
Garena黃智凱:利用Docker構建自動化運維
黃智凱:Docker構建自動化運維
講師簡介
來自新加坡最大的網際網路公司Garena,曾就職於新浪和奇虎360,DBA背景成長的他同時一直致力於運維平臺自動化的建設和創新。
大家可能對Garena比較陌生,Garena最開始做遊戲運營,現在在東南亞市場上也有了很多自己的產品,包括一些社交軟體和最近很火的直播,同時也有在做電商平臺。
分享主題:利用Docker構建自動化運維

首先介紹一下我們的平臺生態圈,最核心的是中間部分,最初平臺是用來跑Web服務的,所以我們以Jenkins作為核心部署元件管理Docker容器。Docker容器是在swarm節點也就是swarm叢集。Swarm,Compose,Machine三個元件可以用來做雲集群管理。這三大元件我們唯一沒有使用的是machine,因為machine的主要優勢是在公有云上調動API建立雲主機。我們有自己的IDC,所以沒用Machine,出於安全考慮,我們用Docker Registry,它可以實現版本控制,也可以控制機器上的打包。
右邊是整個生態圈中的監控系統,主要跟大家介紹一下Consul,Consul是一個分散式高可用系統。和同類產品比如zookeeper相比,它的優勢就是提供完善的Http和DNS介面,由於Consul服務的重要性,我們不允許出現任何故障,於是部署了三臺節點,他們互相時間實現仲裁,保證在某一個節點宕機的情況下,依然會正確選舉出Leader,整個叢集依然是可用的。從開始平臺只跑Web網站,後來擴充套件到快取等,所有服務都是高可用的。
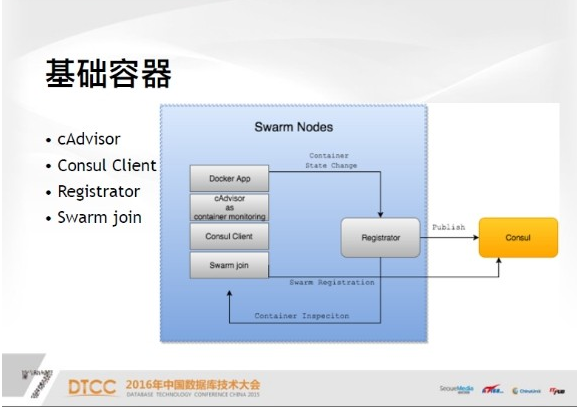
接下來介紹叢集的基礎節點——Swarm節點,你可以認為是宿主機,每一臺宿主機都有基礎的雲伺服器支撐。服務技術單元是每個Docker APP,可以是主站也可以是任何服務。只要定義好,就可以直接註冊到Consul裡。接下來介紹一些基礎容器,一是cAdvisor,這是谷歌提供的一款監控軟體,應該算比較成熟的監控軟體。
二是Consul Client,實際上這不是必要的,如果以後叢集規模擴大,Consul服務端有可能會成為瓶頸,因為如果大量的Swarm節點都向Consul查詢,會給主伺服器帶來很多壓力,本地區的Consul服務延時更小,也能減少伺服器的壓力。
再說Swarm join,它的作用是把節點註冊到整個叢集,你可以認為整個叢集是一個抽象的資源池。最重要的基礎容器是Registrator,這之中有很多關於伺服器的工具,都是高可用服務生命週期,如果發生變化,會把容器資訊註冊到consul中。簡單的說就是拿到容器的元資料,元資料包括三點,一是分離,二是容器在宿主機上的IP,三是容器在主機上的監聽,把這三個註冊到consul中,後續就可以從儲存中拿到Docker的所有元資料。
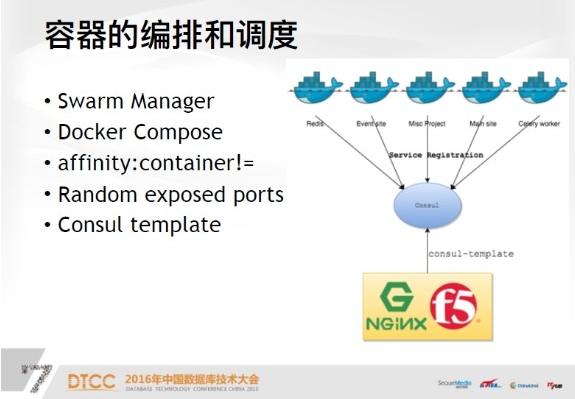
接下來說容器的編排和排程,先說Swarm Manager,可以認為是一個指揮官也就是管理機。
