
word2vec詞向量訓練及gensim的使用
一、什麼是詞向量
詞向量最初是用one-hot represention表徵的,也就是向量中每一個元素都關聯著詞庫中的一個單詞,指定詞的向量表示為:其在向量中對應的元素設定為1,其他的元素設定為0。採用這種表示無法對詞向量做比較,後來就出現了分散式表徵。
在word2vec中就是採用分散式表徵,在向量維數比較大的情況下,每一個詞都可以用元素的分散式權重來表示,因此,向量的每一維都表示一個特徵向量,作用於所有的單詞,而不是簡單的元素和值之間的一一對映。這種方式抽象的表示了一個詞的“意義”。
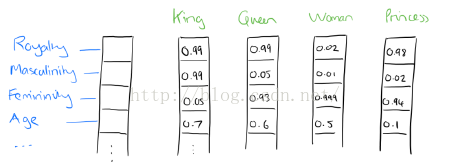
二、詞向量推理
實際上,被學習的詞向量表示是用一種非常簡單的方式捕捉有意義的語法和語義規律。具體來說,對於一個特定關係的片語,語法規律可以看作固定的向量偏移。
三、學習詞向量
word2vec的兩種形式:CBOW和Skip-gram模型
(1)CBOW
CBOW去除了上下文各詞的詞序資訊,使用上下文各詞的平均值。
例如一段散文“The recently introduced continuous Skip-gram model is an efficient method
for learning high-quality distributed vector representations that capture a large number of precises syntatic and semantic word relationships.”,想象這段文字上有一個滑動視窗,包括當前的詞和前後的四個詞。具體如下圖:

上下文片語成了輸入層,每一個詞都用one-hot形式來表示,如果詞彙量是V,則每個詞就表示成V維向量,相應的詞對應元素被設定成1,其餘的為0。下圖表示一個單隱層和一個輸出層。
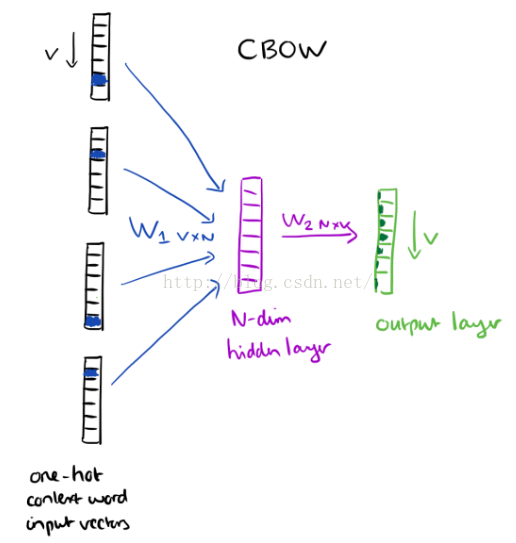
訓練的目標是最大限度的觀察實際輸出詞(焦點詞)在給定輸入上下文且考慮權重的條件概率,在我們的例子中,給出了輸入(“一個”,“有效”,“方法”,“為”,“高”,“質量”,“分散式”,“向量”),我們要最大限度的獲得“學習”作為輸出的概率。
由於我們的輸入向量是用one-hot來表示的,與權重矩陣W1相乘就相當於簡單的選擇W1中的一行。
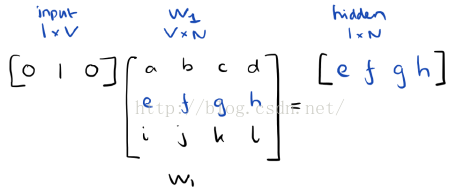
如果輸入了C個詞向量,隱層的啟用函式其實就是用來統計矩陣中的熱點行,然後除以C來取平均值。這意味著,隱含層單元的啟用函式就是簡單的線性運算(直接將權重和作為下一層的輸入)。
從 隱層到輸出層,我們用一個權重矩陣W2來為每一個詞計算詞彙表中的得分,然後使用softmax來計算詞的後驗分佈。
(2)skip-gram
skip-gram和CBOW正好相反,它使用單一的焦點詞作為輸入,經過訓練然後輸出它的目標上下文,如下圖所示:
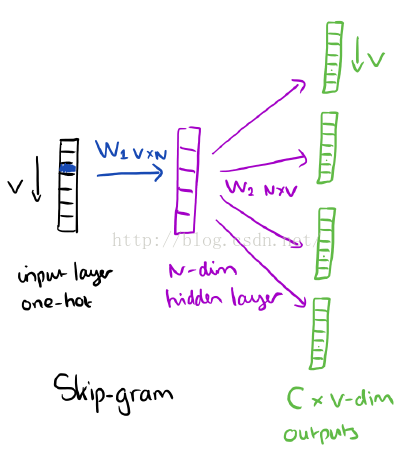
正如之前提到的,隱層的啟用函式只是權重矩陣W1對應行的簡單統計。在輸出層,我們輸出C個詞向量。訓練的最終目標就是減少輸出層所有上下文詞的預測錯誤率。例如,如果輸入“learn”,我們可能在輸出層得到“an”,“efficient”,“method”,“for”,“high”,“quality”,“distributed”,“vector”。
四、優化
在一個訓練例項中,為每一個詞輸出詞向量代價是非常大的,所以我們提供了兩種優雅的方法,一個是基於層級的softmax函式,另一個是負取樣。
(1)層級softmax函式
