
Expert 診斷優化系列-------------針對重點語句調索引
上一篇我們說了索引的重要性,一個索引不僅能讓一條語句起飛,也能大量減少系統對CPU、記憶體、磁碟的依賴。我想上一篇中的例子可以說明了。給出上一篇和目錄文連結:
書接前文,我們知道了索引的重要,也知道了索引怎麼加,那麼我們應該往那些語句加?語句一條一條漫無目的的優化麼?我怎麼找出系統的問題語句?怎麼樣的一個優先順序?
很多對資料庫瞭解不是很多的人,也許一片茫然!還真不知道,那麼多儲存過程,那麼多程式語句,我總不能都看一遍吧?
對資料庫有些瞭解的人可能會知道用profiler,系統檢視等,這是個不錯的方式!
但是個人覺得這些不夠直觀,還是不能抓住重點,如果業務多變也會消耗大量時間。
所謂工欲善其事,必先利其器!那麼本篇我利用
首先還是上座駕:

--------------部落格地址---------------------------------------------------------------------------------------
廢話不多說,直接開整-----------------------------------------------------------------------------------------
本文選用的例子為一個伺服器高配,跑了一個小業務,硬體資源充足,但是語句執行很慢!(32CPU,32G記憶體跑了個只有10G 資料檔案的庫)
下面簡單的一個展示:

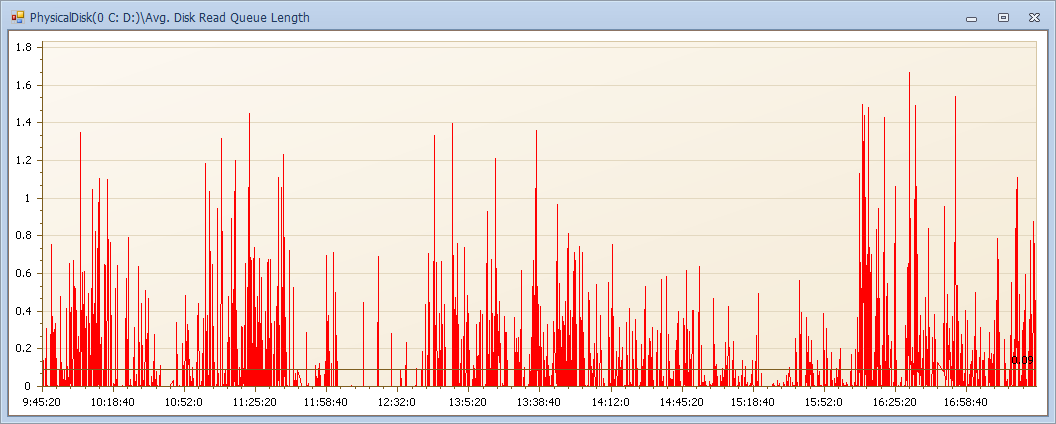

效能計數器指標請參見前文,本例中磁碟佇列全天小於2,記憶體充足,CPU使用60%略有壓力(主要是缺失索引導致)
下面看一下總體的語句執行情況:

