
深入理解C語言記憶體管理
之前在學Java的時候對於Java虛擬機器中的記憶體分佈有一定的瞭解,但是最近在看一些C,發現居然自己對於C語言的記憶體分配了解的太少。
問題不能拖,我這就來學習一下吧,爭取一次搞定。 在任何程式設計環境及語言中,記憶體管理都十分重要。
記憶體管理的基本概念
分析C語言記憶體的分佈先從Linux下可執行的C程式入手。現在有一個簡單的C源程式hello.c
1 #include <stdio.h>
2 #include <stdlib.h>
3 int var1 = 1;
4
5 int main(void) {
6 int var2 = 2;
經過gcc hello.c進行編譯之後得到了名為a.out的可執行檔案
[[email protected] leet_code]$ ls -al a.out
-rwxrwxr-x. 1 tuhooo tuhooo 8592 Jul 22 20:40 a.out
ls命令是檢視檔案的元資料資訊
[[email protected] leet_code]$ file a.out
a.out: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=23c58f2cad39d8b15b91f0cc8129055833372afe, not stripped
file命令用來識別檔案型別,也可用來辨別一些檔案的編碼格式。
它是通過檢視檔案的頭部資訊來獲取檔案型別,而不是像Windows通過副檔名來確定檔案型別的。
[[email protected] leet_code]$ size a.out
| text | data | bss | dec | hex | filename |
| (程式碼區靜態資料) | (全域性初始化靜態資料) | (未初始化資料區) | (十進位制總和) | (十六制總和) | (檔名) |
| 1301 | 560 | 8 | 1869 | 74d | a.out |
顯示一個目標檔案或者連結庫檔案中的目標檔案的各個段的大小,當沒有輸入檔名時,預設為a.out。
size:支援的目標: elf32-i386 a.out-i386-linux efi-app-ia32 elf32-little elf32-big srec symbolsrec tekhex binary ihex trad-core。
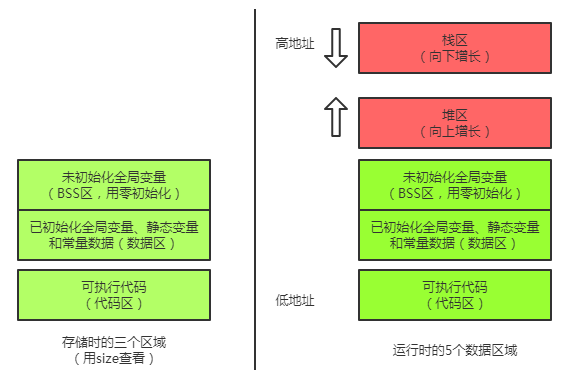
那啥,可執行檔案在儲存(也就是還沒有載入到記憶體中)的時候,分為:程式碼區、資料區和未初始化資料區3個部分。
進一步解讀
(1)程式碼區(text segment)。存放CPU執行的機器指令(machine instructions)。通常,程式碼區是可共享的(即另外的執行程式可以呼叫它),因為對於頻繁被執行的程式,只需要在記憶體中有一份程式碼即可。程式碼區通常是隻讀的,使其只讀的原因是防止程式意外地修改了它的指令。另外,程式碼區還規劃了局部變數的相關資訊。
(2)全域性初始化資料區/靜態資料區(initialized data segment/data segment)。該區包含了在程式中明確被初始化的全域性變數、靜態變數(包括全域性靜態變數和區域性靜態變數)和常量資料(如字串常量)。例如,一個不在任何函式內的宣告(全域性資料):
1 int maxcount = 99;