層級softmax函式是用一個二叉樹來表示詞彙表中的所有單詞,樹中的每個葉子節點表示一個單詞,對於每一個葉子,都存在唯一的從根到葉節點的路徑,這條路徑是用來估計被葉節點所表示的單詞的概率,這個概率定義為從根節點隨機遊走到該葉節點的概率。
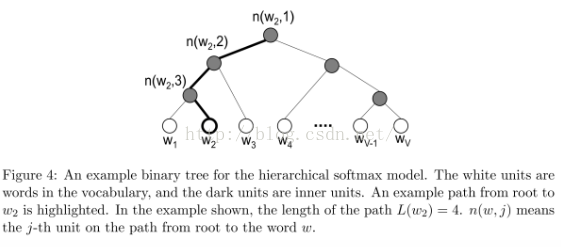
這樣的好處是不用對V個節點一一評估來獲得神經網路中的概率分佈,而是隻用評估log2(V)個節點。在這裡,我們使用二叉哈夫曼樹,因為它給高頻詞彙賦予更短的編碼,這樣訓練過程就變快了。
(2)負取樣
負取樣就是每一次迭代,我們只更新輸出詞的一個樣本。目標輸出詞應該被留在樣本中且被更新,我們還要加入一些(非目標)詞作為負樣本,Milokov等人也用一個簡單的二次取樣方法來抑制訓練集中稀疏詞和高頻詞之間的不平衡性(例如,“in”,“the”,“a”比稀疏詞提供更少的資訊),具體而言,如果詞wi 在語料中的出現頻率f(wi) 大於閾值t,則有P(wi) 的概率在訓練時跳過這個詞。訓練集中每一個詞都有一個丟棄概率P(wi).
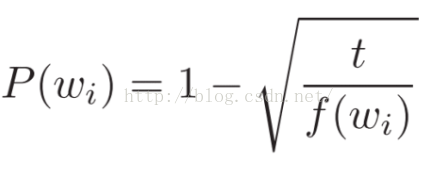
f(wi)是詞wi的頻率,t是一個選擇的閾值,一般值在10**-5附近。
python中gensim庫word2vec的使用:
pip install gensim安裝好庫後,即可匯入使用:
1、訓練模型定義
from gensim.models import Word2Vec
model = Word2Vec(sentences, sg=1, size=100, window=5, min_count=5, negative=3, sample=0.001, hs=1, workers=4)
1.sg=1是skip-gram演算法,對低頻詞敏感;預設sg=0為CBOW演算法。
2.size是輸出詞向量的維數,值太小會導致詞對映因為衝突而影響結果,值太大則會耗記憶體並使演算法計算變慢,一般值取為100到200之間。
3.window是句子中當前詞與目標詞之間的最大距離,3表示在目標詞前看3-b個詞,後面看b個詞(b在0-3之間隨機)。
4.min_count是對詞進行過濾,頻率小於min-count的單詞則會被忽視,預設值為5。
5.negative和sample可根據訓練結果進行微調,sample表示更高頻率的詞被隨機下采樣到所設定的閾值,預設值為1e-3。
6.hs=1表示層級softmax將會被使用,預設hs=0且negative不為0,則負取樣將會被選擇使用。
7.workers控制訓練的並行,此引數只有在安裝了Cpython後才有效,否則只能使用單核。
詳細引數說明可檢視word2vec原始碼。
2、訓練後的模型儲存與載入
model.save(fname)
model = Word2Vec.load(fname)3、模型使用(詞語相似度計算等)
model.most_similar(positive=['woman', 'king'], negative=['man'])
#輸出[('queen', 0.50882536), ...]
model.doesnt_match("breakfast cereal dinner lunch".split())
#輸出'cereal'
model.similarity('woman', 'man')
#輸出0.73723527
model['computer'] # raw numpy vector of a word
#輸出array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)