最詳細的Storm入門教程(二)
阿新 • • 發佈:2018-12-29
Storm入門例子詳解-單詞計數器
概念
Storm 分散式計算結構稱為 topology(拓撲),由 stream(資料流), spout(資料流的生成者), bolt(運算)組成。
Storm 的核心資料結構是 tuple。 tuple是 包 含 了 一 個 或 者 多 個 鍵 值 對 的 列 表,Stream 是 由 無 限 制 的 tuple 組 成 的 序 列。
spout 代表了一個 Storm topology 的主要資料入口,充當採集器的角色,連線到資料來源,將資料轉化為一個個 tuple,並將 tuple 作為資料流進行發射。
bolt 可以理解為計算程式中的運算或者函式,將一個或者多個數據流作為輸入,對資料實施運算後,選擇性地輸出一個或者多個數據流。 bolt 可以訂閱多個由 spout 或者其他bolt 發射的資料流,這樣就可以建立複雜的資料流轉換網路。
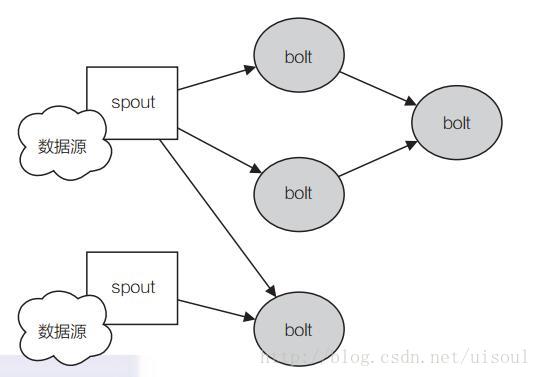
本例子單詞計數 topology 的資料流大概是這樣:

專案搭建
新建類SentenceSpout.java(資料流生成者)
import java.util.Map;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import 新建類SplitSentenceBolt.java(單詞分割器)
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* 訂閱sentence spout發射的tuple流,實現分割單詞
* @author soul
*
*/
public class SplitSentenceBolt extends BaseRichBolt {
//BaseRichBolt是IComponent和IBolt介面的實現
//繼承這個類,就不用去實現本例不關心的方法
private OutputCollector collector;
/**
* prepare()方法類似於ISpout 的open()方法。
* 這個方法在blot初始化時呼叫,可以用來準備bolt用到的資源,比如資料庫連線。
* 本例子和SentenceSpout類一樣,SplitSentenceBolt類不需要太多額外的初始化,
* 所以prepare()方法只儲存OutputCollector物件的引用。
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
// TODO Auto-generated method stub
this.collector=collector;
}
/**
* SplitSentenceBolt核心功能是在類IBolt定義execute()方法,這個方法是IBolt介面中定義。
* 每次Bolt從流接收一個訂閱的tuple,都會呼叫這個方法。
* 本例中,收到的元組中查詢“sentence”的值,
* 並將該值拆分成單個的詞,然後按單詞發出新的tuple。
*/
public void execute(Tuple input) {
// TODO Auto-generated method stub
String sentence = input.getStringByField("sentence");
String[] words = sentence.split(" ");
for (String word : words) {
this.collector.emit(new Values(word));//向下一個bolt發射資料
}
}
/**
* plitSentenceBolt類定義一個元組流,每個包含一個欄位(“word”)。
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
declarer.declare(new Fields("word"));
}
}
新建類WordCountBolt.java(單詞計數器)
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
/**
* 訂閱 split sentence bolt的輸出流,實現單詞計數,併發送當前計數給下一個bolt
* @author soul
*
*/
public class WordCountBolt extends BaseRichBolt {
private OutputCollector collector;
//儲存單詞和對應的計數
private HashMap<String, Long> counts = null;//注:不可序列化物件需在prepare中例項化
/**
* 大部分例項變數通常是在prepare()中進行例項化,這個設計模式是由topology的部署方式決定的
