
Hadoop系列之-MapReduce
Hadoop系列之-MapReduce
MapReduce在Hadoop1.x中直接執行在HDFS上,由JobTracker和TaskTracker負責排程。在Hadoop2.x中執行在YARN上。面對大量資料的離線計算,MR無非是很好的選擇,但如果需要高及時性的大資料計算,Spark、Storm是更合適的選擇。MapReduce的核心設計理念是分散式計算,簡單說就是移動計算而不移動資料。
-
基本功能模組
YARN : 負責資源管理和排程
MapReduceApplicationMaster : 負責切分、任務排程、任務監控和容錯等
MapTask/ReduceTask : 任務驅動引擎
-
每個MapReduce作業對應一個MapReduceApplicationMaster,MRAppMaster負責整體任務排程,YARN將資源分配給MRAppMaster,MRAppMaster再將任務分配給MapTask/ReduceTask
-
MapReduceApplicationMaster容錯
失敗後,由YARN重新啟動
任務失敗後,MRAppMaster重新申請資源
概念
-
MapReduce
-
MR整體框架
MR的整個過程由以下構成:
-
Split
將資料按配置好的大小(如一個block是64M將其切分為3份,也就是25M+25M+14M)切分,並傳給不同的MapTask。
-
Map
Map對檔案逐行讀出並解析,解析完畢後以K,V的格式輸出。
-
Shuffle
在交付ReduceTask之前,輸出的過程中可以配置Shuffle,Shuffle可對資料先Sort再Combiner,以減小Reduce的工作量。在ReduceTask端,Shuffle會對資料先進行聚合,相同Key的所有Value會被整合為一個以Key為首的Value陣列
-
Reduce
ReduceTask可根據不同需求對shuffle後的Value陣列進行整合統計。如果一次MR計算不夠,可執行多次計算。

-
-
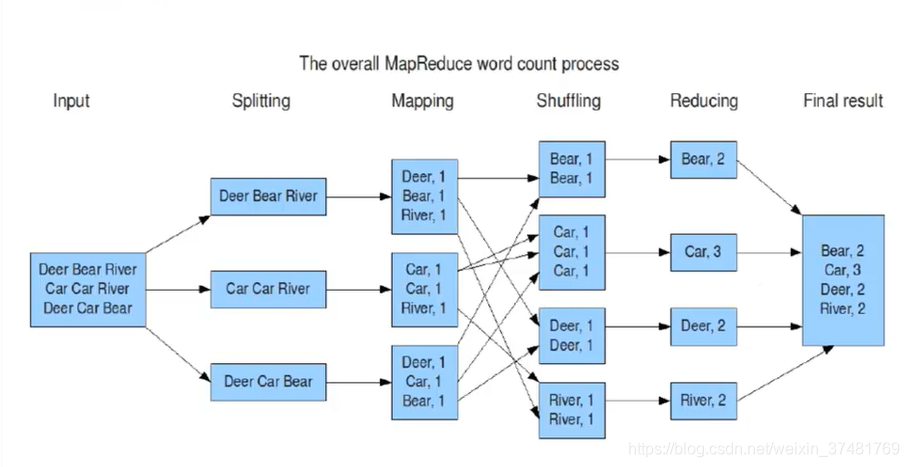
假設有一個檔案儲存這Deer Bear River等word,我們要計算這個檔案中各word的總數,那麼MR的整套過程是這樣的
-
將檔案按大小Split為多份
-
Map階段按行讀入,按K,V的結果集輸出
-
Shuffle對Map後的資料進行Sort、聚合
-
Reduce對Shuffle後的結果進行統計並輸出
-
-
-
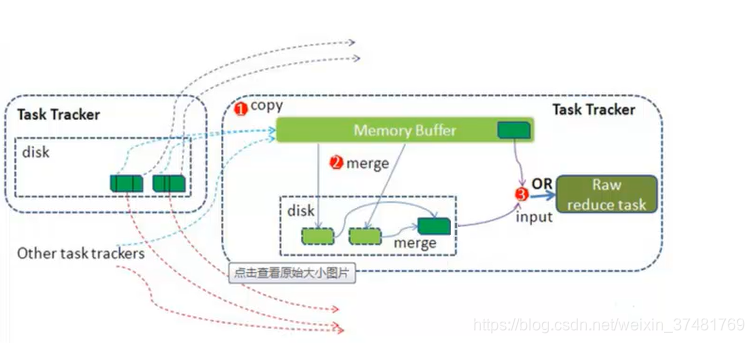
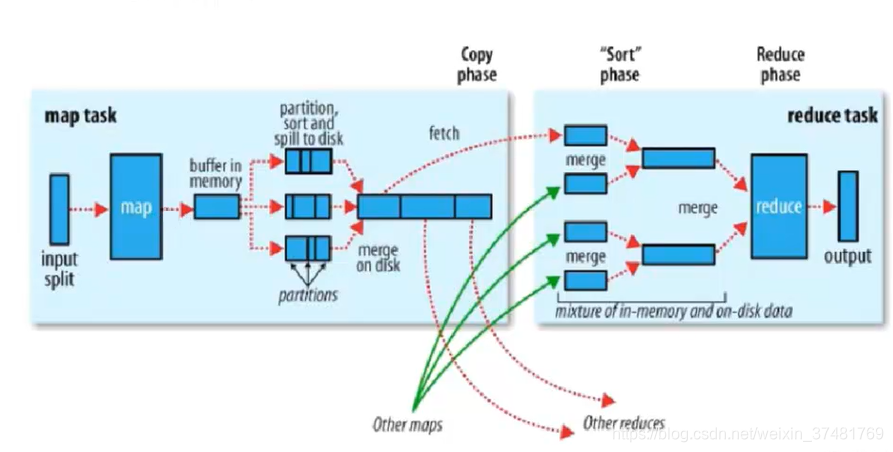
Shuffler
每個MapTask都有一個記憶體緩衝區(預設是100M),儲存著map的輸出結果,當緩衝區快滿的時候需要將緩衝區的資料以一個臨時檔案的方式存放到磁碟,溢寫是由單獨執行緒完成,不影響往緩衝區寫map結果的執行緒(split.percent,預設是0.8)。當溢寫執行緒啟動後,需要對這80M空間內的key做排序(Sort。)
假如client設定過Combiner,那麼現在就是使用Combinerd的時候了。將由相同key的key/value對的value加起來,減少溢寫到磁碟的資料量。
當整個map task結束後在對磁碟中這個map task產生的所有臨時檔案做合併(Merge),對於“word1”就是這樣的:{word1:[5,8,2,…]},假如有Combiner,{word1[15]},最終產生一個檔案。
reduce從tasktracker copy資料,copy過來的資料會先放入記憶體緩衝區中,這裡的緩衝區大小要比map端的更為靈活,它基於JVM的heap size設定。merge有三種形式:記憶體到記憶體,記憶體到磁碟,磁碟到磁碟。merge從不同的task tracker上拿到的資料。
-
Combiner
每一個map可能會產生大量的輸出。combiner的作用就是在map端對輸出先做一次合併,以減少傳輸到reducer的資料量。combiner最基本是實現本地key的歸併,combiner具有類似本地的reduce功能。如果不用combiner,那麼,所有的結果都由reduce完成,效率會相對地下,如果使用combiner,先完成的map會在本地聚合,提升速度。
配置
配置筆者就不在此贅述,有需要可以去讀官網 http://hadoop.apache.org/docs/
MR執行時Hadoop各程序之間的互動
-
客戶端提交一個mr的jar包給JobClient(提交方式:hadoop jar <jar在unix的url> <main方法所在的類的全類名> <引數>)
-
JobClient通過RPC和JobTracker進行通訊,返回一個存放jar包的地址(HDFS)和jobId
-
client將jar包寫入到HDFS當中(path = hdfs上的地址 + jobId)
-
開始提交任務(任務的描述資訊,不是jar, 包括jobid,jar存放的位置,配置資訊等等)
-
JobTracker進行初始化任務
-
讀取HDFS上的要處理的檔案,開始計算輸入分片,每一個分片對應一個MapperTask
-
TaskTracker通過心跳機制領取任務(任務的描述資訊)
-
下載所需的jar,配置檔案等
-
TaskTracker啟動一個java child子程序,用來執行具體的任務(MapperTask或ReducerTask)
-
將結果寫入到HDFS當中
小試牛刀
我們做一個簡單的MapReduce,現在有三個檔案a.txt、b.txt、c.txt,每個檔案中有大量單詞,通過MR計算後,我們要得出的結果是:wordname a.txt->28 b.txt->11 c.txt->22,並將其儲存在一個檔案中
a.txt
name age sex flower
name flower sex age
