
Small U-Net for vehicle detection
Model:
The model we chose is is a scaled down version of a deep learning architecture called U-net. U-net is a encoder-decoder type network architecture for image segmentation. The name of the architecture comes from its unique shape, where the feature maps from convolution part in downsampling step are fed to the up-convolution part in up-sampling step. U-net has been used extensively for biomedical applications to detect cancer, kidney pathologies and tracking cells etc. U-net has proven to be very powerful segmentation tool in scenarios with limited data (less than 50 training samples in some cases). Another advantage of using a U-net is that it does not have any fully connected layers, therefore has no restriction on the size of the input image. This feature allows us to extract features from images of different sizes, which is an attractive attribute for applying deep learning to high fidelity biomedical imaging data. The ability of U-net to work with very little data and no specific requirement on input image size make it a strong candidate for image segmentation tasks.
Another reason to choose the U-net architecture is the letter U. As the data set was provided by Udacity and as am currently enrolled in Udacity’s self-driving car, choice of U-net was a fitting tribute to Udacity.
The input to U-net is a resized 960X640 3-channel RGB image and output is 960X640 1-channel mask of predictions. We wanted the predictions to reflect probability of a pixel being a vehicle or not, so we used an activation function of sigmoid on the last layer.
Training:
As with any segmentation deep learning neural network, training took long time. We were unable to fit data set with batch size more than 1 on a titan X gpu with the full U-net, we therefore decided to choose a batch size of 1 for all architectures. This 1 image was randomly samples and augmented from all training images. As we chose a batch size of 1, we chose adam optimizer with a learning rate of 0.0001. Setting up the training itself was straight forward, but training the segmentation model made my Titan X gpu cringe. To perform 10000 iterations, my titan X machine took about 20 minutes.

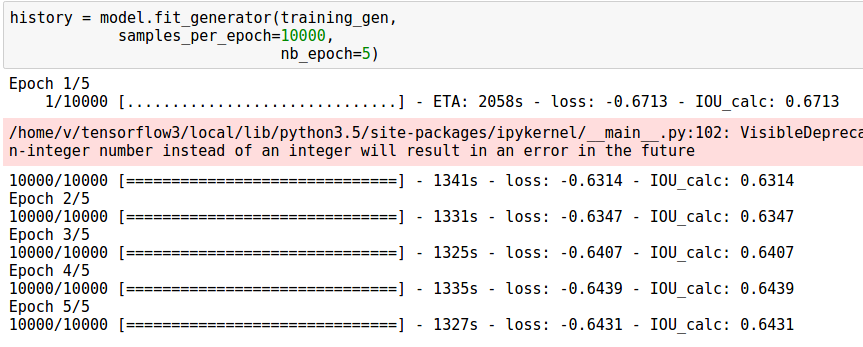
Objective:
We defined a custom objective function in keras to compute approximate Intersection over Union (IoU) between the network output and target mask. IoU is a popular metric of choice for tasks involving bounding boxes. The objective was to maximize IoU, as IoU always varies between 0 and 1, we simply chose to minimize the negative of IoU.

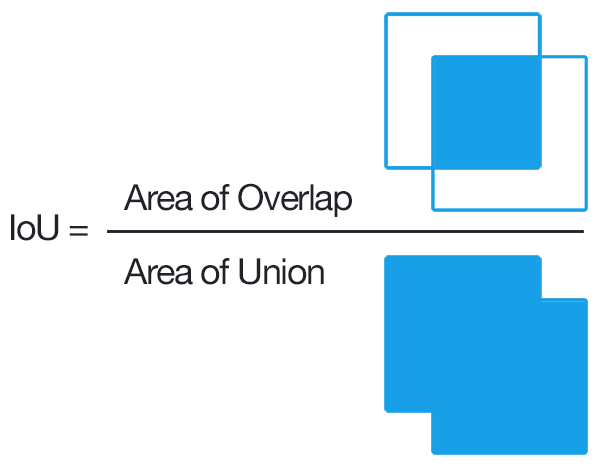
Instead of implementing a direct computation for intersection over union or cross entropy, we used a much simpler metric for area where we multiply two times the network’s output with the target mask, and divide it by the sum of all values in the predicted output and the true mask. This trick helped us avoid computationally involved area calculations, which resulted in lower training times.
Results:
We stopped the training after 2 hours, and decided to use the network to make predictions. In test time, no augmentation was applied for prediction. The algorithm was surprisingly fast. It took 200ms to make 10 predictions (average of 20ms per image), this included reading file off of disk, and drawing the blobs.
Figures below present performance of the model for vehicle detection. It was surprising that the neural network was able to identify cars correctly in the driving frames it did not see before. Figures below present result of segmentation algorithm applied for vehicle predictions. The panels are organized as original image, predicted mask and ground truth boxes.