* 因為在部署拓撲時,元件spout和bolt是在網路上傳送的序列化的例項變數。
* 如果spout或bolt有任何non-serializable例項變數在序列化之前被例項化(例如,在建構函式中建立)
* 會丟擲NotSerializableException並且拓撲將無法釋出。
* 本例中因為HashMap 是可序列化的,所以可以安全地在建構函式中例項化。
* 但是,通常情況下最好是在建構函式中對基本資料型別和可序列化的物件進行復制和例項化
* 而在prepare()方法中對不可序列化的物件進行例項化。
*/
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
// TODO Auto-generated method stub
this.collector = collector;
this.counts = new HashMap<String, Long>();
}
/**
* 在execute()方法中,我們查詢的收到的單詞的計數(如果不存在,初始化為0)
* 然後增加計數並存儲,發出一個新的詞和當前計陣列成的二元組。
* 發射計數作為流允許拓撲的其他bolt訂閱和執行額外的處理。
*/
public void execute(Tuple input) {
// TODO Auto-generated method stub
String word = input.getStringByField("word");
Long count = this.counts.get(word);
if (count == null) {
count = 0L;//如果不存在,初始化為0
}
count++;//增加計數
this.counts.put(word, count);//儲存計數
this.collector.emit(new Values(word,count));
}
/**
*
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
//宣告一個輸出流,其中tuple包括了單詞和對應的計數,向後發射
//其他bolt可以訂閱這個資料流進一步處理
declarer.declare(new Fields("word","count"));
}
}新建類ReportBolt.java(報告生成器)
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
/**
* 生成一份報告
* @author soul
*
*/
public class ReportBolt extends BaseRichBolt {
private HashMap<String, Long> counts = null;//儲存單詞和對應的計數
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
// TODO Auto-generated method stub
this.counts = new HashMap<String, Long>();
}
public void execute(Tuple input) {
// TODO Auto-generated method stub
String word = input.getStringByField("word");
Long count = input.getLongByField("count");
this.counts.put(word, count);
//實時輸出
System.out.println("結果:"+this.counts);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// TODO Auto-generated method stub
//這裡是末端bolt,不需要發射資料流,這裡無需定義
}
/**
* cleanup是IBolt介面中定義
* Storm在終止一個bolt之前會呼叫這個方法
* 本例我們利用cleanup()方法在topology關閉時輸出最終的計數結果
* 通常情況下,cleanup()方法用來釋放bolt佔用的資源,如開啟的檔案控制代碼或資料庫連線
* 但是當Storm拓撲在一個叢集上執行,IBolt.cleanup()方法不能保證執行(這裡是開發模式,生產環境不要這樣做)。
*/
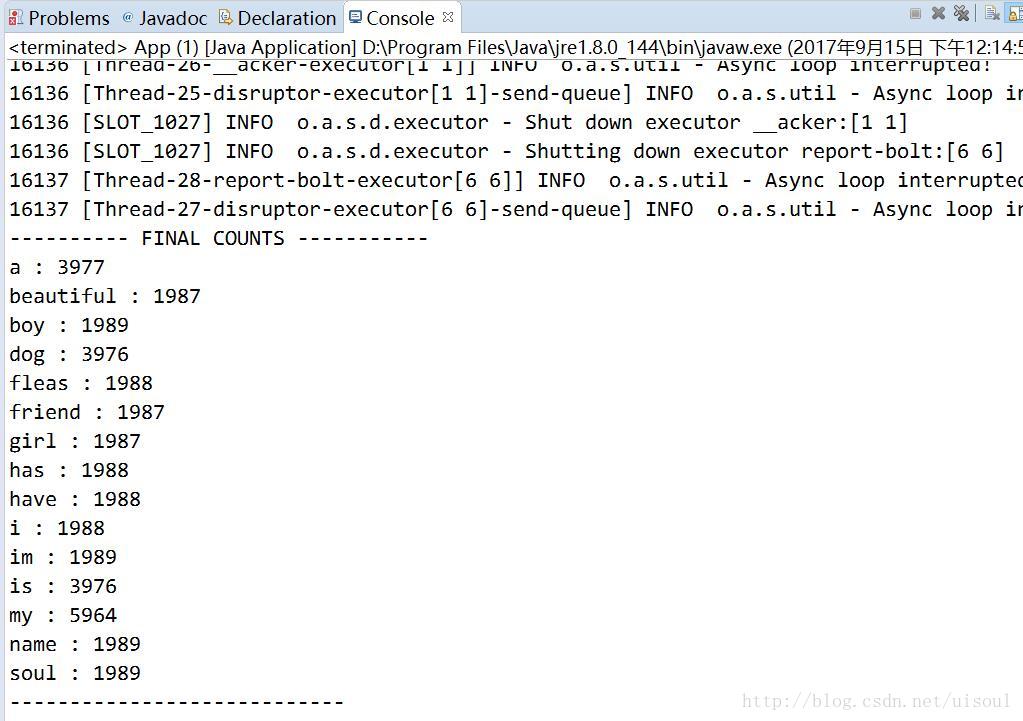
public void cleanup(){
System.out.println("---------- FINAL COUNTS -----------");
ArrayList<String> keys = new ArrayList<String>();
