
詳解SQL語句的集合運算
以前總是追求新東西,發現基礎才是最重要的,今年主要的目標是精通SQL查詢和SQL效能優化。
概述
本篇主要是對集合運算中並集、交集、差集運算基礎的總結。
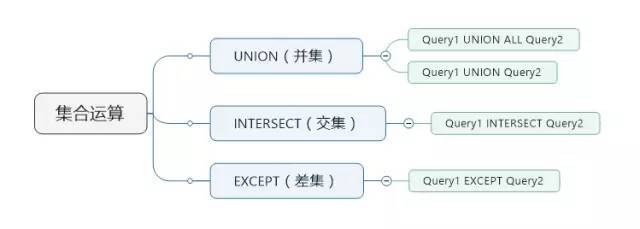
集合運算包含四種:
1.並集運算(兩種)
2.交集運算
3.差集運算
下面是集合運算的思維導圖:
為什麼使用集合運算
1.在集合運算中比聯接查詢和EXISTS/NOT EXISTS更方便。
在閱讀下面的章節時,我們可以先把環境準備好,以下的SQL指令碼可以幫助大家建立資料庫,建立表,插入資料。
一、集合運算
1.集合運算
(1)對輸入的兩個集合或多集進行的運算。
(2)多集:由兩個輸入的查詢生成的可能包含重複記錄的中間結果集。
(3)T-SQL支援三種集合運算:並集(UNION)、交集(INTERSECT)、差集(EXCEPT)
2.語法
集合運算的基本格式:
輸入的查詢1
集合運算子>
輸入的查詢2
[ORDER BY]
3.要求
(1)輸入的查詢不能包含ORDER BY字句;
(2)可以為整個集合運算結果選擇性地增加一個ORDER BY字句;
(3)每個單獨的查詢可以包含所有邏輯查詢處理階段(處理控制排列順序的ORDER BY字句);
(4)兩個查詢 必須包含相同的列數;
(5)相應列必須具有相容的資料型別。相容個的資料型別:優先順序較低的資料型別必須能隱式地轉換為較高階的資料型別。比如輸入的查詢1的第一列為int型別,輸入的查詢2的第一列為float型別,則較低的資料型別int型別可以隱式地轉換為較高階float型別。如果輸入的查詢1的第一列為char型別,輸入的查詢2的第一列為datetime型別,則會提示轉換失敗:從字串轉換日期和/或時間時,轉換失敗;
(6)集合運算結果中列名由輸入的查詢1決定,如果要為結果分配結果列,應該在輸入的查詢1中分配相應的別名;
(7)集合運算時,對行進行進行比較時,集合運算認為兩個NULL相等;
(8)UNION支援DISTINCT和ALL。不能顯示指定DISTINCT字句,如果不指定ALL,則預設使用DISTINCT;
(9)INTERSET和EXCEPT預設使用DISTINCT,不支援ALL。
二、UNION(並集)集合運算
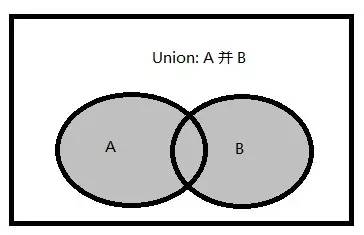
1.並集的文氏圖
並集:兩個集合的並集是一個包含集合A和B中所有元素的集合。
圖中陰影區域代表集合A與集合B的並集
2.UNION ALL集合運算
(1)假設Query1返回m行,Query2返回n行,則Query1 UNION ALL Query2返回(m+n)行;
(2)UNION ALL 不會刪除重複行,所以它的結果就是多集,而不是真正的集合;
(3)相同的行在結果中可能出現多次。
3.UNION DISTINCT集合運算
(1)假設Query1返回m行,Query2返回n行,Query1和Query2有相同的h行,則Query1 UNION Query2返回(m+n-h)行;
(2)UNION 會刪除重複行,所以它的結果就是集合;
(3)相同的行在結果中只出現一次。
(4)不能顯示指定DISTINCT字句,如果不指定ALL,則預設使用DISTINCT。
(5)當Query1與Query2比較某行記錄是否相等時,會認為取值為NULL的列是相等的列。
三、INTERSECT(交集)集合運算
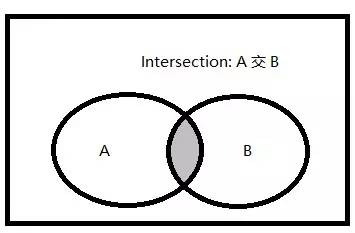
1.交集的文氏圖
交集:兩個集合(記為集合A和集合B)的交集是由既屬於A,也屬於B的所有元素組成的集合。
圖中陰影區域代表集合A與集合B的交集
2.INTERSECT DISTINCT集合運算
(1)假設Query1返回 m 行,Query2返回 n 行,Query1和Query2有相同的 h 行,則Query1 INTERSECT Query2返回 h 行;
(2)INTERSECT集合運算在邏輯上首先刪除兩個輸入多集中的重複行(把多集變為集合),然後返回只在兩個集合中都出現的行;
(3)INTERSECT 會刪除重複行,所以它的結果就是集合;
(4)相同的行在結果中只出現一次。
(5)不能顯示指定DISTINCT字句,如果不指定ALL,則預設使用DISTINCT。
