
【推薦】分析Zookeeper的一致性原理
zookeeper(簡稱zk),顧名思義,為動物園管理員的意思,動物對應服務節點,zk是這些節點的管理者。在分散式場景中,zk的應用非常廣泛,如:資料釋出/訂閱、命名服務、配置中心、分散式鎖、叢集管理、選主與服務發現等等。這不僅得益於zk類檔案系統的資料模型和基於Watcher機制的分散式事件通知,也得益於zk特殊的高容錯資料一致性協議。
這裡的一致性,是指資料在多個副本之間保持一致的特性。分散式環境裡,多個副本處於不同的節點上,如果對副本A的更新操作,未同步到副本B上,外界獲取資料時,A與B的返回結果會不一樣,這是典型的分散式資料不一致情況。而強一致性,是指分散式系統中,如果某個資料更新成功,則所有使用者都能讀取到最新的值。CAP定理告訴我們,在分散式系統設計中,P(分割槽容錯性)是不可缺少的,因此只能在A(可用性)與C(一致性)間做取捨。本文主要探究zk在資料一致性方面的處理邏輯。
一、基本概念:
-
資料節點(dataNode):zk資料模型中的最小資料單元,資料模型是一棵樹,由斜槓(/)分割的路徑名唯一標識,資料節點可以儲存資料內容及一系列屬性資訊,同時還可以掛載子節點,構成一個層次化的名稱空間。
-
會話(Session):指zk客戶端與zk伺服器之間的會話,在zk中,會話是通過客戶端和伺服器之間的一個TCP長連線來實現的。通過這個長連線,客戶端能夠使用心跳檢測與伺服器保持有效的會話,也能向伺服器傳送請求並接收響應,還可接收伺服器的Watcher事件通知。Session的sessionTimeout,是會話超時時間,如果這段時間內,客戶端未與伺服器發生任何溝通(心跳或請求),伺服器端會清除該session資料,客戶端的TCP長連線將不可用,這種情況下,客戶端需要重新例項化一個Zookeeper物件。
-
事務及ZXID:事務是指能夠改變Zookeeper伺服器狀態的操作,一般包括資料節點的建立與刪除、資料節點內容更新和客戶端會話建立與失效等操作。對於每個事務請求,zk都會為其分配一個全域性唯一的事務ID,即ZXID,是一個64位的數字,高32位表示該事務發生的叢集選舉週期(叢集每發生一次leader選舉,值加1),低32位表示該事務在當前選擇週期內的遞增次序(leader每處理一個事務請求,值加1,發生一次leader選擇,低32位要清0)。
-
事務日誌:所有事務操作都是需要記錄到日誌檔案中的,可通過 dataLogDir配置檔案目錄,檔案是以寫入的第一條事務zxid為字尾,方便後續的定位查詢。zk會採取“磁碟空間預分配”的策略,來避免磁碟Seek頻率,提升zk伺服器對事務請求的影響能力。預設設定下,每次事務日誌寫入操作都會實時刷入磁碟,也可以設定成非實時(寫到記憶體檔案流,定時批量寫入磁碟),但那樣斷電時會帶來丟失資料的風險。
-
資料快照:資料快照是zk資料儲存中另一個非常核心的執行機制。資料快照用來記錄zk伺服器上某一時刻的全量記憶體資料內容,並將其寫入到指定的磁碟檔案中,可通過dataDir配置檔案目錄。可配置引數snapCount,設定兩次快照之間的事務操作個數,zk節點記錄完事務日誌時,會統計判斷是否需要做資料快照(距離上次快照,事務操作次數等於snapCount/2~snapCount 中的某個值時,會觸發快照生成操作,隨機值是為了避免所有節點同時生成快照,導致叢集影響緩慢)。
-
過半:所謂“過半”是指大於叢集機器數量的一半,即大於或等於(n/2+1),此處的“叢集機器數量”不包括observer角色節點。leader廣播一個事務訊息後,當收到半數以上的ack資訊時,就認為叢集中所有節點都收到了訊息,然後leader就不需要再等待剩餘節點的ack,直接廣播commit訊息,提交事務。選舉中的投票提議及資料同步時,也是如此,leader不需要等到所有learner節點的反饋,只要收到過半的反饋就可進行下一步操作。
二、資料模型
