
第二章 ZAB協議介紹
ZAB ( ZooKeeper Atomic Broadcast , ZooKeeper 原子訊息廣播協議)是zookeeper資料一致性的核心演算法。
ZAB 協議並不像 Paxos 演算法那樣,是一種通用的分散式一致性演算法,它是一種特別為 ZooKeeper 設計的崩潰可恢復的原子訊息廣播演算法。
ZAB協議主要實現了:
1.使用一個單一的主程序來接收並處理客戶端的所有事務請求,並採用 ZAB 的原子廣播協議,將伺服器資料的狀態變更以事務 Proposal 的形式廣播到所有的副本程序上去。
2.保證一個全域性的變更序列被順序應用。
ZooKeeper是一個樹形結構,很多操作都要先檢查才能確定能不能執行,比如P1的事務t1可能是建立節點“/a”,t2可能是建立節點“/a/aa”,只有先建立了父節點“/a”,才能建立子節點“/a/aa”。為了保證這一點,ZAB要保證同一個leader的發起的事務要按順序被apply,同時還要保證只有先前的leader的所有事務都被apply之後,新選的leader才能在發起事務。
3.當前主程序出現異常情況的時候,依舊能夠正常工作。
ZAB 協議的核心:定義了事務請求的處理方式。
所有事務請求必須由一個全域性唯一的伺服器來協調處理,這樣的伺服器被稱為 Leader伺服器,而餘下的其他伺服器則成為 Follower 伺服器。 Leader 伺服器負責將一個客戶端事務請求轉換成一個事務proposal(提議),並將該 Proposal分發給叢集中所有的Follower伺服器。之後 Leader 伺服器需要等待所有Follower 伺服器的反饋,一旦超過半數的Follower伺服器進行了正確的反饋後,那麼 Leader 就會再次向所有的 Follower伺服器分發Commit訊息,要求其將前一個proposal進行提交。
這種事務處理方式與2PC(兩階段提交協議)區別在於,兩階段提交協議的第二階段中,需要等到所有參與者的"YES"回覆才會提交事務,只要有一個參與者反饋為"NO"或者超時無反饋,都需要中斷和回滾事務。
ZAB協議介紹:
ZAB 協議包括兩種基本的模式,分別是崩潰恢復和訊息廣播。
當整個服務框架在啟動過程中,或是當 Leader 伺服器出現網路中斷、崩潰退出與重啟等異常情況時, ZAB 協議就會進入恢復模式並選舉產生新的 Leader 伺服器。當選舉產生了新的Leader 伺服器同時叢集中已經有過半的機器與該 Leader 伺服器完成了狀態同步之後,ZAB 協議就會退出恢復模式。
當叢集中已經有過半的 Follower 伺服器完成了和 Leader 伺服器的狀態同步,那麼整個服務框架就可以進入訊息廣播模式了。當一臺同樣遵守 ZAB 協議的伺服器啟動後加入到叢集中時,如果此時叢集中已經存在一個 Leader 伺服器在負責進行訊息廣播 , 那麼新加人的伺服器就會自覺地進人資料恢復模式:找到 Leader 所在的伺服器,並與其進行資料同步,然後一起參與到訊息廣播流程中去。
下面重點講解崩潰回覆和訊息廣播的過程。