(6)當Query1與Query2比較某行記錄是否相等時,會認為取值為NULL的列是相等的列。
(7)用內聯接或EXISTS謂詞可以代替INTERSECT集合運算,但是必須對NULL進行處理,否則這兩種方法對NULL值進行比較時,比較結果都是UNKNOWN,這樣的行會被過濾掉。
3.INTERSECT ALL集合運算
(1)ANSI SQL支援帶有ALL選項的INTERSECT集合運算,但SQL Server2008現在還沒有實現這種運算。後面會提供一種用於T-SQL實現的替代方案;
(2)假設Query1返回 m 行,Query2返回 n 行,如果行R在Query1中出現了x次,在Query2中出現了y次,則行R應該在INTERSECT ALL運算之後出現minimum(x,y)次。
下面提供用於T-SQL實現的INTERSECT ALL集合運算:公用表表達式 + 排名函式

結果如下:
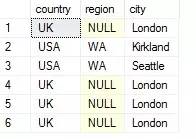
其中UK NULL London有四個重複行,
在排序函式的OVER字句中使用 ORDER BY ( SELECT 常量> )可以告訴SQL Server不必在意行的順序。
四、EXCEPT(差集)集合運算
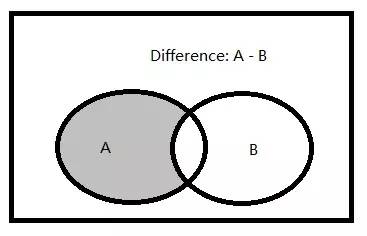
1.差集的文氏圖
差集:兩個集合(記為集合A和集合B)的由屬於集合A,但不屬於集合B的所有元素組成的集合。
圖中陰影區域代表集合A與集合B的差集
2.EXCEPT DISTINCT集合運算
(1)假設Query1返回 m 行,Query2返回 n 行,Query1和Query2有相同的 h 行,則Query1 INTERSECT Query2返回 m – h 行,而Query2 INTERSECT Query1 返回 n – h 行
(2)EXCEPT集合運算在邏輯上先刪除兩個輸入多集中的重複行(把多集轉變成集合),然後返回只在第一個集合中出現,在第二個集合眾不出現所有行。
(3)EXCEPT 會刪除重複行,所以它的結果就是集合;
(4)EXCEPT是不對稱的,差集的結果取決於兩個查詢的前後關係。
(5)相同的行在結果中只出現一次。
(6)不能顯示指定DISTINCT字句,如果不指定ALL,則預設使用DISTINCT。
(7)當Query1與Query2比較某行記錄是否相等時,會認為取值為NULL的列是相等的列。
(8)用左外聯接或NOT EXISTS謂詞可以代替INTERSECT集合運算,但是必須對NULL進行處理,否則這兩種方法對NULL值進行比較時,比較結果都是UNKNOWN,這樣的行會被過濾掉。
3.EXCEPT ALL集合運算
(1)ANSI SQL支援帶有ALL選項的EXCEPT集合運算,但SQL Server2008現在還沒有實現這種運算。後面會提供一種用於T-SQL實現的替代方案;
(2)假設Query1返回 m 行,Query2返回 n 行,如果行R在Query1中出現了x次,在Query2中出現了y次,且x>y,則行R應該在EXCEPT ALL運算之後出現 x – y 次。
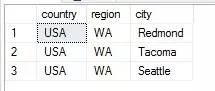
下面提供用於T-SQL實現的EXCEPT ALL集合運算:公用表表達式 + 排名函式
- WITH INTERSECT_ALL
- AS (
- SELECT ROW_NUMBER() OVER ( PARTITION BY country, region, city ORDER BY ( SELECT
- 0
- ) ) AS rownum ,
- country ,
- region ,
- city
- FROM HR.Employees
- EXCEPT
- SELECT ROW_NUMBER() OVER ( PARTITION BY country, region, city ORDER BY ( SELECT
- 0
- ) ) AS rownum ,
- country ,
- region ,
- city
- FROM Sales.Customers
- )
- SELECT country ,
- region ,
- city
- FROM INTERSECT_ALL
