
Scryer: Netflix’s Predictive Auto Scaling Engine
Scryer: Netflix’s Predictive Auto Scaling Engine


To deliver the best possible experience to Netflix customers around the world, it is critical for us to maintain a robust, scalable, and resilient system. That is why we have built (and open sourced) applications ranging from Hystrix to Chaos Monkey. All of these tools better enable us to prevent or minimize outages, respond effectively to outages, and/or anticipate the kinds of operational gaps that may eventually result in outages. Recently we have built another such tool that has been helping us in this ongoing challenge:
Scryer is a new system that allows us to provision the right number of AWS instances needed to handle the traffic of our customers. But Scryer is different from Amazon Auto Scaling (AAS), which reacts to real-time metrics and adjusts instance counts accordingly. Rather, Scryer predicts what the needs will be prior to the time of need and provisions the instances based on those predictions.
This post is the first in a series that will provide greater details on what Scryer is, how it works, how it differs from the Amazon Auto Scaling, and how we employ it at Netflix.
Amazon Auto Scaling and the Netflix Use Case
At the core, AAS is a reactive auto scaling model. That is, AAS dynamically adjusts server counts based on a cluster’s current workload (most often the metric of choice will be something like
For Netflix, however, there are a range of use cases that are not fully addressed by AAS. The following are some examples:
- Rapid spike in demand: Instance startup times range from 10 to 45 minutes. During that time our existing servers are vulnerable, especially if the workload continues to increase.
- Outages: A sudden drop in incoming traffic from an outage is sometimes followed by a retry storm (after the underlying issue has been resolved). A reactive system is vulnerable in such conditions because a drop in workload usually triggers a down scale event, leaving the system under provisioned to handle the ensuing retry storm.
- Variable traffic patterns: Different times of the day have different workload characteristics and fleet sizes. Some periods show a rapid increase in workload with a relatively small fleet size (20% of maximum), while other periods show a modest increase with a fleet size 80% of the maximum, making it difficult to handle such variations in optimal ways.
Some of these issues can be mitigated by scaling up aggressively, but this is often undesirable as it may lead to scale up — scale down oscillations. Another option is to always run more servers than required which is clearly not optimal from a cost perspective.
Scryer: Our Predictive Auto Scaling Engine
Scryer was inspired in part by these unaddressed use cases, but its genesis was triggered more by our relatively predictable traffic patterns. The following is an example of five days worth of traffic:

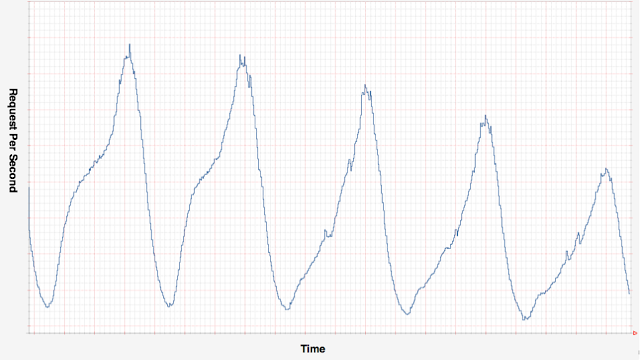
In this chart, there are very clearly spikes and troughs that sync up with consistent patterns and times of day. There are definitely going to be spikes and valleys that we cannot predict and the traffic does evolve over longer periods of time. That said, over any given week or month, we have a very good idea of what the traffic will look like as the basic curves are the same. Moreover, these same five days of the week are likely to have the same patterns the week before and the week after (assuming no outages or special events).
Because of these trends, we believed that we would be able to generate a set of algorithms that could predict our capacity needs before our actual needs, rather than simply relying on the reactive model of AAS. The following chart shows the result of that effort, which is that the output from our prediction algorithms aligns very closely to our actual metrics.

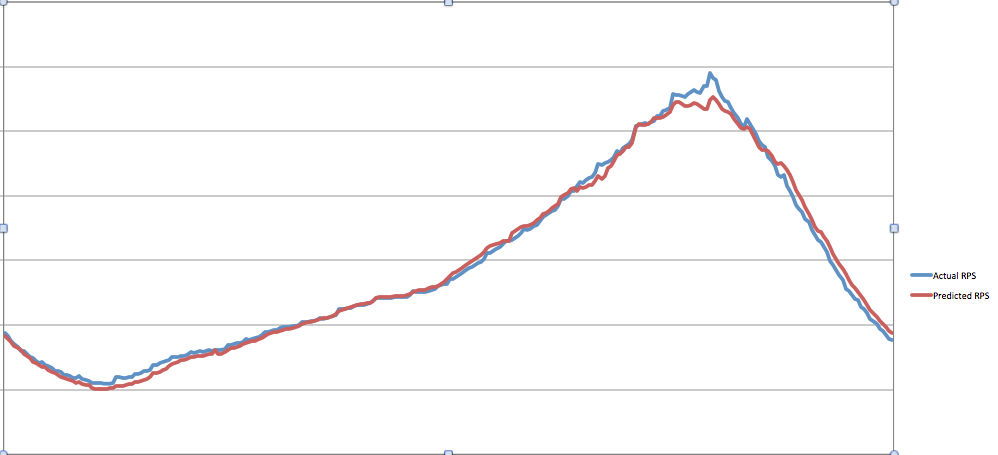
Once these predictions were optimized, we attached these predictions to AWS APIs to trigger changes in capacity needs. The following chart shows that our scheduled scaling action plan closely matches our actual traffic with each step minimized to achieve best performance.

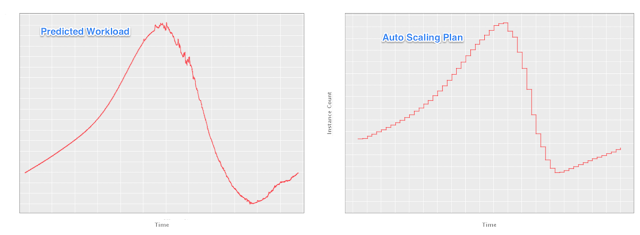
We have been running Scryer in production for a few months. The following is a list of the key benefits that we have seen with it:
- Improved cluster performance
- Better service availability
- Reduced EC2 costs
Predictive-Reactive Auto Scaling — A Hybrid Approach
As effective as Scryer has been in predicting and managing our instance counts, the real strength of Scryer is in how it operates in tandem with AAS’s reactive model.
If we are able to predict the workload of a cluster in advance, then we can proactively scale the cluster ahead of time to accurately meet workload needs. But there will certainly be cases where Scryer cannot predict our needs, such as an unexpected surge in workload. In these cases, AAS serves as an excellent safety net for us, adding instances based on those unanticipated, unpredicted needs.
The two auto scaling systems combined provide a much more robust and efficient solution as they complement each other.
Conclusion
Overall, Scryer has been incredibly effective at predicting our metrics and traffic patterns, allowing us to better manage our instance counts and stabilizing our systems. We are still rolling this out to the breadth of services within Netflix and will continue to explore its use cases and optimize the algorithms. So far, though, we are excited about the results and are eager to see how it behaves in different environments and conditions.
In the coming weeks, we plan to publish several more posts discussing Scryer in greater detail, digging deeper into its features, design, technology and algorithms. We are exploring the possibility of open sourcing Scryer in the future as well.
Finally, we work on these kinds of exciting challenges all the time at Netflix. If you would like to join us in tackling such problems, check out our Jobs site.