訊息廣播
ZAB 協議的訊息廣播過程使用的是一個原子廣播協議,類似於一個二階段提交過程。針對客戶端的事務請求, Leader 伺服器會為其生成對應的事務 Proposal ,並將其傳送給叢集中其餘所有的機器,然後再分別收集各自的選票,最後進行事務提交。
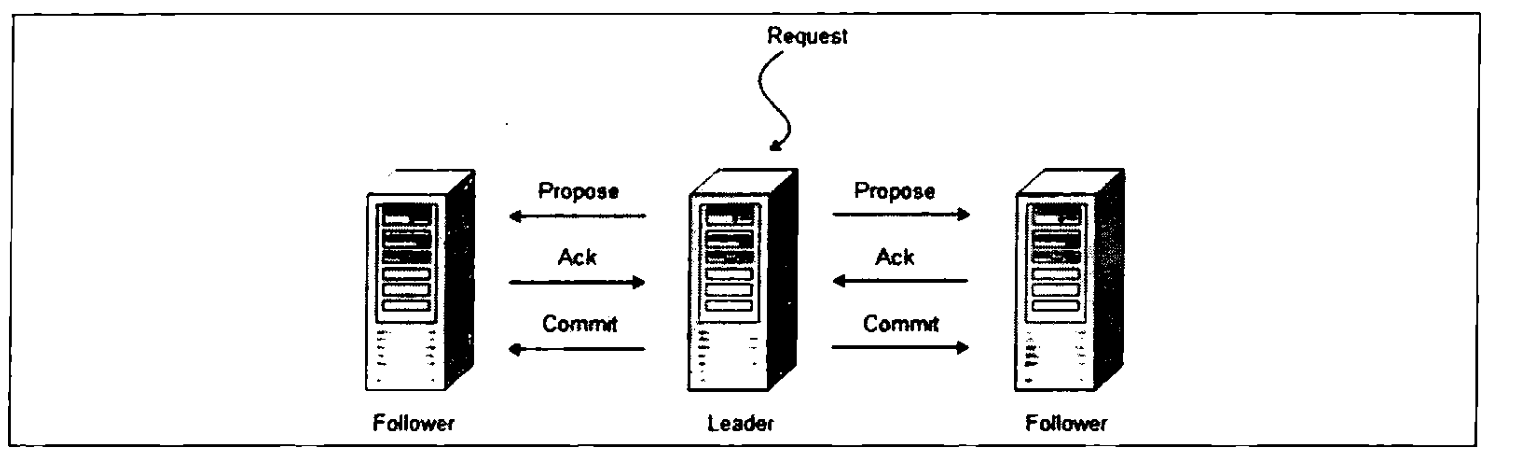
在 ZAB 協議的二階段提交過程中,移除了中斷邏輯,所有的 Follower 伺服器要麼正常反饋 Leader 提出的事務 Proposal ,要麼就拋棄Leader 伺服器。同時, ZAB 協議將二階段提交中的中斷邏輯移除意味著我們可以在過半的 Follower 伺服器已經反饋 Ack 之後就開始提交事務 Proposal 了,而不需要等待叢集中所有的 Follower 伺服器都反饋響應。這種簡化了的二階段提交模型無法處理 Leader 伺服器崩潰退出而帶來的資料不一致問題,此時採用崩潰恢復模式來解決這個問題。
在整個訊息廣播過程中, Leader 伺服器會為每個事務請求生成對應的 Proposal來進行廣播,並且在廣播事務 Proposal 之前, Leader 伺服器會首先為這個事務 Proposal 分配一個全域性單調遞增的唯一事務ID (即 ZXID )。
Leader 伺服器會為每一個 Follower 伺服器都各自分配一個單獨的佇列,然後將需要廣播的事務 Proposal 依次放入這些佇列中去,並且根據 FIFO策略進行訊息傳送。每一個 Follower 伺服器在接收到這個事務 Proposal 之後,都會首先將其以事務日誌的形式寫入到本地磁碟中去,並且在成功寫入後反饋給 Leader 伺服器一個 Ack 響應。當 Leader 伺服器接收到超過半數 Follower 的 Ack 響應後,就會廣播一個Commit 訊息給所有的 Follower 伺服器以通知其進行事務提交,同時 Leader 自身也會完成對事務的提交。
崩潰恢復
Leader 伺服器出現崩潰,或者說由於網路原因導致 Leader 伺服器失去了與過半 Follower 的聯絡,那麼就會進入崩潰恢復模式。Leader 選舉演算法不僅僅需要讓 Leader自己知道其自身已經被選舉為 Leader ,同時還需要讓叢集中的所有其他機器也能夠快速地感知到選舉產生的新的 Leader 伺服器。
ZAB 協議規定了如果一個事務 Proposal 在一臺機器上被處理成功,那麼應該在所有的機器上都被處理成功,哪怕機器出現故障崩潰。
下面介紹兩種崩潰恢復中的場景和zab協議需要保證的特性:
1.ZAB 協議需要確保那些已經在 Leader 伺服器上提交的事務最終被所有伺服器都提交
假設一個事務在 Leader 伺服器上被提交了,並且已經得到過半 Follower 伺服器的Ack 反饋,但是在它將 Commit 訊息傳送給所有 Follower 機器之前, Leader 伺服器掛了,針對這種情況, ZAB 協議就需要確保該事務最終能夠在所有的伺服器上都被提交成功,否則將出現不一致。