使得變數maxcount根據其初始值被儲存到初始化資料區中。
1 static mincount = 100;
這聲明瞭一個靜態資料,如果是在任何函式體外宣告,則表示其為一個全域性靜態變數,如果在函式體內(區域性),則表示其為一個區域性靜態變數。另外,如果在函式名前加上static,則表示此函式只能在當前檔案中被呼叫。
(3)未初始化資料區。亦稱BSS區(uninitialized data segment),存入的是全域性未初始化變數。BSS這個叫法是根據一個早期的彙編運算子而來,這個彙編運算子標誌著一個塊的開始。BSS區的資料在程式開始執行之前被核心初始化為0或者空指標(NULL)。例如一個不在任何函式內的宣告:
1 long sum[1000];
將變數sum儲存到未初始化資料區。
下圖所示為可執行程式碼儲存時結構和執行時結構的對照圖。一個正在執行著的C編譯程式佔用的記憶體分為程式碼區、初始化資料區、未初始化資料區、堆區和棧區5個部分。
再來看一張圖,多個一個命令列引數區:

(1)程式碼區(text segment)。程式碼區指令根據程式設計流程依次執行,對於順序指令,則只會執行一次(每個程序),如果反覆,則需要使用跳轉指令,如果進行遞迴,則需要藉助棧來實現。程式碼段: 程式碼段(code segment/text segment )通常是指用來存放程式執行程式碼的一塊記憶體區域。這部分割槽域的大小在程式執行前就已經確定,並且記憶體區域通常屬於只讀, 某些架構也允許程式碼段為可寫,即允許修改程式。在程式碼段中,也有可能包含一些只讀的常數變數,例如字串常量等。程式碼區的指令中包括操作碼和要操作的物件(或物件地址引用)。如果是立即數(即具體的數值,如5),將直接包含在程式碼中;如果是區域性資料,將在棧區分配空間,然後引用該資料地址;如果是BSS區和資料區,在程式碼中同樣將引用該資料地址。另外,程式碼段還規劃了局部資料所申請的記憶體空間資訊。
(2)全域性初始化資料區/靜態資料區(Data Segment)。只初始化一次。資料段: 資料段(data segment )通常是指用來存放程式中已初始化的全域性變數的一塊記憶體區域。資料段屬於靜態記憶體分配。data段中的靜態資料區存放的是程式中已初始化的全域性變數、靜態變數和常量。
(3)未初始化資料區(BSS)。在執行時改變其值。BSS 段: BSS 段(bss segment )通常是指用來存放程式中未初始化的全域性變數的一塊記憶體區域。BSS 是英文Block Started by Symbol 的簡稱。BSS 段屬於靜態記憶體分配,即程式一開始就將其清零了。一般在初始化時BSS段部分將會清零。
(4)棧區(stack)。由編譯器自動分配釋放,存放函式的引數值、區域性變數的值等。存放函式的引數值、區域性變數的值,以及在進行任務切換時存放當前任務的上下文內容。其操作方式類似於資料結構中的棧。每當一個函式被呼叫,該函式返回地址和一些關於呼叫的資訊,比如某些暫存器的內容,被儲存到棧區。然後這個被呼叫的函式再為它的自動變數和臨時變數在棧區上分配空間,這就是C實現函式遞迴呼叫的方法。每執行一次遞迴函式呼叫,一個新的棧框架就會被使用,這樣這個新例項棧裡的變數就不會和該函式的另一個例項棧裡面的變數混淆。棧(stack) :棧又稱堆疊, 是使用者存放程式臨時建立的區域性變數,也就是說我們函式括弧"{}"中定義的變數(但不包括static 宣告的變數,static 意味著在資料段中存放變數)。除此以外,在函式被呼叫時,其引數也會被壓入發起呼叫的程序棧中,並且待到呼叫結束後,函式的返回值也會被存放回棧中。由於棧的先進先出特點,所以棧特別方便用來儲存/ 恢復呼叫現場。從這個意義上講,我們可以把堆疊看成一個寄存、交換臨時資料的記憶體區。
