
JAVA 筆記(三) 從原始碼深入淺出集合框架
集合框架概述
以Java來說,我們日常所做的編寫程式碼的工作,其實基本上往往就是在和物件打交道。
但顯然有一個情況是,一個應用程式裡往往不會僅僅只包含數量固定且生命週期都是已知的物件。
所以,就需要通過一些方式來對物件進行持有,那麼通常是通過怎麼樣的方式來持有物件呢?
通過陣列是最簡單的一種方式,但其缺陷在於:陣列的尺寸是固定的,即陣列在初始化時就必須被定義長度,且無法改變。
也就說,通過陣列來持有物件雖然能解決物件生命週期的問題,但仍然沒有解決物件數量未知的問題。
這也是集合框架出現的核心原因,因為大多數時候,物件需要的數量都是在程式執行期根據實際情況而定的。
實際上集合框架就是Java的設計者:對常用的資料結構和演算法做了一些規範(介面)和實現(具體實現介面的類),而用以對物件進行持有的。
也就是說,最簡單的來說,我們可以將集合框架理解為:資料結構(演算法)+ 物件持有。與陣列相比,集合框架的特點在於:
- 集合框架下的容器類只能存放物件型別資料;而陣列支援對基本型別資料的存放。
- 任何集合框架下的容器類,其長度都是可變的。所以不必擔心其長度的指定問題。
- 集合框架下的不同容器類底層採用了不同的資料結構實現,而因不同的資料結構也有自身各自的特性與優劣。
而既然被稱為框架,就自然證明它由一個個不同的“容器”結構集體而構成的一個體系。
所以,在進一步的深入瞭解之前,我們先通過一張老圖來了解一下框架結構,再分而進之。
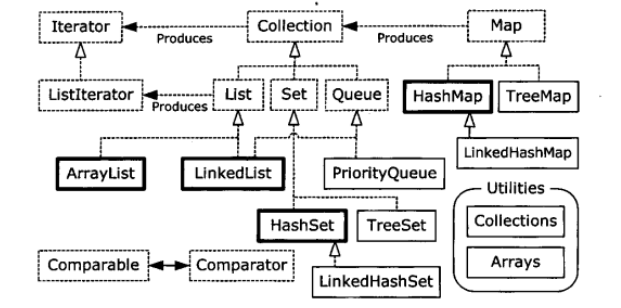
這張圖能體現最基本的“容器”分類結構,從中其實不難看到,所謂的集合框架:
主要是分為了兩個大的體系:Collection與Map;而所有的容器類都實現了Iterator,用以進行迭代。
總的來說,集合框架的使用對於開發工作來說是很重要的一塊使用部分。
所以在本篇文章裡,我們將對各個體系的容器類的使用做常用的使用總結。
然後對ArrayList,LinkList之類的常用的容器類通過原始碼解析來加深對集合框架的理解。
Collection體系
Java容器類的作用是“儲存物件”,而從我們前面的結構圖也不難看到,集合框架將容器分為了兩個體系。
體系之一就是“Collection”,其特點在於:一條存放獨立元素的序列,而其中的元素都遵循一條或多條規則。
相信你一定熟悉ArrayList的使用,而當你通過ArrayList一層層的去檢視原始碼的時候,就會發現:
它經歷了AbstractList → AbstractCollection → Collection這樣的一個繼承結構。
由此,我們也看見Collection介面正是位於這個體系之中的眾多容器類的根介面
既然Collection為根,瞭解繼承特性的你,就不難想象,Collection代表了位於該體系之下的所有類的最通性表現。
那我們自然有必要首先來檢視一下,定義在Collection介面當中的方法宣告:
- boolean add(E e) 確保此 collection 包含指定的元素(可選操作)。
- boolean addAll(Collection< ? extends E> c) 將指定 collection 中的所有元素都新增到此 collection 中(可選操作)。
- void clear() 移除此 collection 中的所有元素(可選操作)。
- boolean contains(Object o) 如果此 collection 包含指定的元素,則返回 true。
- boolean containsAll(Collection< ? > c) 如果此 collection 包含指定 collection 中的所有元素,則返回 true。
- boolean equals(Object o) 比較此 collection 與指定物件是否相等。
- int hashCode() 返回此 collection 的雜湊碼值。
- boolean isEmpty() 如果此 collection 不包含元素,則返回 true。
- Iterator< E > iterator() 返回在此 collection 的元素上進行迭代的迭代器。
- boolean remove(Object o) 從此 collection 中移除指定元素的單個例項,如果存在的話(可選操作)。
- boolean removeAll(Collection< ? > c) 移除此 collection 中那些也包含在指定 collection 中的所有元素(可選操作)。
- boolean retainAll(Collection< ? > c) 僅保留此 collection 中那些也包含在指定 collection 的元素(可選操作)。
- int size() 返回此 collection 中的元素數。
- Object[] toArray() 返回包含此 collection 中所有元素的陣列。
- < T > T[] toArray(T[] a) 返回包含此 collection 中所有元素的陣列;返回陣列的執行時型別與指定陣列的執行時型別相同。
上述的方法也代表將被所有Collection體系之下的容器類所實現,所以不難想象它們也就代表著使用Collection體系時最常使用和最基本的方法。
所以,我們當然有必要熟練掌握它們的使用,下面我們通過一個例子來小試身手:
public class CollectionTest {
