
論文閱讀筆記2
作者資訊:Sofiyanti Nery這個作者寫的論文不是很多,但是他的個人主頁上有很多關於深度學習模型的解釋和自己做的若干實驗,是少數幾個把深度學習講的特別清楚透徹的人了。
發表日期:2015,2
發表期刊/會議:IEEE Transactions on Neural Networks &Learning Systems。
被引量:27
主要內容:這篇文章指出CNN存在的問題:神經網路不能像人類一樣地持續思考,而是丟掉以前知識重新學習。這一點是不符合人類的認知過程的,因為人的學習過程是積累知識的過程,此刻的思考離不開以前學習的知識,因此為了能讓機器持續地思考,引入了迴圈神經網路的結構,把前面學習到的知識傳遞給下一個節點,一環扣一環地向後傳播,直到輸出結果。如下圖1所示:

圖1 迴圈神經網路工作圖
這個網路把輸入序列做了鏈式展開,每個節點分別處理輸入,並且把學習到的資訊傳遞給下一個節點,這種做法能夠讓資訊的得到了有效的傳遞,並且在很多領域都獲得了可喜的成績,包括語音識別、語言模型、機器翻譯、影象字幕等,都用到了RNN的變形LSTM,這是一種特殊的RNN,在很多應用上,LSTM的效果比標準RNN要好很多。於是接下來介紹了LSTM模型。
RNN被選擇的原因在於它可以連線前面的資訊為當前節點所用,就像人積累了一定的知識,可以作為現在理解事物所用。但是事實上,判斷一個事情有時候不需要所有的知識,只需要一些知識片段就可以,比如要理解文章中的一個句子,只需要根據上下文來理解即可,不需要利用以前獲得的所有的知識。或者說利用以前的知識可能會導致誤判,因此並不是把所有的知識聯絡起來就可以獲得正確的決策,而是需要捨棄一些,這就是LSTM的由來。
作者給網路增加gate來做取捨,很多人把gate翻譯為門,可以增進對模型的理解。在對事情進行判斷的時候,我們要對知識進行適量取捨,有用的資訊留下,沒有的資訊需要暫時遺忘,因此取捨的這個過程我們用gate來模擬,通過遺忘門,把不需要的知識過濾掉,留下有用的資訊來做出決策。
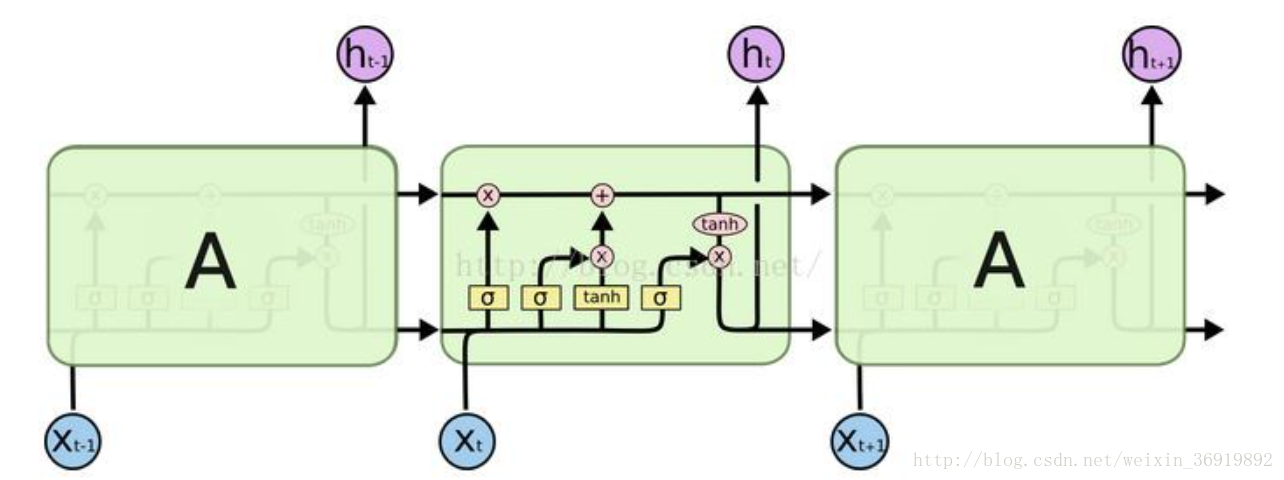
圖2 長短期記憶模型(LSTM)工作原理圖
如圖2所示,LSTM整個結構就是一個鏈式的傳送帶,LSTM和RNN的區別在於有兩條水平帶,上面的水平帶傳送有用的資訊,下面的水平帶中處理輸入資料,並且增加了一個門,過於資訊的過濾,如果不需要,可以通過遺忘門來刪除資訊,只通過有用的資訊。對於資訊也有不同的處理方式,是完全有用還是部分有用,因此設定了三個門來判段,sigmoid層的輸出介於0和1之間,輸出為0表示不通過,輸出為1表示都通過,一個LSTM通過這樣的二門來控制和保護cell state。
具體的如何選擇資訊以及LSTM的變體就不一一展開,這篇文章從原理上展示了長短期記憶模型是如何工作並且獲得有用資訊的,講述的很到位,有茅塞頓開的感覺。感覺深度網路模型也不是什麼深不可測的東西,主要還是靠平時的積累和學習就可以理解和應用。
閱讀心得: 長短期記憶模型可以用於做服務質量的預測,由於長短期記憶模型有記憶的特性,可以學習到服務質量隨著時間變化的潛在特點,並且捨棄無用資訊,利用有用特徵來判斷下一個時間點的服務質量。查詢論文當前並沒有基於長短期記憶模型,分析了一下原因,主要有如下幾點:
1. 長短期記憶模型是一個很新的概念,目前應用領域僅僅在影象識別自動生成字幕、語音識別、實時翻譯等,最新的服務質量的預測是BP神經網路,這個模型已經很老了,並沒有創新。
2. 很多文章都在研究如何做插值預測,就是填補矩陣的空值,進而做基於QoS的服務選擇和服務推薦。然而服務推薦現在都基於已有的服務質量資料來推薦,並不是實時推薦。
3. 服務質量的資料不太好收集,之前做實驗的資料集是SCI文章發表的一個公開資料集,大家都在使用這個資料集來做文章。該資料集的特點是服務、使用者、服務質量,沒有基於時間序列的資料集,因此其它的學者也就沒有研究基於時間序列的預測。
因此這應該是一個很好的題材,可以寫出好文章。那麼接下來就應該收集足夠的基於時間序列的服務質量資料,搭建window下的tensorflow環境來寫基於LSTM的學習模型。