(5)堆區(heap)。用於動態記憶體分配。堆在記憶體中位於bss區和棧區之間。一般由程式設計師分配和釋放,若程式設計師不釋放,程式結束時有可能由OS回收。堆(heap): 堆是用於存放程序執行中被動態分配的記憶體段,它的大小並不固定,可動態擴張或縮減。當程序呼叫malloc 等函式分配記憶體時,新分配的記憶體就被動態新增到堆上(堆被擴張);當利用free 等函式釋放記憶體時,被釋放的記憶體從堆中被剔除(堆被縮減)。在將應用程式載入到記憶體空間執行時,作業系統負責程式碼段、資料段和BSS段的載入,並將在記憶體中為這些段分配空間。棧段亦由作業系統分配和管理,而不需要程式設計師顯示地管理;堆段由程式設計師自己管理,即顯式地申請和釋放空間。
另外,可執行程式在執行時具有相應的程式屬性。在有作業系統支援時,這些屬性頁由作業系統管理和維護。
C語言程式編譯完成之後,已初始化的全域性變數儲存在DATA段中,未初始化的全域性變數儲存在BSS段中。TEXT和DATA段都在可執行檔案中,由系統從可執行檔案中載入;而BSS段不在可執行檔案中,由系統初始化。BSS段只儲存沒有值的變數,所以事實上它並不需要儲存這些變數的映像。執行時所需要的BSS段大小記錄在目標檔案中,但是BSS段並不佔據目標檔案的任何空間。


以上兩圖來自於《C語言專家程式設計》。
在作業系統中,一個程序就是處於執行期的程式(當然包括系統資源),實際上正在執行的程式程式碼的活標本。那麼程序的邏輯地址空間是如何劃分的呢?

左邊的是UNIX/LINUX系統的執行檔案,右邊是對應程序邏輯地址空間的劃分情況。
首先是堆疊區(stack),堆疊是由編譯器自動分配釋放,存放函式的引數值,區域性變數的值等。其操作方式類似於資料結構中的棧。棧的申請是由系統自動分配,如在函式內部申請一個區域性變數 int h,同時判別所申請空間是否小於棧的剩餘空間,如若小於的話,在堆疊中為其開闢空間,為程式提供記憶體,否則將報異常提示棧溢位。
其次是堆(heap),堆一般由程式設計師分配釋放, 若程式設計師不釋放,程式結束時可能由OS回收 。注意它與資料結構中的堆是兩回事,分配方式倒是類似於連結串列。堆的申請是由程式設計師自己來操作的,在C中使用malloc函式,而C++中使用new運算子,但是堆的申請過程比較複雜:當系統收到程式的申請時,會遍歷記錄空閒記憶體地址的連結串列,以求尋找第一個空間大於所申請空間的堆結點,然後將該結點從空閒 結點連結串列中刪除,並將該結點的空間分配給程式,此處應該注意的是有些情況下,新申請的記憶體塊的首地址記錄本次分配的記憶體塊大小,這樣在delete尤其是 delete[]時就能正確的釋放記憶體空間。
接著是全域性資料區(靜態區) (static),全域性變數和靜態變數的儲存是放在一塊的,初始化的全域性變數和靜態變數在一塊區域, 未初始化的全域性變數和未初始化的靜態變數在相鄰的另一塊區域。 另外文字常量區,常量字串就是放在這裡,程式結束後有系統釋放。
最後是程式程式碼區,放著函式體的二進位制程式碼。
為什麼要這麼分配記憶體?
