Facebook資料中心網路架構概覽
背景
Facebook的使用者已經超過10多億,而且還在迅速增長。為了能夠給使用者提供實時的體驗,Facebook為資料中心設計了一個高可擴充套件,高效能的網路架構 data center fabric。
雖然這個網路架構實際上在14年已經實施了,但是其中的一些設計理念在今天的一些資料中心裡依然有很好的參考價值。
傳統的挑戰
下面首先看看Facebook在如此大的使用者規模下,將會面臨哪些挑戰。這些Facebook曾經走過的路也是其他在發展中的資料中心將要面臨貨已經面臨的問題。
高速發展
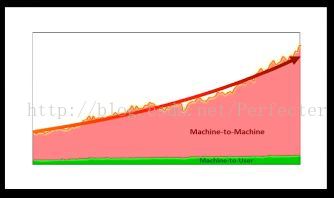
首先,隨著使用者數量的急劇增長,業務規模不斷擴大,資料中心的公網出口流量非常大,並且還在持續增長。與此同時,資料中心內部的流量比公網流量大幾個數量級。
在Facebook的資料中心內部,後端分層的服務和程式都是分散式且在邏輯上互聯的。這些服務為前段使用者提供實時的體驗。雖然有不斷地優化,但是流量在一年內還是會翻番。
所以支援高速發展的能力將成為設計基礎設施的核心理念。同時還要保證網路架構足夠精簡,易於管理。
如下圖,綠色的部分是公網流量的增長速度,紅色是內部流量的增長。
Cluster的侷限
傳統的資料中心的網路是以Cluster為基礎建設的。一個Cluster中部署上百個機架,每個機架裡有交換機,並且這些交換機再接入到效能更好的匯聚交換機上。
雖然Facebook之前也做過一些改進,比如開發了一個“four-post”的layer3架構,提供3+1的叢集交換機冗餘,能力是以前的10倍。但這種架構還是基於Cluster的,還是有一些限制。首先,Cluster的規模受到交換機埠密度的影響。這些高效能、大規格的交換機往往集中在某幾家廠商手裡,也就是說受到廠商的制約。其次,硬體效能的增長往往趕不上業務的需求。而且這些高階的硬體往往都有獨特的內部架構,需要具備額外的硬體和軟體知識才能很好地駕馭,這無疑又是一個打擊。在大規模場景下,軟硬體的失效問題也成為很重要的考慮點。