public static void main(String[] args) {
Collection<String> c = new ArrayList<String>();
c.add("abc"); // 新增單個元素
Collection<String> sub = new ArrayList<String>();
sub.add("123");
sub.add("456");
c.addAll(sub); // 新增集合
c.addAll(Arrays.asList("111", "222"));
System.out.println("1==>" + c);
System.out.println("2==>" + c.contains("123")); // 檢視容器內是否包含元素"123"
System.out.println("3==>" + c.containsAll(sub));// 檢視容器c內是否包含容器sub內的所有元素
System.out.println("4==>" + c.isEmpty()); // 檢視容器是否為空
c.retainAll(sub);// 取容器c與sub的交集
System.out.println("5==>" + c);
c.remove("123"); // 移除單個元素
c.removeAll(sub);// 從容器c當中移除sub內所有包含的元素
System.out.println("6==>" + c);
c.add("666");
Object[] oArray = c.toArray();
String[] sArray = c.toArray(new String[] {});
System.out.println("7==>" + c.size() + "//" + oArray.length + "//"
+ sArray.length);
c.clear();
System.out.println("8==>"+c.size());
}
}上面演示程式碼的輸出結果為:
1==>[abc, 123, 456, 111, 222]
2==>true
3==>true
4==>false
5==>[123, 456]
6==>[]
7==>1//1//1
8==>0
到此,我們嘗試了Collection體系下的容器類的基本使用。其中還有一個很重要的方法“iterator”。
但這個方法並不是宣告在Collection介面當中,而是繼承自另一個介面Iterable。
所以,我們將它放在之後的迭代器的部分,再來看它的相關使用。
List 體系
事實上,通過對於Colleciton介面內的方法瞭解。我們已經發現,對於Collection來說:
實際上已經提供了對於物件進行新增,刪除,訪問(通過迭代器)等等一些列的基本操作。
那麼,為什麼還要在其之下,繼續劃出一個List體系呢?通過檢視原始碼,你可以發現List介面同樣繼承自Colleciton介面。
由此也就不難想到,List介面是在Collection介面的基礎上,又添加了一些額外的操作方法。
而這些額外的操作方法,其核心的用途概括來說都是:在容器的中間插入和移除元素(即操作角標)。
檢視Java的API說明文件,你會發現對於List介面的說明當中,會發現類似下面的幾段話:
- List 介面在 iterator、add、remove、equals 和 hashCode 方法的協定上加了一些其他約定,超過了 Collection 介面中指定的約定。。
- List 介面提供了特殊的迭代器,稱為 ListIterator,除了允許 Iterator 介面提供的正常操作外,該迭代器還允許元素插入和替換,以及雙向訪問。
上面的話中,很清楚的描述了List體系與Collection介面表現出的最共性特徵之外的,自身額外的特點。
那麼,我們也可以來看一下,在List介面當中額外新增的方法:
- void add(int index, E element) 在列表的指定位置插入指定元素(可選操作)。
- boolean addAll(int index, Collection< ? extends E > c) 將指定 collection 中的所有元素都插入到列表中的指定位置(可選操作)。
- E get(int index) 返回列表中指定位置的元素。
- int indexOf(Object o) 返回此列表中第一次出現的指定元素的索引;如果此列表不包含該元素,則返回 -1。
- int lastIndexOf(Object o) 返回此列表中最後出現的指定元素的索引;如果列表不包含此元素,則返回 -1
- ListIterator< E > listIterator() 返回此列表元素的列表迭代器(按適當順序)。
- ListIterator< E > listIterator(int index) 返回列表中元素的列表迭代器(按適當順序),從列表的指定位置開始。
- E remove(int index) 移除列表中指定位置的元素(可選操作)。
- E set(int index, E element) 用指定元素替換列表中指定位置的元素(可選操作)。
- List< E > subList(int fromIndex, int toIndex) 返回列表中指定的 fromIndex(包括 )和 toIndex(不包括)之間的部分檢視。