下面是Docker Compose,後面有一個配置檔案的sample,所以說每一個Docker服務啟動之後,就會有一個隨機的服務埠,這個資訊會註冊到consul裡面,此時會有一個工具Consul template,是官方提供的一個工具。
他可以查詢你的服務名,依據我們目前的標準,一個服務名對應是一個網站的域名,到後端查詢這個域名,就知道Docker服務是跑在哪些節點上了,將源資料從consul中取出來之後,template一個新的配置檔案並放到Nginx proxy上實現負載均衡。

下面說一下配置管理Ansible,做專案之前,我們已經有了將近一年的使用經驗。所以做這個時寫了一些任務,上手也很快。比如說建立映象,不同的專案上線,要給它不同的映象,像Python網站需要不同的依賴,我就會給它很多不同的映象。
它是有版本控制的,版本控制的好處就是如果現在打了一個新的映象,上線有問題的話,可以直接回滾到上一個版本,這是映象回滾,下面還會介紹程式碼是如何回滾的。
第二步,初始化伺服器,你只需要輸入IP,基礎服務就可以裝好,基礎環境就已經配置完成。第三步是程式碼同步,第四步是新增監控及Dashboard。

下面就說一下測試環境和線上環境,因為這個最初是做web的,所以每個都是以域名為單元。
當時就想著如果做測試和線上分離的環境怎麼辦,定義的標準就是域名前加一個test域名。這個IP在訪問控制上只限制在內部網站上可以訪問,所以實現分離就是使用不同的consul叢集,我們有線上consul叢集和測試consul叢集。
如果你要呼叫Ansible去配置管理它們的話,只需要給不同的consul叢集不同的引數,比如要重新整理配置的話,你給一個測試環境的consul叢集,它取到的元資料肯定跟你線上取到的不一樣,所以同一個Ansible任務可以管理兩套環境。
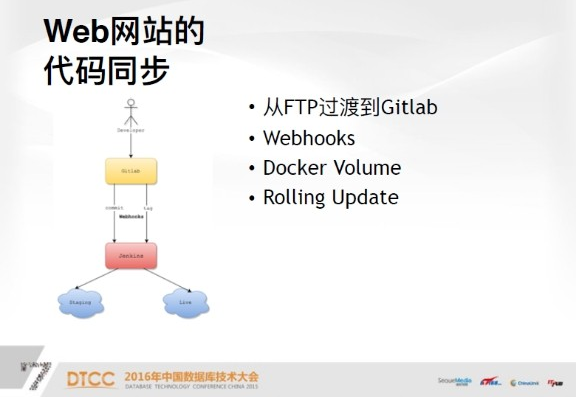
下面說一下web網站的程式碼同步,最開始我們是使用FTP,專案user根據域名定義。這樣就導致如果一個人管理很多域名的話,就會收到很多不同的FTP使用者名稱和密碼。所以最後我們把這套網站移到了Gitlab上,Gitlab提供了一個很友好的功能,它提供的Webhooks可以很好的解決運維和開發之間的隔離,相當於釋出網站程式碼時,運維完全不需要干預任何事,一旦網站上線,它就可以開心地去寫程式碼,上線是通過兩個Webhooks,commit和tag,這是Gitlab自帶的兩個hook,這兩個hook在提交程式碼時,會自動觸發jenkins任務,它會在測試環境上部署程式碼。如果你在Gitlab上直接打tag,它會在live環境部署程式碼,所以運維完全不需要干預整個過程。
下面是Docker Volume,它的概念就是,首先我把web虛擬機器上的目錄對映到容器中,這樣的好處是程式碼上線的話,半分鐘之內在線上或測試就可以實現程式碼同步,而且開發寫程式碼時,每天可以commit很多次,每一次都能及時看到測試環境程式碼所反映的效果。如果將程式碼打入映象,它的劣勢是打的時間成本太長,回滾起來也可能相對慢一些。如果使用volume的話,可以把日誌打到宿主機上,這樣可以直接收到日誌的實時反饋,因為Docker天生是沒有SSH的,很多開發者開始會跟我們抱怨,就想查一個問題,但是看不到任何日誌,不好debug。所以我們解決開發者的痛點,讓開發者在網站上能夠實時看到日誌。