更難的在於,需要在叢集規模、內部頻寬、外部頻寬之間做出平衡。實際上,Cluster這個概念也就源自於這些網路的限制。叢集簡單講,就是部署在高效能網路池內的大規模計算資源,而往往人們假設叢集之間的流量遠遠小於叢集內部的流量,基於這個假設,一些需要互動的程式往往就部署在同一個叢集內。這實際上就限制了服務的規模,大規模的服務都是分散式的,不應該有這個限制。
fabric網路
Facebook的下一代網路的宗旨就是整個資料中心建立在一套高效能網路之上,而不是分層的Cluster系統。而且能夠快速的擴充套件規模和效能,每次擴容時,都不會影響已經部署的基礎架構。
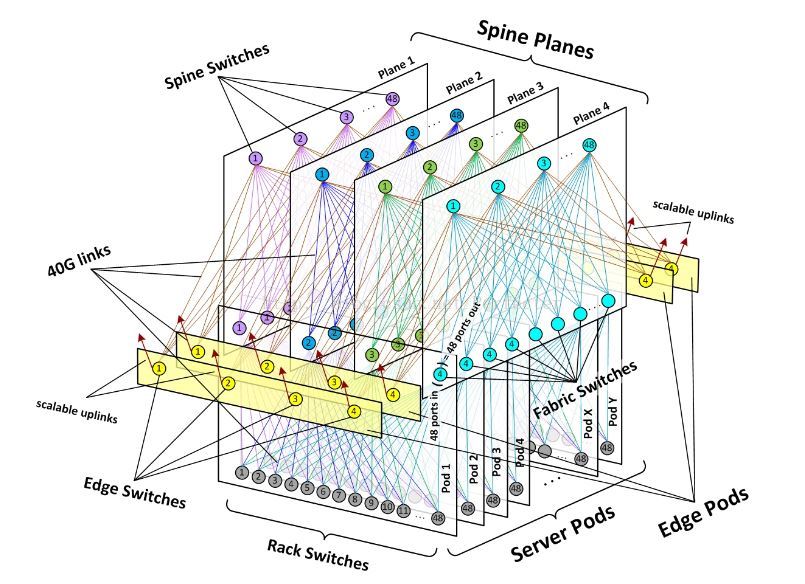
為了達到這個目的,Facebook將網路分解成為小的單元——server pod,並且pod直接全互聯。
fabric
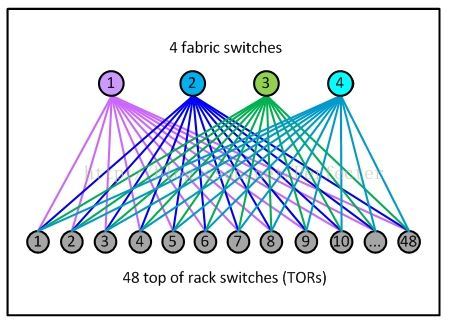
如下圖,一個pod裡面最多有48個機架,每個機架和4個fabric交換機相連,每個機架交換機有4*40G總共160G的出口頻寬。機架內部的伺服器之間10G互聯
spine
pod之間的互聯依靠下圖的spine交換機,每個spine平面最多有48個獨立的spine交換機。這樣一來,pod之間就形成了一個高效能的全網際網路絡。
而edge平面的交換機則負責出口流量。
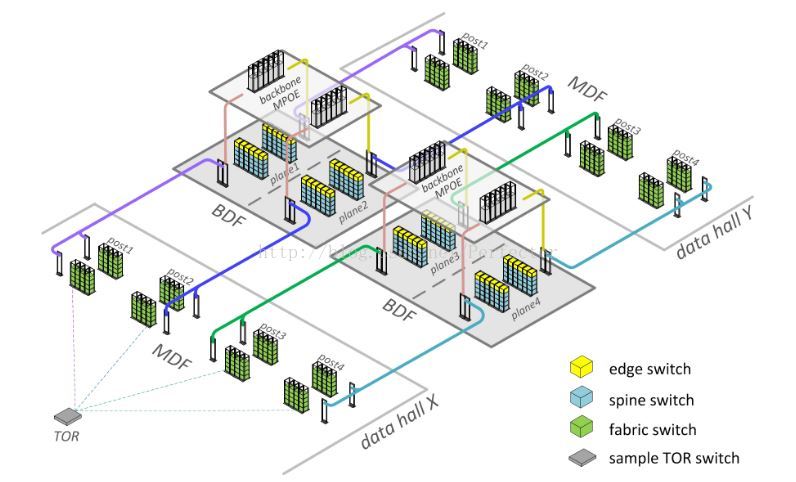
物理架構
如下圖可以看到,專門用於放置各類交換機的機架規模也不小
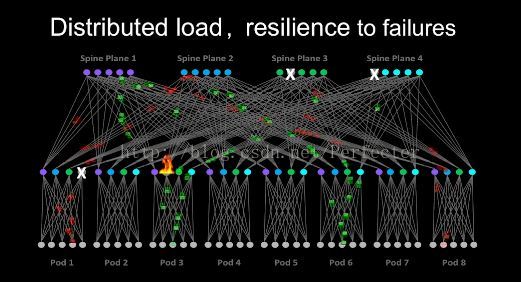
效果
如下圖可以看出,所有機架之間的路基可能有多種,路徑根據流量的負責自動選擇,能夠容忍若干網路路徑的故障。