由此,我們看見,List介面相對於Collction介面,進行了新增或針對某些方法進行過載得工作, 從而得到了10個新的方法。
而從方法的說明當中,我們很容易發現它們存在一個共性,就是都存在著針對於角標進行操作的特點。
這也就是為什麼我們前面說,List出現的核心用途就是:在容器的中間插入和移除元素。
從原始碼解析ArrayList
前面我們已經說了不少,我們應該掌握了不少關於集合框架的內容的使用,至少了解了Collection與List體系。
但嚴格的來說,前面我們所做的都還停留在“紙上談兵”的階段。之所這麼說,是因為我們前面說到的都是兩個介面內的東西,即沒有具體實現。
那麼,ArrayList可能是我們實際開發中絕逼會經常用到的容器類了,我們就通過這個類為切入點,通過研究它的原始碼來真正的一展拳腳。
為了將思路儘量的理的比較清晰,我們先從該容器類的繼承結構說起,開啟ArrayList的原始碼,首先看到這樣的類宣告:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable我們對該容器類的宣告進行分析,其中:
- Cloneable介面是用於實現物件的複製;Serializable介面用於讓物件支援實現序列化。它們在這裡並非我們關心的重點,故不多加贅述。
- RandomAccess介面是一個比較有意思的東西,因為開啟原始碼你會發現這就是一個空介面,那麼它的用意何在?
通過註釋你其實可以很容易推斷出,這個介面的出現是為了用來對容器類進行型別判斷,從而選擇合適的演算法提高集合的迴圈效率的。
通常在對List特別是Huge size的List的遍歷演算法中,我們要儘量來判斷是屬於RandomAccess(如ArrayList)還是Sequence List (如LinkedList)。
這樣做的原因在於,因為底層不同的資料結構,造成適合RandomAccess List的遍歷演算法,用在Sequence List上就差別很大。
我們當然仍舊通過程式碼來進行驗證,因為實踐是檢驗理論的唯一標準:
public class CollectionTest {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<Integer>();
LinkedList<Integer> linkedList = new LinkedList<Integer>();
initList(arrayList);
initList(linkedList);
loopSpeed(ArrayList.class.getSimpleName(), arrayList);
iteratorSpeed(ArrayList.class.getSimpleName(), arrayList);
loopSpeed(LinkedList.class.getSimpleName(), linkedList);
iteratorSpeed(LinkedList.class.getSimpleName(), linkedList);
}
private static void initList(List<Integer> list) {
for (int i = 1; i <= 100000; i++) {
list.add(i);
}
}
private static void loopSpeed(String prefix, List<Integer> list) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
long endTime = System.currentTimeMillis();
System.out.println(prefix + "通過迴圈的方式,共花費時間:" + (endTime - startTime)
+ "ms");
}
private static void iteratorSpeed(String prefix, List<Integer> list) {
long startTime = System.currentTimeMillis();
Iterator<Integer> itr = list.iterator();
while (itr.hasNext()) {
itr.next();
}
long endTime = System.currentTimeMillis();
System.out.println(prefix + "通過迭代器的方式,共花費時間:" + (endTime - startTime)
+ "ms");
}
}
在我的機器上,這段程式執行的結果為:
ArrayList通過迴圈的方式,共花費時間:0ms
ArrayList通過迭代器的方式,共花費時間:15ms
LinkedList通過迴圈的方式,共花費時間:7861ms
LinkedList通過迭代器的方式,共花費時間:16ms
由此,你可以發現:
- 對於ArrayList來說,使用loop進行遍歷相對於迭代器速度要更加快,但這個差距相對還稍微能夠接受一點。
- 對於LinkedList來說,使用loop與迭代器進行遍歷的速度,相比之下簡直天差地別,迭代器要快上幾個世紀。
所以,如果在你的程式碼中想要針對於遍歷這個功能來提供一個足夠通用的方法。
我們就可以以上面的程式碼為例,對其加以修改,得到類似下面的程式碼:
private static <E> void loop(List<E> list) {