結果如下:
五、集合運算的優先順序
1.INTERSECT>UNION=EXCEPT
2.首先計算INTERSECT,然後從左到右的出現順序依次處理優先順序的相同的運算。
3.可以使用圓括號控制集合運算的優先順序,它具有最高的優先順序。
六、特殊處理
1.只有ORDER BY能夠直接應用於集合運算的結果;
2.其他階段如表運算子、WHERE、GROUP BY、HAVING等,不支援直接應用於集合運算的結果,這個時候可以使用表表達式來避開這一限制。如根據包含集合運算的查詢定義個表表達式,然後在外部查詢中對錶表示式應用任何需要的邏輯查詢處理;
3.ORDER BY字句不能直接應用於集合運算中的單個查詢,這個時候可以TOP+ORDER BY字句+表表達式來避開這一限制。如定義一個基於該TOP查詢的表表達式,然後通過一個使用這個表表達式的外部查詢參與集合運算。
七、練習題
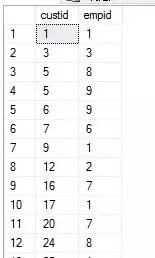
1.寫一個查詢,返回在2008年1月有訂單活動,而在2008年2月沒有訂單活動的客戶和僱員。
期望結果:
方案一:EXCEPT
(1)先用查詢1查詢出2008年1月份有訂單活動的客戶和僱員
(2)用查詢2查詢2008年2月份客戶的訂單活動的客戶和僱員
(3)用差集運算子查詢2008年1月有訂單活動而2008年2月沒有訂單活動的客戶和僱員
- SELECT custid ,
- empid
- FROM Sales.Orders
- WHERE orderdate >= '20080101'
- AND orderdate = '20080201'
- AND orderdate
方案二:NOT EXISTS
必須保證custid,empid不能為null,才能用NOT EXISTS進行查詢,如果custid或empid其中有null值存在,則不能用NOT EXISTS進行查詢,因為比較NULL值的結果是UNKNOWN,這樣的行用NOT EXISTS查詢返回的子查詢的行會被過濾掉,所以最後的外查詢會多出NULL值的行,最後查詢結果中會多出NULL值的行。
- SELECT custid ,
- empid
- FROM Sales.Orders AS O1
- WHERE orderdate >= '20080101'
- AND orderdate = '20080201'
- AND orderdate
如果我往Sales.Orders表中插入兩行資料:
插入cutid=NULL,empid=1,orderdate=‘20080101’
- INSERT INTO [TSQLFundamentals2008].[Sales].[Orders]
- ( [custid] ,
- [empid] ,
- [orderdate] ,
- [requireddate] ,
- [shippeddate] ,
- [shipperid] ,
- [freight] ,
- [shipname] ,
- [shipaddress] ,
- [shipcity] ,
- [shipregion] ,
- [shippostalcode] ,
- [shipcountry]
- )
- VALUES ( NULL ,
- 1 ,
- '20080101' ,
- '20080101' ,
- '20080101' ,
- 1 ,
- 1 ,
- 'A' ,
- '20080101' ,
- 'A' ,
- 'A' ,
- 'A' ,
- 'A'
- )
- GO
插入cutid=NULL,empid=1,orderdate=‘20080201’
- INSERT INTO [TSQLFundamentals2008].[Sales].[Orders]
- ( [custid] ,
- [empid] ,
- [orderdate] ,
- [requireddate] ,
- [shippeddate] ,
- [shipperid] ,
- [freight] ,
- [shipname] ,
- [shipaddress] ,
- [shipcity] ,
- [shipregion] ,
- [shippostalcode] ,
- [shipcountry]
- )
- VALUES ( NULL ,