(1)一個程序在執行過程中,程式碼是根據流程依次執行的,只需要訪問一次,當然跳轉和遞迴有可能使程式碼執行多次,而資料一般都需要訪問多次,因此單獨開闢空間以方便訪問和節約空間。
(2)臨時資料及需要再次使用的程式碼在執行時放入棧區中,生命週期短。
(3)全域性資料和靜態資料有可能在整個程式執行過程中都需要訪問,因此單獨儲存管理。
(4)堆區由使用者自由分配,以便管理。
舉例說明記憶體分佈情況
1 /* memory_allocate.c用於演示記憶體分佈情況 */ 2 3 int a = 0; /* a在全域性已初始化資料區 */ 4 char *p1; /* p1在BSS區(未初始化全域性變數) */ 5 6 int main(void) { 7 int b; /* b在棧區 */ 8 char s[] = "abc"; /* s為陣列變數, 儲存在棧區 */ 9 /* "abc"為字串常量, 儲存在已初始化資料區 */ 10 char *p1, p2; /* p1、p2在棧區 */ 11 char *p3 = "123456"; /* "123456\0"已初始化在資料區, p3在棧區 */ 12 static int c = 0; /* c為全域性(靜態)資料, 存在於已初始化資料區 */ 13 /* 另外, 靜態資料會自動初始化 */ 14 p1 = (char *)malloc(10); /* 分配的10個位元組的區域存在於堆區 */ 15 p2 = (char *)malloc(20); /* 分配得來的20個位元組的區域存在於堆區 */ 16 17 free(p1); 18 free(p2); 19 }
記憶體的分配方式
在C語言中,物件可以使用靜態或動態的方式分配記憶體空間。
靜態分配:編譯器在處理程式原始碼時分配。
動態分配:程式在執行時呼叫malloc庫函式申請分配。
靜態記憶體分配是在程式執行之前進行的因而效率比較高,而動態記憶體分配則可以靈活的處理未知數目的。
靜態與動態記憶體分配的主要區別如下:
靜態物件是有名字的變數,可以直接對其進行操作;動態物件是沒有名字的一段地址,需要通過指標間接地對它進行操作。
靜態物件的分配與釋放由編譯器自動處理;動態物件的分配與釋放必須由程式設計師顯式地管理,它通過malloc()和free兩個函式來完成。
以下是採用靜態分配方式的例子。
1 int a = 100;
此行程式碼指示編譯器分配足夠的儲存區以存放一個整型值,該儲存區與名字a相關聯,並用數值100初始化該儲存區。
以下是採用動態分配方式的例子:
1 p1 = (char *)malloc(10*sizeof(int));
此行程式碼分配了10個int型別的物件,然後返回物件在記憶體中的地址,接著這個地址被用來初始化指標物件p1,對於動態分配的記憶體唯一的訪問方式是通過指標間接地訪問,其釋放方法為:
1 free(p1);
棧和堆的區別
前面已經介紹過,棧是由編譯器在需要時分配的,不需要時自動清除的變數儲存區。裡面的變數通常是區域性變數、函式引數等。堆是由malloc()函式分配的記憶體塊,記憶體釋放由程式設計師手動控制,在C語言為free函式完成。棧和堆的主要區別有以下幾點:
(1)管理方式不同。
棧編譯器自動管理,無需程式設計師手工控制;而堆空間的申請釋放工作由程式設計師控制,容易產生記憶體洩漏。對於棧來講,是由編譯器自動管理,無需我們手工控制;對於堆來說,釋放工作由程式設計師控制,容易產生memory leak。空間大小:一般來講在32位系統下,堆記憶體可以達到4G的空間,從這個角度來看堆記憶體幾乎是沒有什麼限制的。但是對於棧來講,一般都是有一定的空間大小的,例如,在VC6下面,預設的棧空間大小是1M。當然,這個值可以修改。碎片問題:對於堆來講,頻繁的new/delete勢必會造成記憶體空間的不連續,從而造成大量的碎片,使程式效率降低。對於棧來講,則不會存在這個問 題,因為棧是先進後出的佇列,他們是如此的一一對應,以至於永遠都不可能有一個記憶體塊從棧中間彈出,在它彈出之前,在它上面的後進的棧內容已經被彈出,詳細的可以參考資料結構。生長方向:對於堆來講,生長方向是向上的,也就是向著記憶體地址增加的方向;對於棧來講,它的生長方向是向下的,是向著記憶體地址減小的方向增長。