if (list instanceof RandomAccess) {
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
} else {
Iterator<E> itr = list.iterator();
while (itr.hasNext()) {
itr.next();
}
}
}是不是很給力呢?好了,廢話少說,我們接著看:
3.然後,至於List介面來說的話,我們在之前已經分析過了。它做的工作正是:
在Collection的基礎上,根據List(即列表結構)的自身特點,添加了一些額外的方法宣告。
4.同時可以看到,ArrayList繼承自AbstractList,而開啟AbstractList類的原始碼,又可以看到如下宣告:
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E>根據程式碼,我們又可以分析得到:
- AbstractList自身是一個抽象類。而其自身繼承自AbstractCollection,也就是說它又繼承自另一個抽象類。
- 而“public abstract class AbstractCollection< E > implements Collection< E >”則是AbstractCollection類的申明。
- 到此我們已經明確了我們之前說的“List → AbstractList → AbstractCollection → Collection”的繼承結構。
- 對於AbstractCollection來說,它與Collection介面的方法列表幾乎是完全一樣,因為它做的工作僅僅是:
覆寫了從Object類繼承來的toString方法用以列印容器;以及對Collection介面提供部分骨幹預設實現。- 而與AbstractCollection的工作相同,但AbstractList則負責提供List介面的部分骨幹預設實現。不難想象它們有一個共同的出發點則是:
提供介面的骨幹實現,為那些想要通過實現該介面來完成自己的容器的開發者以最大限度地減少實現此介面所需的工作。- 最後,AbstractList還額外提供了一個新的方法:
protected void removeRange(int fromIndex, int toIndex) 從此列表中移除索引在 fromIndex(包括)和 toIndex(不包括)之間的所有元素。
到這個時候,我們對於ArrayList類自身的繼承結構已經有了很清晰的認識。至少你知道了你平常用到的ArrayList的各種方法,分別都來自哪裡。
相信這對於我們使用Collection體系的容器類會有不小的幫助,下面我們就正式開始來分析ArrayList的原始碼。
- 構造器原始碼解析
首先,就像我們使用ArrayList時一樣,我們首先會做什麼?當然是構造一個容器物件,就像下面這樣:
ArrayList<Integer> arrayList = new ArrayList<Integer>();所以,我們首先從原始碼來看一看ArrayList類的構造器的定義,ArrayList提供了三種構造器,分別是:
//第一種
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "
+ initialCapacity);
this.elementData = new Object[initialCapacity];
}
//第二種
public ArrayList() {
this(10);
}
//第三種
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}我們以第一個構造器作為切入點,你會發現:等等?似乎什麼東西有點眼熟?
this.elementData = new Object[initialCapacity];沒錯,就是它。這時你有話要說了:我靠?如果我沒看錯,這不是。。。陣列。。。嗎?
其實沒錯,ArrayList的底層就是採用了陣列的結構實現,只不過它維護的這個陣列其長度是可變的。就是下面這個東西:
private transient Object[] elementData;於是,構造器的內容,你已經很容器能夠弄清楚了:
- 第一種構造器,可以接受一個int型的引數,它使用來指定ArrayList內部的陣列elementData的初始範圍的。
如果該引數傳入的值小於0,則會丟擲一個IllegalArgumentException異常。 - 第二種構造器,就更簡單了,它就在內部呼叫第一種構造器,並將引數值指定為10。
也就是說,當我們使用預設的構造器,內部就會預設初始化一個長度為10的陣列。 第三種構造器,接收Collection介面型別的引數。然後通過呼叫其toArray方法,將其轉換為陣列,賦值給內部的elementData。
完成陣列的初始化賦值工作後,緊接著做的工作就是:將代表容器當前存放數量的變數size設定為陣列的實際長度。
正常來說,第三種構造器所作的工作就是這麼簡單,但你肯定在意在這之後的兩行程式碼。在此先不談,我們馬上會講到。插入元素 原始碼解析
當我們初始化完成,得到一個可以使用的ArrayList容器物件後。最常做的操作是什麼?
答案顯而易見:通常我們都是對該容器內做元素新增、刪除、訪問等工作。
那麼,首先,我們就以新增元素的方法“add(E e)“為起點,來看看原始碼中它是怎麼做實現的?