2.ZAB協議需要確保丟棄那些只在 Leader 伺服器上被提出的事務
假設初始的 Leader 伺服器 在提出了一個事務之後就崩潰退出了,導致叢集中的其他伺服器都沒有收到這個事務,當該伺服器恢復過來再次加入到叢集中的時候 ,ZAB協議需要確保丟棄這個事務。
針對以上兩點需求,zab協議需要設計的選舉演算法應該滿足:確保提交已經被 Leader 提交的事務 Proposal,同時丟棄已經被跳過的事務 Proposal 。
如果讓 Leader 選舉演算法能夠保證新選舉出來的 Leader 伺服器擁有叢集中所有機器最高編號(即 ZXID 最大)的事務 Proposal,那麼就可以保證這個新選舉出來的 Leader —定具有所有已經提交的提案。同時,如果讓具有最高編號事務 Proposal 的機器來成為 Leader, 就可以省去 Leader 伺服器檢查 Proposal 的提交和丟棄工作的這一步操作。
資料同步
Leader 伺服器會為每一個 Follower 伺服器都準備一個佇列,並將那些沒有被各 Follower 伺服器同步的事務以 Proposal 訊息的形式逐個傳送給 Follower 伺服器,並在每一個 Proposal 訊息後面緊接著再發送一個 Commit 訊息,以表示該事務已經被提交。等到 Follower 伺服器將所有其尚未同步的事務 Proposal 都從 Leader 伺服器上同步過來併成功應用到本地資料庫中後, Leader 伺服器就會將該 Follower 伺服器加入到真正的可用 Follower 列表中,並開始之後的其他流程。
下面來看 ZAB 協議是如何處理那些需要被丟棄的事務 Proposal 的。在 ZAB 協議的事務編號 ZXID 設計中, ZXID 是一個 64 位的數字,低 32 位可以看作是一個簡單的單調遞增的計數器,針對客戶端的每一個事務請求, Leader 伺服器在產生一個新的事務 Proposal 的時候,都會對該計數器進行加1操作;高 32 位代表了 Leader 週期 epoch 的編號,每當選舉產生一個新的 Leader 伺服器,就會從這個 Leader 伺服器上取出其本地日誌中最大事務 Proposal 的 ZXID ,並從該 ZXID 中解析出對應的 epoch 值,然後再對其進行加1操作,之後就會以此編號作為新的 epoch, 並將低 32 位置0來開始生成新的 ZXID 。
基於這樣的策略,當一個包含了上一個 Leader 週期中尚未提交過的事務 Proposal的伺服器啟動加入到叢集中,發現此時叢集中已經存在leader,將自身以Follower 角色連線上 Leader 伺服器之後, Leader 伺服器會根據自己伺服器上最後被提交的 Proposal來和 Follower 伺服器的 Proposal進行比對,發現follower中有上一個leader週期的事務Proposal時,Leader 會要求 Follower 進行一個回退操作——回退到一個確實已經被叢集中過半機器提交的最新的事務 Proposal 。