者js程式碼也可以拿來用。
但是如果用pickle進行序列化,其他語言就不能讀懂這是什麼了~
所以,如果要序列化的內容是列表或者字典,那就最好使用json模組
但如果出於某種原因你不得不序列化其他的資料型別,而未來你還會用python對這個資料進行反序列化的話,那麼就可以使用pickle
shelve模組
shelve是一個簡單的資料儲存方案,類似key-value資料庫,可以很方便的儲存python物件,其內部是通過pickle協議來實現資料序列化。shelve只有一個open()函式,這個函式用於開啟指定的檔案(一個持久的字典),然後返回一個shelf物件。shelf是一種持久的、類似字典的物件。它與“dbm”的不同之處在於,其values值可以是任意基本Python物件--pickle模組可以處理的任何資料。這包括大多數類例項、遞迴資料型別和包含很多共享子物件的物件。keys還是普通的字串。
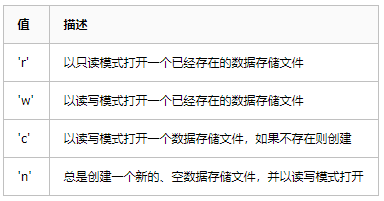
open(filename, flag='c', protocol=None, writeback=False)
flag 引數表示開啟資料儲存檔案的格式,可取值與dbm.open()函式一致:
protocol 引數表示序列化資料所使用的協議版本;
writeback 引數表示是否開啟回寫功能。
我們可以把shelf物件當dict來使用--儲存、更改、查詢某個key對應的資料,當操作完成之後,呼叫shelf物件的close()函式即可。當然,也可以使用上下文管理器(with語句),避免每次都要手動呼叫close()方法。
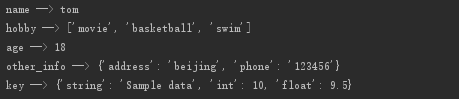
import shelve f = shelve.open('shelve_file') f['key'] = {'int':10, 'float':9.5, 'string':'Sample data'} #直接對檔案控制代碼操作,就可以存入資料 s = f['key'] print(s) f.close()

import shelve f = shelve.open('shelve_file') f['name'] = 'tom' f['age'] = 18 f['hobby'] = ['movie','basketball','swim'] f['other_info'] = {'phone':'123456','address':'beijing'} f.close() with shelve.open('shelve_file') as f: for key,value in f.items(): print(key,'-->',value)
pass