分配方式:堆都是動態分配的,沒有靜態分配的堆。棧有2種分配方式:靜態分配和動態分配。靜態分配是編譯器完成的, 比如區域性變數的分配。動態分配由malloca函式進行分配,但是棧的動態分配和堆是不同的,它的動態分配是由編譯器進行釋放,無需我們手工實現。分配效率:棧是機器系統提供的資料結構,計算機會在底層對棧提供支援:分配專門的暫存器存放棧的地址,壓棧出棧都有專門的指令執行,這就決定了棧的效率比較高。堆則是C/C++函式庫提供的,它的機制是很複雜的,例如為了分配一塊記憶體,庫函式會按照一定的演算法(具體的演算法可以參考資料結構/作業系統)在堆記憶體中搜索可用的足夠大小的空間,如果沒有足夠大小的空間(可能是由於記憶體碎片太多),就有可能呼叫系統功能去增加程式資料段的記憶體空間,這樣就有機會分到足夠大小的記憶體,然後進行返回。顯然,堆的效率比棧要低得多。從這裡我們可以看到,堆和棧相比,由於大量new/delete的使用,容易造成大量的記憶體碎片;由於沒有專門的系統支援,效率很低;由於可能引發使用者態和核心態的切換,記憶體的申請,代價變得更加昂貴。所以棧在程式中是應用最廣泛的,就算是函式的呼叫也利用棧去完成,函式呼叫過程中的引數,返回地址, EBP和區域性變數都採用棧的方式存放。所以,我們推薦大家儘量用棧,而不是用堆。雖然棧有如此眾多的好處,但是由於和堆相比不是那麼靈活,有時候分配大量的記憶體空間,還是用堆好一些。無論是堆還是棧,都要防止越界現象的發生(除非你是故意使其越界),因為越界的結果要麼是程式崩潰,要麼是摧毀程式的堆、棧結構,產生以想不到的結果。
(2)空間大小不同。
棧是向低地址擴充套件的資料結構,是一塊連續的記憶體區域。這句話的意思是棧頂的地址和棧的最大容量是系統預先規定好的,當申請的空間超過棧的剩餘空間時,將提示溢位。因此,使用者能從棧獲得的空間較小。
堆是向高地址擴充套件的資料結構,是不連續的記憶體區域。因為系統是用連結串列來儲存空閒記憶體地址的,且連結串列的遍歷方向是由低地址向高地址。由此可見,堆獲得的空間較靈活,也較大。棧中元素都是一一對應的,不會存在一個記憶體塊從棧中間彈出的情況。
在Windows下,棧是向低地址擴充套件的資料結構,是一塊連續的記憶體的區域。這句話的意思是棧頂的地址和棧的最大容量是系統預先規定好的,在 WINDOWS下,棧的大小是2M(也有的說是1M,總之是一個編譯時就確定的常數),如果申請的空間超過棧的剩餘空間時,將提示overflow。因此,能從棧獲得的空間較小。堆:堆是向高地址擴充套件的資料結構,是不連續的記憶體區域。這是由於系統是用連結串列來儲存的空閒記憶體地址的,自然是不連續的,而連結串列的遍歷方向是由低地址向高地址。堆的大小受限於計算機系統中有效的虛擬記憶體。由此可見,堆獲得的空間比較靈活,也比較大。
(3)是否產生碎片。
對於堆來講,頻繁的malloc/free(new/delete)勢必會造成記憶體空間的不連續,從而造成大量的碎片,使程式效率降低(雖然程式在退出後作業系統會對記憶體進行回收管理)。對於棧來講,則不會存在這個問題。
(4)增長方向不同。
堆的增長方向是向上的,即向著記憶體地址增加的方向;棧的增長方向是向下的,即向著記憶體地址減小的方向。
(5)分配方式不同。
堆都是程式中由malloc()函式動態申請分配並由free()函式釋放的;棧的分配和釋放是由編譯器完成的,棧的動態分配由alloca()函式完成,但是棧的動態分配和堆是不同的,他的動態分配是由編譯器進行申請和釋放的,無需手工實現。
STACK: 由系統自動分配。例如,宣告在函式中一個區域性變數 int b;系統自動在棧中為b開闢空間。HEAP:需要程式設計師自己申請,並指明大小,在C中malloc函式。指向堆中分配記憶體的指標則可能是存放在棧中的。
(6)分配效率不同。
棧是機器系統提供的資料結構,計算機會在底層對棧提供支援:分配專門的暫存器存放棧的地址,壓棧出棧都有專門的指令執行。堆則是C函式庫提供的,它的機制很複雜,例如為了分配一塊記憶體,庫函式會按照一定的演算法(具體的演算法可以參考資料結構/作業系統)在堆記憶體中搜索可用的足夠大的空間,如果沒有足夠大的空間(可能是由於記憶體碎片太多),就有需要作業系統來重新整理記憶體空間,這樣就有機會分到足夠大小的記憶體,然後返回。顯然,堆的效率比棧要低得多。
