
Java jdbc批量多執行緒讀取CVS檔案入庫效能優化篇
阿新 • • 發佈:2018-12-29
在寫完上一篇文章之後,在使用過程中慢慢發現一些問題,比如說資料入庫很慢,10W的資料分10個檔案入庫大概需要兩三分鐘,如下圖
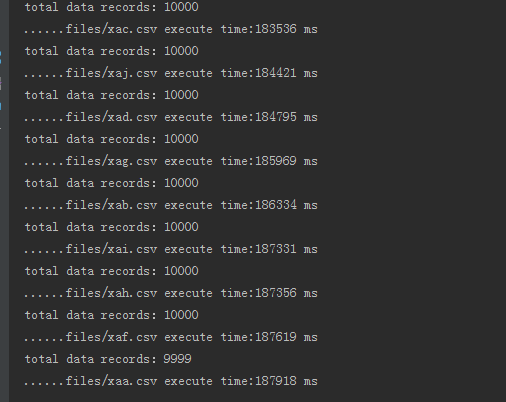
這是我忍受不了的,所以我尋思著如何優化該程式,提高入庫效能。因此我對JDBC資料入庫的幾種方法做了一個對比,在大量的實驗下,發現瞭如下的規律:
1、使用statement耗時最長;
2、使用PreparedStatement耗時明顯縮短;
3、使用PreparedStatement + 批處理耗時暫時耗時最少。
針對我的小程式,入庫的表所需要的欄位有上百個,我懶得去拼字串,於是就選擇Statement+批處理來處理,關鍵程式碼如下:
if(conn == null 然而程式入庫的效率並沒有顯著的提高,最後,我在批量執行500條Sql的時候提交一次,程式碼如下:
if(rowCount % 500 == 0) {
pre.executeBatch();
conn.commit();
// pre.clearBatch();
}這裡的數字是自己定的,根據Java虛擬機器大小來設定不同的值,這裡的clearBatch()執行不執行都可以,在設定為100的時候,效率如下:
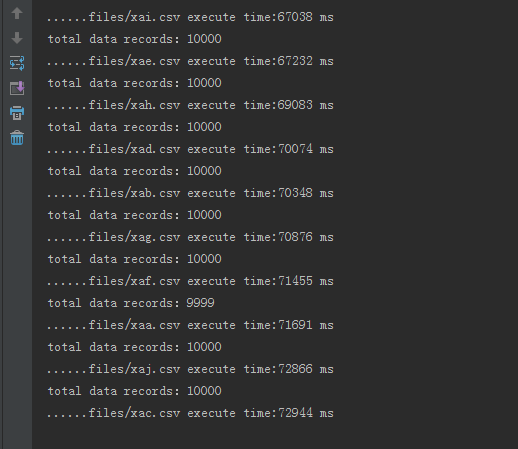
回顧本文最開始10W條資料分十個檔案入庫,效率明顯提升了不少。