zk維護的資料主要有:客戶端的會話(session)狀態及資料節點(dataNode)資訊。zk在記憶體中構造了個DataTree的資料結構,維護著path到dataNode的對映以及dataNode間的樹狀層級關係。為了提高讀取效能,叢集中每個服務節點都是將資料全量儲存在記憶體中。可見,zk最適於讀多寫少且輕量級資料(預設設定下單個dataNode限制為1MB大小)的應用場景。資料僅儲存在記憶體是很不安全的,zk採用事務日誌檔案及快照檔案的方案來落盤資料,保障資料在不丟失的情況下能快速恢復。
三、叢集架構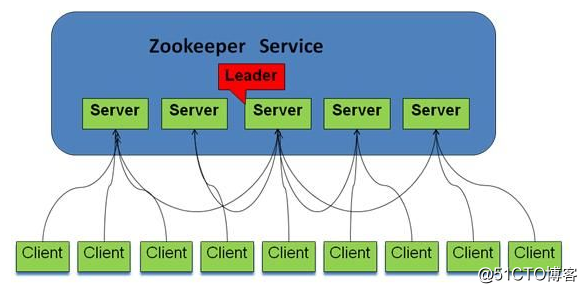
zk叢集由多個節點組成,其中有且僅有一個leader,處理所有事務請求;follower及observer統稱learner。learner需要同步leader的資料。follower還參與選舉及事務決策過程。
zk客戶端會打散配置檔案中的serverAddress 順序並隨機組成新的list,然後迴圈按序取一個伺服器地址進行連線,直到成功。follower及observer會將事務請求轉交給leader處理。 
要搭建一個高可用的zk叢集,我們首先需要確定好叢集規模。一般我們將節點(指leader及follower節點,不包括observer節點)個數設定為 2*n+1 ,n為可容忍宕機的個數。 zk使用“過半”設計原則,很好地解決了單點問題,提升了叢集容災能力。但是zk的叢集伸縮不是很靈活,叢集中所有機器ip及port都是事先配置在每個服務的zoo.cfg 檔案裡的。如果要往叢集增加一個follower節點,首先需要更改所有機器的zoo.cfg,然後逐個重啟。
叢集模式下,單個zk服務節點啟動時的工作流程大體如下:
-
統一由QuorumPeerMain作為啟動類,載入解析zoo.cfg配置檔案;
-
初始化核心類:ServerCnxnFactory(IO操作)、FileTxnSnapLog(事務日誌及快照檔案操作)、QuorumPeer例項(代表zk叢集中的一臺機器)、ZKDatabase(記憶體資料庫)等;
-
載入本地快照檔案及事務日誌,恢復記憶體資料;
-
完成leader選舉,節點間通過一系列投票,選舉產生最合適的機器成為leader,同時其餘機器成為follower或是observer。關於選舉演算法,就是叢集中哪個機器處理的資料越新(通過ZXID來比較,ZXID越大,資料越新),其越有可能被選中;
-
完成leader與learner間的資料同步:叢集中節點角色確定後,leader會重新載入本地快照及日誌檔案,以此作為基準資料,再結合各個learner的本地提交資料,leader再確定需要給具體learner回滾哪些資料及同步哪些資料;
-
當leader收到過半的learner完成資料同步的ACK,叢集開始正常工作,可以接收並處理客戶端請求,在此之前叢集不可用。
四、zookeeper一致性協議
zookeeper實現資料一致性的核心是ZAB協議(Zookeeper原子訊息廣播協議)。該協議需要做到以下幾點:
(1)叢集在半數以下節點宕機的情況下,能正常對外提供服務;
(2)客戶端的寫請求全部轉交給leader來處理,leader需確保寫變更能實時同步給所有follower及observer;
(3)leader宕機或整個叢集重啟時,需要確保那些已經在leader伺服器上提交的事務最終被所有伺服器都提交,確保丟棄那些只在leader伺服器上被提出的事務,並保證叢集能快速恢復到故障前的狀態。
Zab協議有兩種模式, 崩潰恢復(選主+資料同步)和訊息廣播(事務操作)。任何時候都需要保證只有一個主程序負責進行事務操作,而如果主程序崩潰了,就需要迅速選舉出一個新的主程序。主程序的選舉機制與事務操作機制是緊密相關的。下面詳細講解這三個場景的協議規則,從細節去探索ZAB協議的資料一致性原理。
1、選主:leader選舉是zk中最重要的技術之一,也是保證分散式資料一致性的關鍵所在。當叢集中的一臺伺服器處於如下兩種情況之一時,就會進入leader選舉階段——伺服器初始化啟動、伺服器執行期間無法與leader保持連線。
