
從全域名中提取根域名
1、前言
最近因為工作需要判斷一個域名是否備案,實際提取的域名就是HTTP報文中的Host的內容,而判斷一個域名是否是根據根域名進行的。例如訪問www.qq.com,提取Host的內容為www.qq.com,而判斷這個域名是否備案,是通過qq.com進行,因此需要從Host內容中提取出根域名。
遇到的問題
1、頂級域名的種類存在以下不同情況,例如 www.google.com www.google.com.cn 頂級域名分別是.com 和.com.cn提取頂級名分別為google.com goolge.com.cn
2、Host的長度不一,例如 api.best.com upload.api.best.com 提取的根域名都為best.com
解決思路:
解析Host, 例如 api.upload.qq.com 大概的思路如下:
1、先計算出域名中每個點(.)在字串中的位置
2、然後根據Host中點個個數提取出頂級域名,判斷頂級域名是否在hash表
3、找到頂級域名後,再提取頂級域名的根域名,組合起來就組成了最終的結果
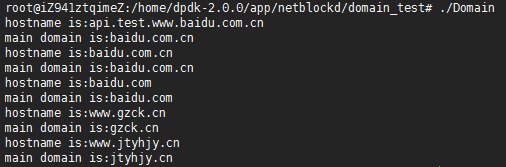
測試結果如下圖所示:
相關推薦
從全域名中提取根域名
1、前言 最近因為工作需要判斷一個域名是否備案,實際提取的域名就是HTTP報文中的Host的內容,而判斷一個域名是否是根據根域名進行的。例如訪問www.qq.com,提取Host的內容為www.qq.com,而判斷這個域名是否備案,是通過qq.com進行,因此需要從Host內容中提取出根域名。
python 從給定的URL中提取頂級域名(TLD)
安裝 PyPI的最新穩定版本: 1 pip install tld 或者GitHub的最新穩定版本: 1 pip install https://github.com/barseghyanartur/tld/archive/stable.tar.gz 或BitBucket的最新穩定版本: 1 點選安
dos怎麼從檔案全路徑中提取檔名
dos怎麼從檔案全路徑中提取檔名 使用 %~n 這個變數替換模式。 例如在 cmd 中: set str=techcomp/menu/navigator/outlook/childMenu.js for %a in ("%str%") do (echo %~na) 輸出
從視頻中提取圖片,對圖片做人臉檢測並截取人臉區域
rep pan details 一個 ons sprintf imread href multipl 環境配置:VS2013+opencv2.4.10+libface.lib 參考博客:http://blog.csdn.net/augusdi/article/details
[SimplePlayer] 4. 從視訊檔案中提取音訊
提取音訊,具體點來說就是提取音訊幀。提取方法與從視訊檔案中提取影象的方法基本一樣,這裡僅列出其中的不同點: 1. 由於目的提取音訊,因此在demux的時候需要指定的是提取audio stream AudioStream = av_find_best_stream(pFormatCtx, AVMEDIA_T
編寫了一個自動從編碼log中提取資料的程式
筆者這半年來一直是自己手動將編碼後的資料一個一個敲到excel中的,真是笨的可以,今天終於下定決心寫個小程式。 首先感謝下面的博主: https://blog.csdn.net/sruru/article/details/7911675 告訴了我怎麼在main函式傳入引數 ht
Java實現從Html文字中提取純文字
1、應用場景:從一份html檔案中或從String(是html內容)中提取純文字,去掉網頁標籤; 2、程式碼一:replaceAll搞定 //從html中提取純文字 public static String StripHT(String strHt
使用Java從分層目錄中提取所有檔名
1.建立名為TestRecursiveDirectoryTraversal的主類 package testrecursivedirectorytraversal; import java.io.File; import java.util.HashSet; import
如何用Python從PDF檔案中提取文字詞彙
在日常工作中,有時可能需要解析一些 PDF 檔案,提取檔案中的關鍵詞,好讓它們能夠被我們搜尋。解決這個問題的重要部分就是找到如何從 PDF 檔案中提取文字資料的方法。從如果是幾張或者幾十張倒還好辦,那要是幾百幾千張,可能就有點麻煩了。 幸好我們可以用 Python 完成這項工作。下面就分享
【C語言練習題】編寫一個函式,它從一個字串中提取一個子字串
《C與指標》 習題 4.14 編寫一個函式,它從一個字串中提取一個子字串。函式原型如下: int substr(char dst[], char src[],int start, int l
從文本中提取圖片路徑(java 解析富文本處理 img 標簽)
element load select 方法 info 正則 項目 lis new 很多項目都需要到富文本來添加內容,就好比新聞啊,旅遊景點之類的,都需要使用富文本去添加數據,然而怎麽我這邊就發現了兩個問題 怎樣將富文本的圖片的 src 獲取出來? 方法一: 利用正則表達式
【小工具】——從文字內容中提取日期時間
需求 需要從文字檔案中提取中時間及日期 程式碼 “`java /** * 從文字內容中提取日期時間 * @param text 包含日期時間的文字(格式:yy
使用FFMPEG從MP4封裝中提取視訊流到H264檔案
命令列: ffmpeg -i 20130312_133313.mp4 -codec copy -bsf: h264_mp4toannexb -f h264 20130312_133313.264 說明: -i 20130312_133313.mp4 :是輸入的MP4檔
使用FFMPEG從MP4封裝中提取視訊流到.264檔案
命令列: ffmpeg -i 20130312_133313.mp4 -codec copy -bsf: h264_mp4toannexb -f h264 20130312_133313.264 說明: -i 20130312_133313.mp4 :是輸入的MP4檔案
postgresql 從json陣列中提取json值,並分組,彙總
postgresql 從json陣列中提取json值,並分組,彙總 json資料 {"os": "Android", "chn": "-1", "dan": 0, "sex": 0, "file": "lv_statistics", "time": "2017-01-
微信小程式-中處理json資料 (從json資料中提取想要的值 將變數json字串轉成json物件)
1、新增依賴 <dependency> <groupId>net.sf.json-lib</groupId> <artifactId>jso
如何從海量IP中提取訪問最多的10個IP
演算法思想:分而治之+Hash 1、IP地址最多有2^32=4G種取值情況,所以不能完全載入到記憶體中處理; 2、可以考慮採用分而治之的思想,按照IP地址的Hash(IP) % 1024的值,把海量IP日誌分別儲存到1024個小檔案中,這樣,每個小檔案最多包含4MB個IP地址; 這樣的話,通過計算IP的
基於Zlib實現的從ZIP檔案中提取檔案資料
[cpp] view plaincopyprint? ZEXTRACT_API int GetFileInZip(CMemBuffer& buffer,constchar* zfn,constchar* fname,constchar* password){ unzFile uf = u
一行命令從 APK 檔案中提取 Endpoint 及 URL
做IoT的人免不了要接觸Android,接觸Android的人又免不了要研究別人的App應用。Diggy,一款能夠從 apk 檔案中提取 endpoint 及 URL 的工具,只要一行命令就可以幫大家提取出相關Android apk檔案的安裝資訊和網際網路訪問資訊。下載地址:
從文字內容中提取有效資訊
例如a.txt中有如下內容$ABC,eqwe,0123,N,we23,E,234$ABD,fkjd,2454,N,fwer,E,456$AB,fhew,9478,N,wewf,E,rnju$ABC,we