public boolean add(E e) {
ensureCapacity(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}這就是ArrayList原始碼當中add方法的定義,看上去並不複雜,我們來加以分析:
1.首先,就可以看到其呼叫了另一個成員方法ensureCapacity(int minCapacity)。
2.該方法的註釋說明是這樣的:如有必要,增加此ArrayList例項的容量,以確保它至少能夠容納最小容量引數所指定的元素數。
3.也就是說,簡單來講該方法就是用來修改容器的長度的。我們來看一下該方法的原始碼:
public void ensureCapacity(int minCapacity) {
modCount++;
int oldCapacity = elementData.length;
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3) / 2 + 1;
if (newCapacity < minCapacity)
newCapacity = minCapacity;
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}- 首先看到了“modCount++”這行程式碼。這個變數其實是繼承自AbstractList類當中的一個成員變數。
而它的作用則是:記錄已從結構上修改此列表的次數。從結構上修改是指更改列表的大小,或者打亂列表。 - 所以,很自然的,因為在這裡我們往容器內添加了元素,自然也就會改變容器的現有結構。故讓該變數自增。
- 程式碼“int oldCapacity = elementData.length;”則是通過內部陣列的現有長度得到容器的現有容量。
- 接下來的工作就是判斷 我們傳入的“新容量(最小容量)”是否大於“舊容量”。這樣做的目的是:
如果新容量小於舊容量,則代表現有的容器已經足夠容納指定的數量,不必進行擴充工作;反之才需要對容器進行擴充。 - 當判斷後,發現需要對容器進行擴充後。首先,會宣告一個新的陣列引用來拷貝出原本elementData數組裡存放的元素。
- 然後,會通過“int newCapacity = (oldCapacity * 3) / 2 + 1;“來計算初步得到一個新的容量值。
如果計算得到的容量值小於我們傳入的指定的新的容量值,那麼就使用我們傳入的容量值。否則就使用計算得到的值作為新的容量值。
這兩步工作可能也值得說一下,為什麼有一個傳入的指定值“minCapacity”了,還額外做了這個“newCapacity”的運算。
其實不難想象到,這樣做是為了提高程式效率。假設我們通過預設構造器構建了一個ArrayList,那麼容器內部就有了一個大小為10的初始陣列了。
這個時候,我們開始迴圈的對容器進行“add”操作。不難想象當執行到第11次add的時候,就需要擴充陣列長度了。
那麼根據add方法自身的定義,這裡傳入的“minCapacity”值就是11。而通過計算得到的“newCapacity ”= (10 * 3)/2 +1 =16。
到這裡就很容易看到好處了,因為如果不進行上面的運算:那麼當超過陣列的初始長度後,每次add都需要執行陣列擴充的工作。
而因為newCapacity的出現,程式得以確保當執行第11次新增時,陣列擴充後,直到執行到第16次新增,都不需要進行擴充了。最後,就是最關鍵的一步,也就是根據得到的新的容量值,來對容器進行擴充工作。我們有必要好好看一看。
我們發現對於容器的擴充工作,是通過呼叫Arrays類當中的copyOf方法進行的。
當你點選原始碼進入後,你會發現,實際上,在該方法裡又呼叫了其自身的另一個過載方法:
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}由此,你可能也回憶起來,在我們上面說到的第三種構造器裡實際也用到了這個方法。所以,我們有必要來好好看一看:
- 首先,會通過一個三元運算子的表示式來計算傳入的newType是不是”Objcet[]”型別。
- 如果是,則會直接構造一個Objcet[]型別的陣列。如果不是,則會根據具體型別來進行構造。
- 具體構造的方式是通過呼叫Array類裡的newInstance方法,這個方法的說明是:
static Object newInstance(Class< ? > componentType, int length) 建立一個具有指定的元件型別和長度的新陣列。 - 其中引數componentType就是指陣列的元件型別。而在上面的原始碼中它是通過Class類裡的getComponentType()方法得到的。
該方法很簡單,就是來獲取表示陣列元件型別的 Class,如果元件不為陣列,則會返回“null”。
通過一段簡單的程式碼,我們能夠更形象的理解它的用法:
public static void main(String[] args) {
System.out.println(String.class.getComponentType()); //輸出結果為 null
System.out.println(String [].class.getComponentType());//輸出結果為 class java.lang.String
}- 接著,當執行完三元運算表示式的運算工作後,就會得到一個長度為”newLength”的全新的陣列“copy”了。
- 問題在於,此時的陣列”copy”內仍然沒有任何元素。所以我們還要完成最後一步動作,將源陣列當中的元素拷貝新的陣列當中。
- 拷貝的工作正是通過呼叫System類當中的navtie方法“arraycopy”完成的,該方法的說明為:
- public static void arraycopy(Object src, int srcPos, Object dest,int destPos, int length)
- 從指定源陣列中複製一個數組,複製從指定的位置開始,到目標陣列的指定位置結束。
- 從 src 引用的源陣列到 dest 引用的目標陣列,陣列元件的一個子序列被複制下來。被複制的元件的編號等於 length 引數。