第四是Rolling Update,這在靜態網站中是不存在的,很多網站需要重啟服務才能看到改動。這樣的話,首先因為後端有多個容器,先把第一個容器stop掉,然後再重新整理配置,永遠保證後端是有容器提供服務的。這樣的話來回三次,做到程式碼的平滑升級,這就是Rolling Update。
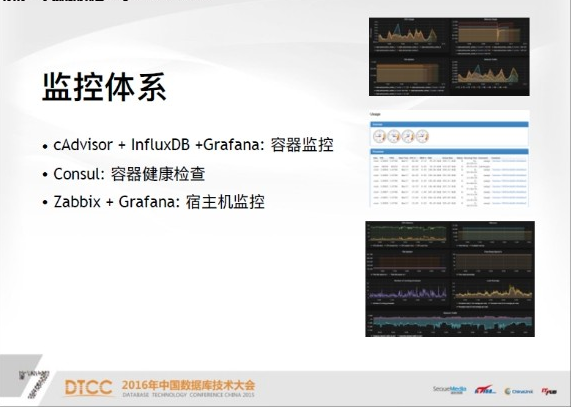
下面說一下監控,監控是容器的監控,是cAdvisor、influxDB和Grafana,如果大家對容器熟的話,會知道這是一個比較成熟的方案。這個圖就是我們以容器維度來看每一個容器的健康狀況,CPU記憶體等情況,這個圖中的服務,可以看到有五個容器來支撐,一般來說,五個容器是負載均衡的,所以看到的曲線相對來說差不多一致。
下面是cAdvisor監控,從宿主機的維度來看,有很多Docker服務,因為這個頁面很長,我只截取了最上面的部分,其實可以從每一個點看子容器的各個狀態。第三就是宿主機監控,這個監控是取得Zabbix資料來源。所以你可以看到CPU記憶體,網路負載等你所關心的情況,可以看到當前資料反映出宿主機大概是一個什麼樣的情況。
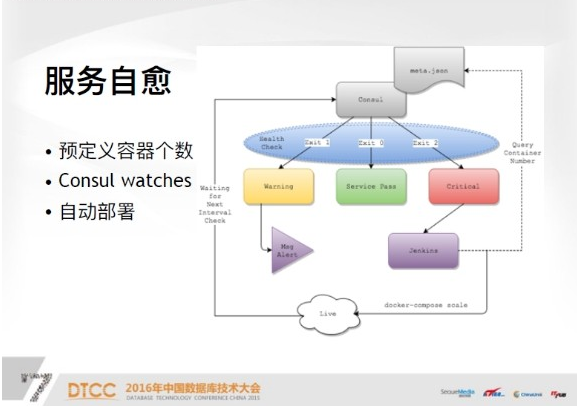
服務自愈是比較關鍵的部分,服務自愈主要有三個概念,第一需要定義容器部署,比如你的系統現在需要三個容器支撐,或者是四個,或者是兩個,一般來說至少兩個,這是用Json檔案定義在監控機上的,你定義一個服務名,這個服務需要多少容器支撐,這個時限是使用Consul Watches也就是健康檢查,健康檢查有三個狀態,指令碼可以自己寫,自己定義,如果你的訪問碼是0,就是Service正常狀態,如果訪問碼是1,就是warning狀態,如果訪問碼是2,就是critical狀態。
首先訪問碼是1,比如說我現在自定義一種情況,假設線上跑的容器個數超過了預定義容器個數,你認為是資源浪費,所以你現在可以定義warning狀態,你會收到簡訊報警,你可能需要人工干預,到底是什麼問題導致我現在跑的容器比我想要的還多,這種情況一般出現的比較少。主要出現的情況就是critical狀態,也就是典型的一臺宿主機掛掉了,之後上面所有的容器,比如說跑了幾十個容器全部掛掉了,所以在進行下一次Consul健康檢查時,會發現你的服務沒有達到預期的定義,這時候就會收到watches,執行服務自愈操作。
服務自愈操作首先會檢查當前的Consul叢集,服務或是線上服務是否符合規定的Json檔案格式。如果不符合,就使用Docker Compose Scale,也就是Swarm Manager管理節點,重新調動一個新的容器,這基本上也是秒級建立。所以我們在下一個檢查也就是60秒之後,重新等待Consul的下一次健康檢查。一般來說,如果檢查通過,第一次如果是critical狀態,下一次基本會實現自愈。利用這個功能,你也可以對宿主機進行平滑升級。