棧由系統自動分配,速度較快。但程式設計師是無法控制的。
堆是由new分配的記憶體,一般速度比較慢,而且容易產生記憶體碎片,不過用起來最方便。
(7)申請後系統的響應
棧:只要棧的剩餘空間大於所申請空間,系統將為程式提供記憶體,否則將報異常提示棧溢位。
堆:首先應該知道作業系統有一個記錄空閒記憶體地址的連結串列,當系統收到程式的申請時,會遍歷該連結串列,尋找第一個空間大於所申請空間的堆結點,然後將該結點從空閒結點連結串列中刪除,並將該結點的空間分配給程式。對於大多數系統,會在這塊記憶體空間中的首地址處記錄本次分配的大小,這樣,程式碼中的delete語句才能正確的釋放本記憶體空間。由於找到的堆結點的大小不一定正好等於申請的大小,系統會自動的將多餘的那部分重新放入空閒連結串列中。
(8)堆和棧中的儲存內容
棧:在函式呼叫時,第一個進棧的是主函式中後的下一條指令(函式呼叫語句的下一條可執行語句)的地址,然後是函式的各個引數,在大多數的C編譯器中,引數是由右往左入棧的,然後是函式中的區域性變數。注意靜態變數是不入棧的。當本次函式呼叫結束後,區域性變數先出棧,然後是引數,最後棧頂指標指向最開始存的地址,也就是主函式中的下一條指令,程式由該點繼續執行。棧中的記憶體是在程式編譯完成以後就可以確定的,不論佔用空間大小,還是每個變數的型別。
堆:一般是在堆的頭部用一個位元組存放堆的大小。堆中的具體內容由程式設計師安排。
(9)存取效率的比較
1 char s1[] = "a"; 2 char *s2 = "b";
a是在執行時刻賦值的;而b是在編譯時就確定的但是,在以後的存取中,在棧上的陣列比指標所指向的字串(例如堆)快。
(10)防止越界發生
無論是堆還是棧,都要防止越界現象的發生(除非你是故意使其越界),因為越界的結果要麼是程式崩潰,要麼是摧毀程式的堆、棧結構,產生以想不到的結果,就算是在你的程式執行過程中,沒有發生上面的問題,你還是要小心,說不定什麼時候就崩掉,那時候debug可是相當困難的
資料儲存區域例項
此程式顯示了資料儲存區域例項,在此程式中,使用了etext、edata和end3個外部全域性變數,這是與使用者程序相關的虛擬地址。在程式原始碼中列出了各資料的儲存位置,同時在程式執行時顯示了各資料的執行位置,下圖所示為程式執行過程中各變數的儲存位置。
mem_add.c
1 /* mem_add.c演示了C語言中地址的分佈情況 */ 2 3 #include <stdio.h> 4 #include <stdlib.h> 5 6 extern void afunc(void); 7 extern etext, edata, end; 8 9 int bss_var; /* 未初始化全域性資料儲存在BSS區 */ 10 int data_var = 42; /* 初始化全域性資料區域儲存在資料區 */ 11 #define SHW_ADDR(ID, I) printf("the %8s\t is at addr:%8x\n", ID, &I); /* 列印地址 */ 12 13 int main(int argc, char *argv[]) { 14 15 char *p, *b, *nb; 16 printf("Addr etext: %8x\t Addr edata %8x\t Addr end %8x\t\n", &etext, &edata, &end); 17 18 printf("\ntext Location:\n"); 19 SHW_ADDR("main", main); /* 檢視程式碼段main函式位置 */ 20 SHW_ADDR("afunc", afunc); /* 檢視程式碼段afunc函式位置 */ 21 printf("\nbss Location:\n"); 22 SHW_ADDR("bss_var", bss_var); /* 檢視BSS段變數的位置 */ 23 printf("\ndata Location:\n"); 24 SHW_ADDR("data_var", data_var); /* 檢視資料段變數的位置 */ 25 printf("\nStack