- 源陣列中位置在 srcPos 到 srcPos+length-1 之間的元件被分別複製到目標陣列中的 destPos 到 destPos+length-1 位置。
- 到了這裡“ensureCapacity”方法就已經執行完畢了,內部的elmentData成功得以擴充。接下只要進行元素的存放工作就搞定了。
- 但這時候,不知道你還記不記得我們前面說到的一個東西:那就是第三種構造器中,在執行完toArray獲取陣列後,還進行了一個有趣的判斷如下:
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);- 思考一下為什麼會做這樣的判斷,實際上這樣做正是為了避免某種執行時異常。從程式碼的註釋得到的資訊是:
通過呼叫Collection.toArray()方法得到的陣列並不能保證絕對會返回Object[]型別的陣列。
通過下面的測試程式碼,我們就能驗證這種情況的發生:
public static void main(String[] args) {
Collection<String> c1 = new ArrayList<String>();
Collection<String> c2 = Arrays.asList("123");
System.out.println(c1.toArray().getClass()==Object[].class);//true
System.out.println(c2.toArray().getClass()==Object[].class);//false
System.out.println(c2.toArray().getClass());//class [Ljava.lang.String;
}從輸出結果我們不難發現,例如通過Arrays.asList方式得到的Collection物件,其呼叫toArray方法轉換為陣列後:
得到的就並非一個Object[]型別的陣列,而是String[]型別的陣列。也就說:如果我們使用c2來構造ArrayList,之前的陣列拷貝語句就變為了:
elementData = c.toArray();
//等同於:
Object [] elementData = new String[x];雖然說這樣做看上去並沒有什麼問題,因為有“向上轉型”的關係。進一步來說,上面的程式碼原理就等同於:
Object [] elementData = new Object[10];
String [] copy = new String [12];
elementData = copy;但這個時候如果在上面的程式碼的基礎上,再加上一句程式碼,實際上這的確也就是add方法在完成陣列擴充之後做的工作,就是:
elementData [11] = new Object();然後,執行程式碼,你會發現將得到一個執行時異常“java.lang.ArrayStoreException”。
如果想了解異常的原因可以參見:JDK1.6集合框架bug:c.toArray might (incorrectly) not return Object[] (see 6260652)
所以就像我們之前說的那樣,第三種構造器內新增這樣的額外判斷,正是出於程式健壯性的考慮。
這樣的原因,正是因為避免出現上述的情況,導致在陣列需要擴充之後,向擴充後的陣列內新增新的元素出現執行時異常的情況。
- 到了這時,我們終於可以回到“add”方法內了。之後的程式碼是簡單的“elementData[size++] = e;”
實際這行程式碼所做的工作就正如我們上面說到的一樣,陣列完成擴充後,此時則進行元素插入就行了。
同時在完成新增過後,將代表容器內當前存放的元素量的變數“size”的值進行一次自增。
到此,我們就完成了對新增元素的方法”add(E e)”的原始碼進行了一次完整的剖析。有沒有一丟丟成就感?
革命還得繼續,我們趁熱打鐵,馬上來看一看另一個新增元素方法的實現,即”add(int index, E element)“:
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException("Index: " + index + ", Size: "
+ size);
ensureCapacity(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1, size
- index);
elementData[index] = element;
size++;
}我們前面花了那麼多的功夫,在這裡應該有所見效。相信對於上面的程式碼,你已經很容易理解了。
- 首先,既然是通過角標來插入元素。那麼自然會有一個健壯性判斷,index大於容器容量或者小於0都將丟擲越界異常。
在這裡,額外說明一下,特別注意一個使用誤區,尤其是在我們剛剛分析完了前面的原始碼,信心十足的情況下。
我們一定要注意這裡index是與代表容器實際容量的變數size進行比較的,而不是與elmentData.length!!!
我們仍然通過實際操作,來更深刻的加深印象,來看這樣的一段程式碼:
ArrayList<String> list = new ArrayList<String>();
list.add(2, "123");我們可能會覺得這是可行的,因為在list完成構造後,內部的elmentData就會預設初始化為長度為10的陣列。
這時,通過”list.add(2, “123”);”來向容器插入元素,我們可能就會下意識的聯想到這樣的東西”elmentData[2] = “123”;”,覺得可行。
但很顯然的,實際上這樣做等待你的就是陣列越界的執行時異常。
- 接著,與add(E e)相同,這裡仍然會呼叫“ensureCapacity”來判斷是否進行陣列的擴充工作。有了之前的分析,我們不再廢話了。
- 接下來的程式碼,就是該新增方法能夠針對角標在容器中間進行元素插入工作的重點了,就是這兩句小東西:
System.arraycopy(elementData, index, elementData, index + 1, size
- index);
elementData[index] = element;System.arraycopy方法我們在之前也已經有過解釋。對應於上面的程式碼,它做的工作你是否已經看穿了?