比如我們之前做Docker版本升級,從1.8多升到1.9,當時只需要在整個叢集中把宿主機去掉,也就是把基礎容器替換掉或者kill掉,以一種正常的方式把它幹掉之後,只需要把Docker給關掉。這樣在Consul進行下一次檢查時,就會發現很多容器壞掉,然後就會觸發Jenkins重新部署操作。這樣對機器或者軟體包的升級就變得非常簡單。相當於很優雅的離開叢集,升級完之後,再把宿主機加入到叢集就OK了。

下面說一下0.6版本的新特性,我們也是利用這個特性給Regis平臺做高可用方案。之前我也一直在想怎麼做Redis Master/Slave切換,Tag的作用就是動態給某個容器貼標籤,你可以認為這個是角色,這個角色可以是master,也可以是slave,我們改了Registrator,也就是註冊consul服務,讓它支援這個引數。

下面就是對F5的一些操作,右下角是F5的基本配置,這邊是一些語法,首先查詢service name,它會查詢consul服務裡到底有幾個容器提供服務。
如果這些容器有tag master,就會把這個服務設成10,如果是slave,就會設成9,就是說F5永遠會把流量打到Priority-group大的的節點上,也就是F5永遠會把流量打到master上,直到master掛掉或者不響應,F5會自動把流量切到slave上。
所以如果叢集掛掉了,master掛掉了,不用擔心,只需要重啟一個新的容器直接slave off到老的slave上,然後把老的重新打成master,把新的打成slave就OK了。

最後說一下我們遇到的問題,一是Consul Reload,它一直在Github上,有很多人都說這個問題發生的原因是,每次需要更新consul配置,但是觸發Consul Reload的同時,會呼叫watches相當於服務部署指令碼。這個帶來的問題是需要很小心的寫watches指令碼,而不是說Zabbix收到部署任務就去部署,得實際查一下線上環境是不是真的少於標準環境。
二是Zabbix active log,我們是監控Consul,當log達到預值的時候,即使在10分鐘之內,它的狀態沒有發生變化,我們也把log級別調一下,這應該是Zabbix現在也一直存在的。
三是Docker compose,最開始用的時候沒有用Registry,所以每一個目錄底下都會有一個Dockerfile,docker實際上和compose是可以動態建立的,這帶來了一個問題,如果你想把容器擴充套件到兩個或三個的話,它就會直接fail。這是一個先天缺陷,後來我們用docker hub或者內部registry,就比較完美的避免了這個問題。
四是F5,它只使用一個IP地址,一旦服務多了之後,會出現一些連線莫名斷掉的情況,最後查的話,是因為F5上的snat埠已經耗盡。他們讓我建立一個snat池,然後把一些可用的IP加進去,目前有8個IP,算下來有將近50萬連線可以支撐。
我今天的分享到此結束,謝謝大家!