選舉階段,叢集間互傳的訊息稱為投票,投票Vote主要包括二個維度的資訊:ID、ZXID
-
ID 被推舉的leader的伺服器ID,叢集中的每個zk節點啟動前就要配置好這個全域性唯一的ID。
-
ZXID 被推舉的leader的事務ID ,該值是從機器DataTree記憶體中取的,即事務已經在機器上被commit過了。
節點進入選舉階段後的大體執行邏輯如下:
(1)設定狀態為LOOKING,初始化內部投票Vote (id,zxid) 資料至記憶體,並將其廣播到叢集其它節點。節點首次投票都是選舉自己作為leader,將自身的服務ID、處理的最近一個事務請求的ZXID(ZXID是從記憶體資料庫裡取的,即該節點最近一個完成commit的事務id)及當前狀態廣播出去。然後進入迴圈等待及處理其它節點的投票資訊的流程中。
(2)迴圈等待流程中,節點每收到一個外部的Vote資訊,都需要將其與自己記憶體Vote資料進行PK,規則為取ZXID大的,若ZXID相等,則取ID大的那個投票。若外部投票勝選,節點需要將該選票覆蓋之前的記憶體Vote資料,並再次廣播出去;同時還要統計是否有過半的贊同者與新的記憶體投票資料一致,無則繼續迴圈等待新的投票,有則需要判斷leader是否在贊同者之中,在則退出迴圈,選舉結束,根據選舉結果及各自角色切換狀態,leader切換成LEADING、follower切換到FOLLOWING、observer切換到OBSERVING狀態。
演算法細節可參照FastLeaderElection.lookForLeader(),主要有三個執行緒在工作:選舉執行緒(主動呼叫lookForLeader方法的執行緒,通過阻塞佇列sendqueue及recvqueue與其它兩個執行緒協作)、WorkerReceiver執行緒(選票接收器,不斷獲取其它伺服器發來的選舉訊息,篩選後會儲存到recvqueue佇列中。zk伺服器啟動時,開始正常工作,不停止)以及WorkerSender執行緒(選票傳送器,會不斷地從sendqueue佇列中獲取待發送的選票,並廣播至叢集)。WorkerReceiver執行緒一直在工作,即使當前節點處於LEADING或者FOLLOWING狀態,它起到了一個過濾的作用,當前節點為LOOKING時,才會將外部投票資訊轉交給選舉執行緒處理;如果當前節點處於非LOOKING狀態,收到了處於LOOKING狀態的節點投票資料(外部節點重啟或網路抖動情況下),說明發起投票的節點資料跟叢集不一致,這時,當前節點需要向叢集廣播出最新的記憶體Vote(id,zxid),落後節點收到該Vote後,會及時註冊到leader上,並完成資料同步,跟上叢集節奏,提供正常服務。
2、選主後的資料同步:選主演算法中的zxid是從記憶體資料庫中取的最新事務id,事務操作是分兩階段的(提出階段和提交階段),leader生成提議並廣播給followers,收到半數以上的ACK後,再廣播commit訊息,同時將事務操作應用到記憶體中。follower收到提議後先將事務寫到本地事務日誌,然後反饋ACK,等接到leader的commit訊息時,才會將事務操作應用到記憶體中。可見,選主只是選出了記憶體資料是最新的節點,僅僅靠這個是無法保證已經在leader伺服器上提交的事務最終被所有伺服器都提交。比如leader發起提議P1,並收到半數以上follower關於P1的ACK後,在廣播commit訊息之前宕機了,選舉產生的新leader之前是follower,未收到關於P1的commit訊息,記憶體中是沒有P1的資料。而ZAB協議的設計是需要保證選主後,P1是需要應用到叢集中的。這塊的邏輯是通過選主後的資料同步來彌補。
選主後,節點需要切換狀態,leader切換成LEADING狀態後的流程如下:
(1)重新載入本地磁碟上的資料快照至記憶體,並從日誌檔案中取出快照之後的所有事務操作,逐條應用至記憶體,並新增到已提交事務快取commitedProposals。這樣能保證日誌檔案中的事務操作,必定會應用到leader的記憶體資料庫中。