沒錯,其實最基本的來說,我們可以理解為:“對elementData陣列從下標index開始進行一次向右位移”。
還是老辦法,通過程式碼我們能夠更形象直接的體會到其用處,就像下面做的:
public static void main(String[] args) {
String[] elmentData = new String[] { "1", "2", "3", "4", null };
int index = 2, size = 4;
System.arraycopy(elmentData, index, elmentData, index + 1, size - index);
System.out.print("[");
for (int i = 0; i < elmentData.length; i++) {
System.out.print(elmentData[i]);
if (i < elmentData.length - 1)
System.out.print(",");
}
System.out.print("]");
}以上程式的輸入結果為:”[1,2,3,3,4]“。也就是說,假設一個原本為”[1,2,3,4]”的陣列經過擴充後,
再呼叫原始碼當中的“System.arraycopy(elementData, index,elementData, index + 1, size - index);”,
最終得到的結果就是[1,2,3,3,4]也就是說,將指定角標開始的元素都向後進行了一次位移。
- 這個時候,再通過”elementData[index] = e;”來將指定角標的元素更改為新存放的值,不就達到在中間插入元素的效果了嗎?
所以說,對於向ArrayList容器中間插入元素的工作,我們歸納一下,發現實際上需要做的工作很簡單,不過就是:
將原本陣列中角標index開始的元素按指定位數(根據要插入的元素個數決定)進行位移 + 替換index角標的元素 = 在容器中間插入元素。
而這其實也解釋了:為什麼相對於LinkedList來說,ArrayList在執行元素的增刪操作時,效率低很多。
因為在陣列結構下,每當涉及到在容器中間增刪元素,就會產生蝴蝶效應波及到大量的元素髮生位移。
OK,又有進一步的收穫。到了這裡,對於插入元素的方法來說,還有另外兩個它們分別是:
addAll(Collection< ? extends E > c) 以及addAll(int index, Collection< ? extends E > c)。
在這裡,我們就不一一再分析它們的原始碼了,因為有了之前的基礎,你會發現,它們的核心思想都是一樣的:
都是先判斷是否需要對現有的陣列進行擴充;然後根據具體情況(插入單個元素還是多個,在中間插入還是在微端插入)進行元素的插入儲存工作。
有興趣可以自己看一下另外兩個方法的原始碼,相信對加深理解有不錯的幫助。
- 刪除元素 原始碼解析
看完了向容器新增元素的方法原始碼,接著,我們來看一看與之對應的刪除元素的方法的實現。
在這裡,我們首先選擇刪除方法”remove(int index)“作為切入點,來對原始碼加以分析:
public E remove(int index) {
RangeCheck(index);
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}- 首先就看到一個名為rangeCheck的方法呼叫,從命名就不難看出,這應該是做容器範圍檢查的工作的。檢視它的原始碼:
private void RangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException("Index: " + index + ", Size: "
+ size);
}- 由此,RangeCheck所做的工作很簡單:對傳入的角標進行判斷,如果它大於或等於容器的實際存放量,則報告越界異常。
- 接下來的一行程式碼,你已經很熟悉了。刪除元素自然也會改變容器的現有結構,所以讓該變數自增。
- 然後是根據該角標從內部維護的elementData陣列中,將該角標對應的元素取出。
- 之後的兩行程式碼就是刪除元素的關鍵,你可能會覺得有點熟悉。沒錯,因為其中心思想與插入元素時是一致的。
這個時候我們發現,其實在對於ArrayList來說,每當需要改變內部陣列的結構的時候,都是通過arrayCopy執行位移拷貝。不同在於:
- 刪除元素是將源陣列index+1開始的元素複製到目標陣列的index處。也就是說,與新增相反,是在做元素左移拷貝。
- 刪除元素時,用於指定陣列拷貝長度的變數numMoved不再是size - index而變為了size - index -1。
造成差異的原因就在於,在實現左移效果的時候,源陣列的拷貝起始座標是使用index+1而不再是index了。
- 接下來的一行程式碼則是“elementData[–size]”,它的效果一目瞭然,既是將陣列最後的一個元素設定為null。
註釋“// Let gc do its work”則說明,我們將元素值設為null。之後就由gc堆負責廢棄物件的清理。
到此你不得不說別人的程式碼確實寫的牛逼,remove裡的程式碼短短几行,卻思路清晰,且完全達到了以下效果:
要remove,首先進行rangeCheck,如果你指定要刪除的元素的index超過了容器實際容量size,則報告越界異常。
經過rangeCheck後,index就只會小於size。那麼通過numMoved就能判斷你指定刪除的元素是否位於陣列末端。
這是因為陣列的特點在於:它的下標是從0而非1開始的,也就是如果長度為x,最末端元素的下標就為x-1。
也就是說,如果我們傳入的index值如果恰好等於size-1,則證明我們要刪除的恰好是末端元素,
如果這樣則不必進行陣列位移,反之則需要呼叫System.arrayCopy進行陣列拷貝達到左移刪除元素的效果。到這裡我們就能確保,無論如何我們要做的就是刪除陣列末端的元素。所以,最後就將該元素設定為null,讓size自減就搞定了。