keys.addAll(this.counts.keySet());
Collections.sort(keys);
for(String key : keys){
System.out.println(key + " : " + this.counts.get(key));
}
System.out.println("----------------------------");
}
}修改程式主入口App.java
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import org.apache.storm.utils.Utils;
/**
* 實現單詞計數topology
*
*/
public class App
{
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main( String[] args ) //throws Exception
{
//System.out.println( "Hello World!" );
//例項化spout和bolt
SentenceSpout spout = new SentenceSpout();
SplitSentenceBolt splitBolt = new SplitSentenceBolt();
WordCountBolt countBolt = new WordCountBolt();
ReportBolt reportBolt = new ReportBolt();
TopologyBuilder builder = new TopologyBuilder();//建立了一個TopologyBuilder例項
//TopologyBuilder提供流式風格的API來定義topology元件之間的資料流
//builder.setSpout(SENTENCE_SPOUT_ID, spout);//註冊一個sentence spout
//設定兩個Executeor(執行緒),預設一個
builder.setSpout(SENTENCE_SPOUT_ID, spout,2);
// SentenceSpout --> SplitSentenceBolt
//註冊一個bolt並訂閱sentence發射出的資料流,shuffleGrouping方法告訴Storm要將SentenceSpout發射的tuple隨機均勻的分發給SplitSentenceBolt的例項
//builder.setBolt(SPLIT_BOLT_ID, splitBolt).shuffleGrouping(SENTENCE_SPOUT_ID);
//SplitSentenceBolt單詞分割器設定4個Task,2個Executeor(執行緒)
builder.setBolt(SPLIT_BOLT_ID, splitBolt,2).setNumTasks(4).shuffleGrouping(SENTENCE_SPOUT_ID);
// SplitSentenceBolt --> WordCountBolt
//fieldsGrouping將含有特定資料的tuple路由到特殊的bolt例項中
//這裡fieldsGrouping()方法保證所有“word”欄位相同的tuuple會被路由到同一個WordCountBolt例項中
//builder.setBolt(COUNT_BOLT_ID, countBolt).fieldsGrouping( SPLIT_BOLT_ID, new Fields("word"));
//WordCountBolt單詞計數器設定4個Executeor(執行緒)
builder.setBolt(COUNT_BOLT_ID, countBolt,4).fieldsGrouping( SPLIT_BOLT_ID, new Fields("word"));
// WordCountBolt --> ReportBolt
//globalGrouping是把WordCountBolt發射的所有tuple路由到唯一的ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID);
Config config = new Config();//Config類是一個HashMap<String,Object>的子類,用來配置topology執行時的行為
//設定worker數量
//config.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
//本地提交
cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology(TOPOLOGY_NAME);
cluster.shutdown();
}
}執行程式,可看到單詞計數實時輸出效果

執行10秒後生成報告