c++執行緒併發:mutex,atomic,自旋鎖spinlock,單執行緒
阿新 • • 發佈:2018-12-30
自旋鎖直接呼叫了boost庫的#include <boost/smart_ptr/detail/spinlock.hpp>
測試執行緒併發的情況下耗時,不太明白為什麼boost的spinlock效率這麼低,還是說boost的spinlock是有其它專業用途...
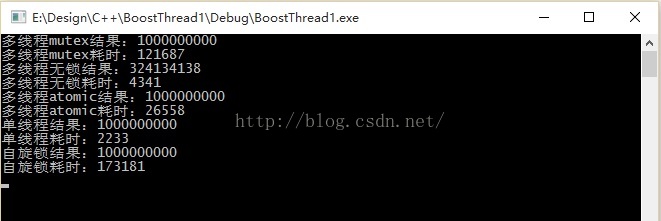
在一個共有資源的情況下,
由於任務的簡單性,只是++,單執行緒最快
多執行緒無鎖次之,但是結果錯誤
atomic原子操作耗時稍長,但由於原子操作的關係,結果正確
mutex 效能損失比較大,為atomic的4倍左右,雖然保證了結果的正確性,但是耗時卻是原來的10多倍
boost spinlock效率墊底了,不太明白細節,等下研究一下
是鎖競爭的關係?還是核心態和使用者態切換的關係?
請明白的大神指點
不過有一點給自己提了個醒,在不瞭解鎖機制的情況下還是得慎用
下面是程式碼:
// BoostThread1.cpp : 定義控制檯應用程式的入口點。 // #include "stdafx.h" #include <boost/lambda/lambda.hpp> #include <iostream> #include <iterator> #include <algorithm> #include <boost/thread/thread.hpp> #include <boost/atomic.hpp> #include <boost/smart_ptr/detail/spinlock.hpp> #include "time.h" //在一個共有資源的情況下, //由於任務的簡單性,只是++,單執行緒最快 //多執行緒無鎖次之,但是結果錯誤 //atomic原子操作耗時稍長,但由於原子操作的關係,結果正確 //mutex 效能損失比較大,為atomic的4倍左右,雖然保證了結果的正確性,但是耗時卻是原來的10多倍 //boost spinlock效率墊底了,不太明白細節,等下研究一下 //是鎖競爭的關係?還是核心態和使用者態切換的關係? //請明白的大神指點 //不過有一點給自己提了個醒,在不瞭解鎖機制的情況下還是得慎用 long total = 0; boost::atomic_long total2(0); boost::mutex m; boost::detail::spinlock sp; void thread_click() { for (int i = 0; i < 10000000; ++i) { ++total; } } void mutex_click() { for (int i = 0; i < 10000000 ; ++i) { m.lock(); ++total; m.unlock(); } } void atomic_click() { for (int i = 0; i < 10000000; ++i) { ++total2; } } void spinlock_click() { for (int i = 0; i < 10000000; ++i) { boost::lock_guard<boost::detail::spinlock> lock(sp); ++total; } } int _tmain(int argc, _TCHAR* argv[]) { int thnum = 100; clock_t start = clock(); boost::thread_group threads; for (int i = 0; i < thnum;++i) { threads.create_thread(mutex_click); } threads.join_all(); //計時結束 clock_t end = clock(); std::cout << "多執行緒mutex結果:" << total << std::endl; std::cout << "多執行緒mutex耗時:" << end - start << std::endl; total = 0; start = clock(); for (int i = 0; i < thnum; ++i) { threads.create_thread(thread_click); } threads.join_all(); end = clock(); std::cout << "多執行緒無鎖結果:" << total << std::endl; std::cout << "多執行緒無鎖耗時:" << end - start << std::endl; total = 0; start = clock(); for (int i = 0; i < thnum; ++i) { threads.create_thread(atomic_click); } threads.join_all(); end = clock(); std::cout << "多執行緒atomic結果:" << total2 << std::endl; std::cout << "多執行緒atomic耗時:" << end - start << std::endl; total = 0; start = clock(); for (int i = 0; i < 10000000*thnum;i++) { ++total; } end = clock(); std::cout << "單執行緒結果:" << total << std::endl; std::cout << "單執行緒耗時:" << end - start << std::endl; total = 0; start = clock(); for (int i = 0; i < thnum; ++i) { threads.create_thread(spinlock_click); } threads.join_all(); end = clock(); std::cout << "自旋鎖結果:" << total << std::endl; std::cout << "自旋鎖耗時:" << end - start << std::endl; getchar(); return 0; }
上圖