Locations:\n"); 26 27 afunc(); 28 p = (char *)alloca(32); /* 從棧中分配空間 */ 29 if(p != NULL) { 30 SHW_ADDR("start", p); 31 SHW_ADDR("end", p+31); 32 } 33 34 b = (char *)malloc(32*sizeof(char)); /* 從堆中分配空間 */ 35 nb = (char *)malloc(16*sizeof(char)); /* 從堆中分配空間 */ 36 printf("\nHeap Locations:\n"); 37 printf("the Heap start: %p\n", b); /* 堆的起始位置 */ 38 printf("the Heap end: %p\n", (nb+16*sizeof(char))); /* 堆的結束位置 */ 39 printf("\nb and nb in Stack\n"); 40 41 SHW_ADDR("b", b); /* 顯示棧中資料b的位置 */ 42 43 SHW_ADDR("nb", nb); /* 顯示棧中資料nb的位置 */ 44 45 free(b); /* 釋放申請的空間 */ 46 free(nb); /* 釋放申請的空間 */ 47 }
afunc.c
1 /* afunc.c */ 2 #include <stdio.h> 3 #define SHW_ADDR(ID, I) printf("the %s\t is at addr:%p\n", ID, &I); /* 列印地址 */ 4 void afunc(void) { 5 static int long level = 0; /* 靜態資料儲存在資料段中 */ 6 int stack_var; /* 區域性變數儲存在棧區 */ 7 8 if(++level == 5) 9 return; 10 11 printf("stack_var%d is at: %p\n", level, &stack_var); 12 SHW_ADDR("stack_var in stack section", stack_var); 13 SHW_ADDR("level in data section", level); 14 15 afunc(); 16 }
gcc mem_add.c afunc.c進行編譯然後執行輸出的可執行的檔案,可得到如下結果(本機有效):

然後可以根據地址的大小來進行一個排序,並可視化:

如果執行環境不一樣,執行程式的地址與此將有差異,但是,各區域之間的相對關係不會發生變化。可以通過readelf命令來檢視可執行檔案的詳細內容。
readelf -a a.out
其他知識點
來看一個問題,下面程式碼的輸出結果是啥?
第一個檔案code1.c
1 #include <stdio.h> 2 #include <stdlib.h> 3 4 char* toStr() { 5 char *s = "abcdefghijk"; 6 return s; 7 } 8 9 int main(void) { 10 printf("%s\n", toStr()); 11 }
第二個檔案code2.c
1 #include <stdio.h> 2 #include <stdlib.h> 3 4 char* toStr() { 5 char s[] = "abcdefghijk"; 6 return s; 7 } 8 9 int main(void) { 10 printf("%s\n", toStr()); 11 }
其實我在用gcc編譯第二的時候已經有warning了:

第一個可以正常輸出,而第二個要麼亂碼,要麼是空的。
兩段程式碼都很簡單,輸出一段字元,型別不同,一個是char*字串,一個是char[]資料。
結果:第一個正確輸出,第二個輸出亂碼。
原因:在於區域性變數的作用域和記憶體分配的問題,第一char*是指向一個常量,作用域為函式內部,被分配在程式的常量區,直到整個程式結束才被銷燬,所以在程式結束前常量還是存在的。而第二個是陣列存放的,作用域為函式內部,被分配在棧中,就會在函式呼叫結束後被釋放掉,這時你再呼叫,肯定就錯誤了。