name flower sex age
name flower sex age
name flower sex age
b.txt
name sex age
name flower sex age
name flower age
flower sex age
name flower sex
c.txt
name flower sex age
name flower sex age
name flower sex age
pom.xml
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.2</version>
<exclusions>
<exclusion>
<artifactId>jdk.tools</artifactId>
<groupId>jdk.tools</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.5.2</version>
<exclusions>
<exclusion>
<artifactId>jdk.tools</artifactId>
<groupId>jdk.tools</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-common</artifactId>
<version>2.5.2</version>
</dependency>
</dependencies>
Java程式碼
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* map+reducce
* 實現倒序索引(計算各個單詞在不同檔案中的個數)
* 輸出結果: word a.txt->28 b.txt->11 c.txt->22
*
* 將 a.txt、b.txt、c.txt傳到 hdfs://host:port/words
* 執行 hadoop jar ./NormalInverseIndex.jar cn.hadoop.Inverse hdfs://host:port/words hdfs://host:port/result
*
*/
public class NormalInverseIndex {
private static Text k = new Text();
private static Text v = new Text();
//
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 設定jar
job.setJarByClass(NormalInverseIndex.class);
// 設定Mapper相關的屬性
job.setMapperClass(IndexMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 設定Reducer相關屬性
job.setReducerClass(IndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// job.setCombinerClass(IndexCombiner.class);
// 提交任務
job.waitForCompletion(true);
}
/**
* output:
* key:word
* value:fileName
*/
public static class IndexMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
StringTokenizer st = new StringTokenizer(value.toString());
String fileName = ((FileSplit) context.getInputSplit()).getPath().getName();
while (st.hasMoreTokens()) {
k.set(st.nextToken());
v.set(fileName);
context.write(k, v);
}
}
}
/**
* output:
* key:word
* value:a.txt->28 b.txt->11 c.txt->22
*/
public static class IndexReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
Map<String, Integer> fileNameMap = new HashMap<String, Integer>();
for (Text fileName : values) {
if (fileNameMap.get(fileName.toString()) == null) {
fileNameMap.put(fileName.toString(), 1);
} else {
fileNameMap.put(fileName.toString(), fileNameMap.get(fileName.toString())+1);
}
}
k.set(key.toString());
String vVal = "";
Set<Entry<String, Integer>> set = fileNameMap.entrySet();
for (Iterator<Entry<String, Integer>> iterator = set.iterator(); iterator.hasNext();) {
Map.Entry<String, Integer> en = iterator.next();
vVal += " "+en.getKey()+"->"+en.getValue().toString();
}
v.set(vVal.substring(1));
context.write(k, v);
}
}
}