機器學習中的PR曲線和ROC曲線
主要是我對周志華《機器學習》第二章模型估計與選擇中一些內容的總結
1.查準率、查全率和F1
對於二分類問題,可將樣例根據其真實類別與學習器預測類別的組合劃分為真正例(TP),假反例(FN),假正例(FP),真反例(TN),具體分類結果如下

查準率P和查全率R分別定義為:

查準率關心的是”預測出正例的正確率”即從正反例子中挑選出正例的問題。
查全率關心的是”預測出正例的保證性”即從正例中挑選出正例的問題。
這兩者是一對矛盾的度量,查準率可以認為是”寧缺毋濫”,適合對準確率要求高的應用,例如商品推薦,網頁檢索等。查全率可以認為是”寧錯殺一百,不放過1個”,適合類似於檢查走私、逃犯資訊等。
下圖為查準率-查全率曲線(P-R圖)
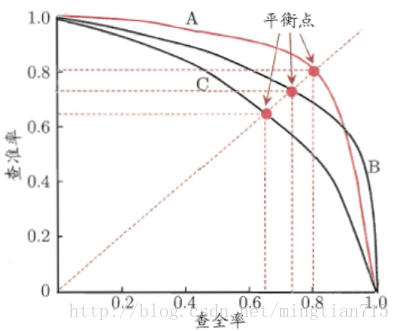
若一個學習器的P-R曲線被另一個學習器完全”包住”,則後者的效能優於前者。當存在交叉時,可以計算曲線圍住面積,但比較麻煩,平衡點(查準率=查全率,BEP)是一種度量方式。
但BEP還是過於簡化了些,更常用的是F1和Fp度量,它們分別是查準率和查全率的調和平均和加權調和平均。定義如下




顯然,當學習器A的F1值比學習器高,那麼A的BEP值也比B高(將P=R代入F1公式即可)
2.ROC和AUC
很多學習器是為測試樣本產生一個實值或概率預測,然後將這個預測值與一個分類閾值進行比較,若大於閾值分為正類,否則為反類,因此分類過程可以看作選取一個截斷點。
不同任務中,可以選擇不同截斷點,若更注重”查準率”,應選擇排序中靠前位置進行截斷,反之若注重”查全率”,則選擇靠後位置截斷。因此排序本身質量的好壞,可以直接導致學習器不同泛化效能好壞,ROC曲線則是從這個角度出發來研究學習器的工具。
曲線的座標分別為真正例率(TPR)和假正例率(FPR),定義如下

下圖為ROC曲線示意圖,因現實任務中通常利用有限個測試樣例來繪製ROC圖,因此應為無法產生光滑曲線,如右圖所示。

繪圖過程很簡單:給定m個正例子,n個反例子,根據學習器預測結果進行排序,先把分類閾值設為最大,使得所有例子均預測為反例,此時TPR和FPR均為0,在(0,0)處標記一個點,再將分類閾值依次設為每個樣例的預測值,即依次將每個例子劃分為正例。設前一個座標為(x,y),若當前為真正例,對應標記點為(x,y+1/m),若當前為假正例,則標記點為(x+1/n,y),然後依次連線各點。
下面舉個繪圖例子:
有10個樣例子,5個正例子,5個反例子。有兩個學習器A,B,分別對10個例子進行預測,按照預測的值(這裡就不具體列了)從高到低排序結果如下:
A:[反正正正反反正正反反]
B : [反正反反反正正正正反]
按照繪圖過程,可以得到學習器對應的ROC曲線點
A:y:[0,0,0.2,0.4,0.6,0.6,0.6,0.8,1,1,1]
x:[0,0.2,0.2,0.2,0.2,0.4,0.6,0.6,0.6,0.8,1]
B:y:[0,0,0.2,0.2,0.2,0.2,0.4,0.6,0.8,1,1]
x:[0,0.2,0.2,0.4,0.6,0.8,0.8,0.8,0.8,0.8,1]
繪製曲線結果如下:

藍色為學習器A的ROC曲線,其包含了B的曲線,說明它效能更優秀,這點從A,B對10個例子的排序結果顯然是能看出來的,A中正例排序高的數目多於B。此外,如果兩個曲線有交叉,則需要計算曲線圍住的面積(AUC)來評價效能優劣。
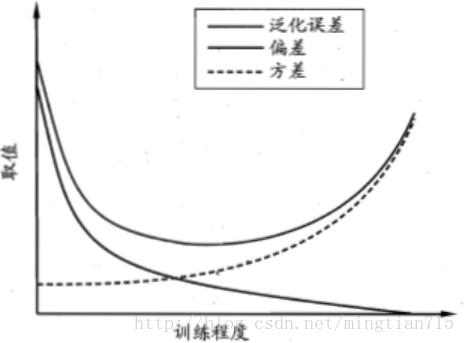
3.偏差和方差
泛化誤差可以分解為偏差、方差與噪聲之和
偏差度量了學習演算法的期望預測和真實結果偏離程度。
方差度量了同樣大小的訓練集的變動所導致的學習效能的變化,即刻畫了資料擾動所造成的影響。
噪聲可以認為資料自身的波動性,表達了目前任何學習演算法所能達到泛化誤差的下限。
偏差大說明欠擬合,方差大說明過擬合。