我發現了一個新的問題,如果你把這兩個檔案合成一個的話,第二個其實可以打印出正確的字元的,程式碼如下:
1 /* toStr.c演示記憶體分配問題哦 */ 2 3 #include <stdio.h> 4 #include <stdlib.h> 5 6 char* toStr1() { 7 char *s = "abcdefghijklmn"; 8 return s; 9 } 10 11 char* toStr2() { 12 char s[] = "abcdefghijklmn"; 13 return s; 14 } 15 16 void printStr() { 17 int a[] = {1,2,3,4,5,6,7}; 18 } 19 20 int main(void) { 21 printf("呼叫toStr1()返回的結果: %s\n",toStr1()); 22 printf("呼叫toStr2()返回的結果: %s\n",toStr2()); 23 // printStr(); 24 exit(0); 25 26 }
不知道為啥,第二個還是可以正常列印的。但是隻列印第二個,或者先列印第二個,然後在列印第一個的話,不輸出亂碼,倒是輸出空串。
顧名思義,區域性變數就是在一個有限的範圍內的變數,作用域是有限的,對於程式來說,在一個函式體內部宣告的普通變數都是區域性變數,區域性變數會在棧上申請空間,函式結束後,申請的空間會自動釋放。而全域性變數是在函式體外申請的,會被存放在全域性(靜態區)上,知道程式結束後才會被結束,這樣它的作用域就是整個程式。靜態變數和全域性變數的儲存方式相同,在函式體內宣告為static就可以使此變數像全域性變數一樣使用,不用擔心函式結束而被釋放。
- 棧區(stack)—由編譯器自動分配釋放,存放函式的引數值,區域性變數的值等。其操作方式類似於資料結構中的棧。
- 堆區(heap)—一般由程式設計師分配釋放,若程式設計師不釋放,程式結束時可能由OS回收。注意它與資料結構中的堆是兩回事,分配方式倒是類似於連結串列
- 全域性區(靜態區)(static)—全域性變數和靜態變數的儲存是放在一塊的,初始化的全域性變數和靜態變數在一塊區域,未初始化的全域性變數和未初始化的靜態 變數在相鄰的另一塊區域。 程式結束後由系統釋放。
- 常量區—常量字串就是放在這裡的,直到程式結束後由系統釋放。上面的問題就在這裡!!!
- 程式碼區—存放函式體的二進位制程式碼。
一般編譯器和作業系統實現來說,對於虛擬地址空間的最低(從0開始的幾K)的一段空間是未被對映的,也就是說它在程序空間中,但沒有賦予實體地址,不能被訪問。這也就是對空指標的訪問會導致crash的原因,因為空指標的地址是0。至於為什麼預留的不是一個位元組而是幾K,是因為記憶體是分頁的,至少要一頁;另外幾k的空間還可以用來捕捉使用空指標的情況。
char *a 與char a[] 的區別
char *d = "hello" 中的a是指向第一個字元‘a'的一個指標;char s[20] = "hello" 中陣列名a也是執行陣列第一個字元'h'的指標。現執行下列操作:strcat(d, s)。把字串加到指標所指的字串上去,出現段錯誤,本質原因:*d="0123456789"存放在常量區,是無法修的。而陣列是存放在棧中,是可以修改的。兩者區別如下:
讀寫能力:char *a = "abcd"此時"abcd"存放在常量區。通過指標只可以訪問字串常量,而不可以改變它。而char a[20] = "abcd"; 此時 "abcd"存放在棧。可以通過指標去訪問和修改陣列內容。
賦值時刻:char *a = "abcd"是在編譯時就確定了(因為為常量)。而char a[20] = "abcd"; 在執行時確定
存取效率:char *a = "abcd"; 存於靜態儲存區。在棧上的陣列比指標所指向字串快。因此慢,而char a[20] = "abcd"存於棧上,快。
另外注意:char a[] = "01234",雖然沒有指明字串的長度,但是此時系統已經開好了,就是大小為6-----'0' '1' '2' '3' '4' '5' '\0',(注意strlen(a)是不計'\0')