- 1 ,
- '20080201' ,
- '20080101' ,
- '20080101' ,
- 1 ,
- 1 ,
- 'A' ,
- '20080101' ,
- 'A' ,
- 'A' ,
- 'A' ,
- 'A'
- )
- GO
用方案一查詢出來結果為50行,會把cutid=NULL,empid=1的行過濾掉
用方案二查詢出來結果為51行,不會把cutid=NULL,empid=1的行過濾掉
用下面的方案可以解決上面的問題,需要處理cutid=NULL,或者empid=null的情況。返回50行
- SELECT custid ,
- empid
- FROM Sales.Orders AS O1
- WHERE orderdate >= '20080101'
- AND orderdate = '20080201'
- AND orderdate
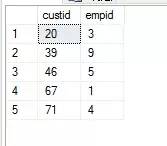
2.寫一個查詢,返回在2008年1月和在2008年2月都有訂單活動的客戶和僱員。
期望結果:
方案一:INTERSECT
(1)先用查詢1查詢出2008年1月份有訂單活動的客戶和僱員
(2)用查詢2查詢2008年2月份客戶的訂單活動的客戶和僱員
(3)用交集運算子查詢2008年1月和2008年2月都有訂單活動的客戶和僱員
- SELECT custid ,
- empid
- FROM Sales.Orders
- WHERE orderdate >= '20080101'
- AND orderdate = '20080201'
- AND orderdate
方案二:EXISTS
必須保證custid,empid不能為null,才能用EXISTS進行查詢,如果custid或empid其中有null值存在,則不能用EXISTS進行查詢,因為比較NULL值的結果是UNKNOWN,這樣的行用EXISTS查詢返回的子查詢的行會被過濾掉,所以最後的外查詢會少NULL值的行,最後查詢結果中會少NULL值的行。
- SELECT custid ,
- empid
- FROM Sales.Orders AS O1
- WHERE orderdate >= '20080101'
- AND orderdate = '20080201'
- AND orderdate
如果我往Sales.Orders表中插入兩行資料:
插入cutid=NULL,empid=1,orderdate=’20080101′
插入cutid=NULL,empid=1,orderdate=’20080201′
用方案一查詢出來結果為6行,不會把cutid=NULL,empid=1的行過濾掉
用方案二查詢出來結果為5行,會把cutid=NULL,empid=1的行過濾掉
用下面的方案可以解決上面的問題,需要處理cutid=NULL,或者empid=null的情況。返回6行。
- SELECT custid ,
- empid
- FROM Sales.Orders AS O1
- WHERE orderdate >= '20080101'
- AND orderdate = '20080201'
- AND orderdate
3.寫一個查詢,返回在2008年1月和在2008年2月都有訂單活動,而在2007年沒有訂單活動的客戶和僱員
期望結果:
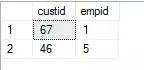
方案一:INTERSECT + EXCEPT
- SELECT custid ,
- empid
- FROM Sales.Orders
- WHERE orderdate >= '20080101'
- AND orderdate = '20080201'
- AND orderdate = '20070101'
- AND orderdate
方案二:EXISTS + NOT EXISTS
- SELECT custid ,
- empid
- FROM Sales.Orders AS O1
- WHERE orderdate >= '20080101'
- AND orderdate = '20080201'
- AND orderdate = '20070101'
- AND orderdate