(2)獲取learner傳送的FOLLOWERINFO/OBSERVERINFO資訊,並與自身commitedProposals比對,確定採用哪種同步方式,不同的learner可能採用不同同步方式(DIFF同步、TRUNC+DIFF同步、SNAP同步)。這裡是拿learner記憶體中的zxid與leader記憶體中的commitedProposals(min、max)比對,如果zxid介於min與max之間,但又不存在於commitedProposals中時,說明該zxid對應的事務需要TRUNC回滾;如果 zxid 介於min與max之間且存在於commitedProposals中,則leader需要將zxid+1~max 間所有事務同步給learner,這些記憶體缺失資料,很可能是因為leader切換過程中造成commit訊息丟失,learner只完成了事務日誌寫入,未完成提交事務,未應用到記憶體。
(3)leader主動向所有learner傳送同步資料訊息,每個learner有自己的傳送佇列,互不干擾。同步結束時,leader會向learner傳送NEWLEADER指令,同時learner會反饋一個ACK。當leader接收到來自learner的ACK訊息後,就認為當前learner已經完成了資料同步,同時進入“過半策略”等待階段。當leader統計到收到了一半已上的ACK時,會向所有已經完成資料同步的learner傳送一個UPTODATE指令,用來通知learner叢集已經完成了資料同步,可以對外服務了。
細節可參照Leader.lead() 、Follower.followLeader()及LearnerHandler類。
3、事務操作:ZAB協議對於事務操作的處理是一個類似於二階段提交過程。針對客戶端的事務請求,leader伺服器會為其生成對應的事務proposal,並將其傳送給叢集中所有follower機器,然後收集各自的選票,最後進行事務提交。流程如下圖。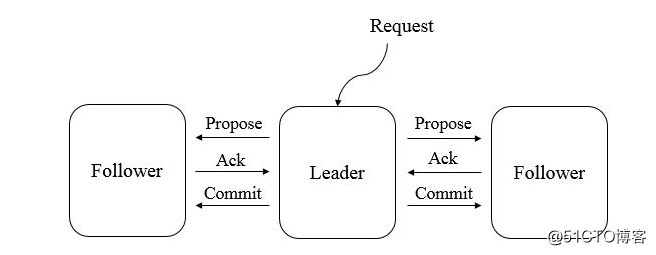
ZAB協議的二階段提交過程中,移除了中斷邏輯(事務回滾),所有follower伺服器要麼正常反饋leader提出的事務proposal,要麼就拋棄leader伺服器。follower收到proposal後的處理很簡單,將該proposal寫入到事務日誌,然後立馬反饋ACK給leader,也就是說如果不是網路、記憶體或磁碟等問題,follower肯定會寫入成功,並正常反饋ACK。leader收到過半follower的ACK後,會廣播commit訊息給所有learner,並將事務應用到記憶體;learner收到commit訊息後會將事務應用到記憶體。
ZAB協議中多次用到“過半”設計策略 ,該策略是zk在A(可用性)與C(一致性)間做的取捨,也是zk具有高容錯特性的本質。相較分散式事務中的2PC(二階段提交協議)的“全量通過”,ZAB協議可用性更高(犧牲了部分一致性),能在叢集半數以下服務宕機時正常對外提供服務。
如何檢視一個zk節點是leader或者是follower?
$ cd ${zookeeper install home}/bin
$ ./zkServer.sh status
如何開發java zookeeper 應用程式?見
1. http://www.cnblogs.com/IcanFixIt/p/7882107.html
2.【Zookeeper --- Java API簡單例項】https://blog.csdn.net/Ka_Ka314/article/details/82978159
3.【同步和非同步方式呼叫 zookeeper API】http://www.cnblogs.com/leesf456/p/6028416.html
對watcher的理解:
【Apache ZooKeeper】理解ZooKeeper中的Watches https://blog.csdn.net/z69183787/article/details/54730322