接下來,我們再看看另一個刪除方法”remove(Object o)“:
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}是不是覺得這個方法看上去也太輕鬆了,沒錯,實際上就是對陣列做了遍歷。
當發現有與我們傳入的物件引數相符的元素時,就呼叫fastRemove方法進行刪除。
所以,我們再來點開fastRemove的原始碼來看一下:
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work
}這個時候,我們已經胸有成竹了。因為你發現已經沒上面新鮮的了,上面的程式碼相信不用再多做一次解釋了。
你可能會提起,還有另外一個刪除方法removeAll。但檢視原始碼,你就會發現:
這個方法是直接從AbstractCollection類當中繼承來的,也就是說在ArrayList裡並沒有做任何額外實現。
- 訪問元素 原始碼解析
其實對於資料來說,所做的操作無非就是“增刪查改”。我們前面已經分析了增刪,接下來就看看“查”和“改”。
ArrayList針對於這兩種操作,提供了”get(int index)“和”set(int index, E element)“方法。
其中”get(int index)“方法的原始碼如下:
public E get(int index) {
RangeCheck(index);
return (E) elementData[index];
}。。。。。簡單到我們甚至懶得解釋。首先仍然是熟悉的RangeCheck,判斷是否越界。然後就是根據下標從陣列中查詢並返回元素。
是的,就是這麼容易,就是這麼任性。事實上這也是為什麼ArrayList對於隨機訪問元素的執行速度快的原因,因為基於陣列就是這麼輕鬆。
那麼再來看一看”set(int index, E element)“的原始碼吧:
public E set(int index, E element) {
RangeCheck(index);
E oldValue = (E) elementData[index];
elementData[index] = element;
return oldValue;
}不知道你是不是已經覺得越來越沒難度了。的確,因為硬骨頭我們在之前都啃的差不多了。。。
上面的程式碼歸根結底就是一個通過角標對陣列元素進行賦值的操作而已。老話,基於陣列就是這麼任性。。
- 其它的常用方法 原始碼解析
事實上到了這裡,關於容器最核心部分的原始碼(增刪改查)我們都瞭解過了。
但我們也知道除此之外,還有許多其它的常用方法,它們在ArrayList類裡是怎麼實現的,我們就簡單來一一瞭解一下。
- size();
public int size() {
return size; //似乎都沒什麼好說的!! - -!
}- isEmpty();
public boolean isEmpty() {
return size == 0; //。。依舊。。沒什麼好說的。。。
}- contains
public boolean contains(Object o) {
//內部呼叫indexOf方法,indexOf是查詢物件在陣列中的位置(下標)。如果不存在,則會返回-1.所以如果該方法返回結果>=0,自然容器就包含該元素
return indexOf(o) >= 0;
}- indexOf(Object o)
// 核心思想也就是對陣列進行遍歷,當遍歷到有元素符合我們傳入的物件時,就返回該元素的角標值。如果沒有符合的元素,則返回-1。
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i] == null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}- lastIndexOf(Object o)
// 與indexOf方法唯一的不同在於,這裡選擇將陣列從後向前進行遍歷。所以返回的值就將是元素在數組裡最後出現的角標。同樣,如果沒有遍歷到,則返回-1。
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size - 1; i >= 0; i--)
if (elementData[i] == null)
return i;
} else {
for (int i = size - 1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}- Object[] toArray() 與 public T[] toArray(T[] a)
public Object[] toArray() {
//也就是說,底層仍然是通過Arrays.copyOf進行轉換。
//另外,這行程式碼在底層等同於:Arrays.copyOf(elementData, size,Object[].class);
return Arrays.copyOf(elementData, size);
}
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
/*
* 上面的英文註釋是原始碼自身的註釋,從原始碼中的註釋就可以發現,
* 這裡是在程式執行時根據實際型別返回對應型別的陣列物件。
* 例如傳入的a是String[],就將返回String型別的陣列。
* 這也是與Object[] toArray()方法的不同。*/
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
// 熟悉的陣列拷貝的工作,注意這裡的目標陣列是“a”。
// 也就是說,這裡做的工作是將elementData作為源陣列,將其中的元素拷貝到a當中,然後返回。
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}- clear()
public void clear() {
modCount++;
// Let gc do its work
// 遍歷陣列,將元素全部設