語句可以看出超過1-3秒的語句有近8W次,3-5秒 5-10秒均接近2W,10秒以上的也有1W+,可見充足的資源配置下系統語句仍然很慢!
-
語句優先順序
前面很多文章中都已經介紹過了,優化一定要針對重點語句
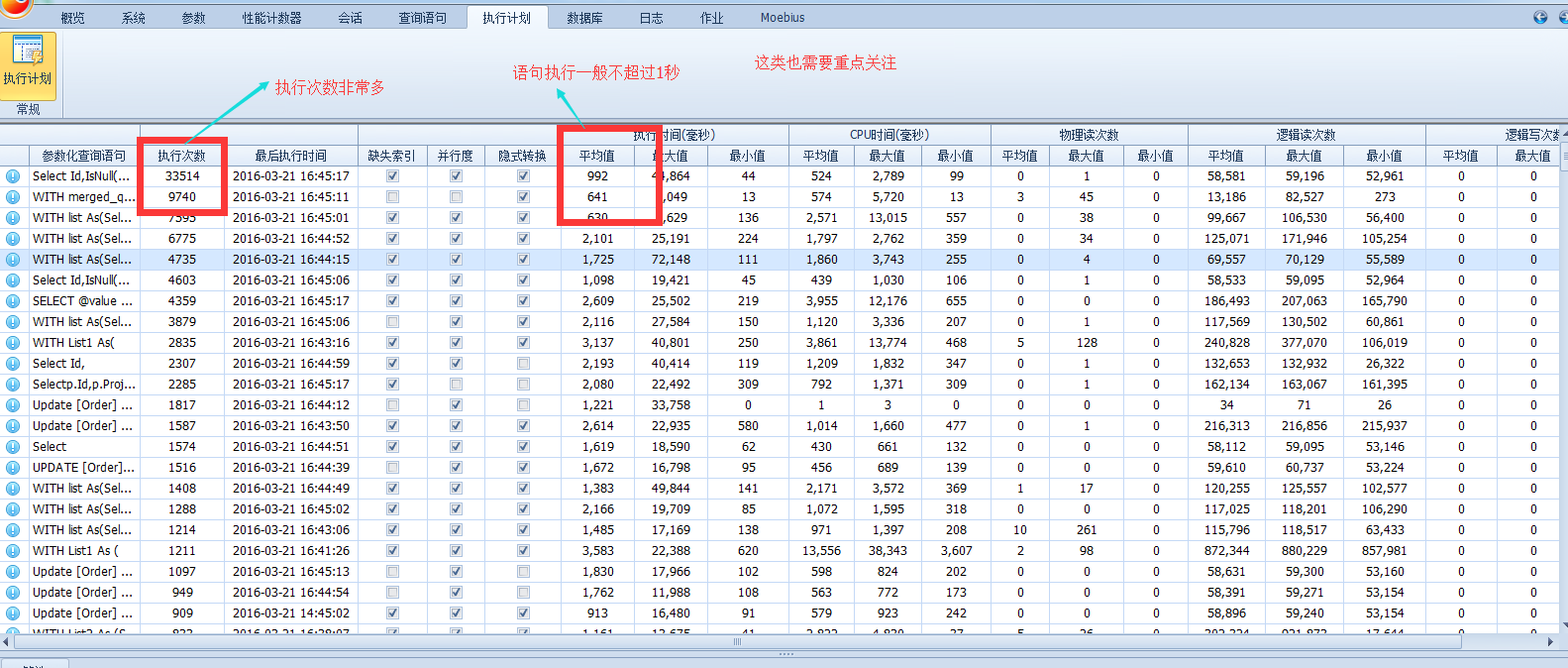
直接上圖!

圖中按照語句的執行次數排序,這也強烈符合我的優化套路,可以看出系統中執行頻率最高的語句,平均執行時間都在3秒左右甚至更長,邏輯讀都很高,但是影響的行數很少。這就是典型的缺少索引的情況!
高能提示: 看到這樣的一個統計介面,你是否知道如何下手了?怎麼樣的一個優先順序? 沒錯次數從高往低,來吧!開整!
根據個人習慣也可以按照邏輯讀/寫,cpu消耗等排出優先順序。
-
針對語句調索引
拿到了重點語句,那麼我們就從重點語句下手詳細分析一下。上一篇已經介紹了簡單粗暴的新增索引,簡單粗暴大概能應對80%的場景了,但是也要有一些注意!下面新手看官們要認真體會了!


我們看到了缺失索引的提示,這就和前文介紹執行計劃的大綠字是一個個東西。這裡不再詳細介紹。那麼拿到這個索引缺失我們就直接建立麼?前文中告訴你們的答案是直接建立!新的文章中當然要學點新東西!建立前請先核實一下索引!何為核實一下呢? 首先我們看一下執行計劃!由於執行計劃比較大隻貼出消主要耗部分~


執行計劃看出,缺失語句主要消耗在兩部分,都是這個customer表,index scan 說明有相關欄位的索引,但是不是最優的!那麼提示的索引算是正確(欄位驗證這裡就忽略了),那麼現在可以建立了? 還需要再核查幾個地方!
要建立索引的表有多少資料?

表上有150W+資料 確實適合建立索引!
是否有這個類似索引?
那麼表上現在有什麼索引呢?是新建立還是修改原有索引呢?

一堆索引...一屏沒截下....但是你會發現一個覆蓋索引都沒有?也沒有針對這條語句的最優索引! 也許這個系統的維護人員知道索引的重要性,但是不知道怎麼建立一個最優的索引,HOHO 讓他看看上篇文章就好了!
那麼這回可以直接建立提示索引就OK了吧? 答案是大寫的“NO”! 還需要你的細心!
建立的索引是否能使用?
前面 SQL SERVER全面優化-------寫出好語句是習慣 已經提到過,where條件的欄位中不能使用函式,不能有隱式轉換,也不能用 like “%XXXX%” 這樣就不能用索引查詢seek了! 我們要看一下是否是提示的索引不能使用!
如果你仔細的看了前文,你會反問:不能用不是就不提示了麼? 哈哈,真是認真,確實是這樣!這裡只是個需要細心的溫馨提示!
但是每一篇文章重要更深入一下麼,對吧! 前面看到原計劃中customer表使用了index scan ,細心的看官們會發現還有個key lookup,index scan + key lookup 你不覺得奇怪麼?

我們看一下具體的語句:語句太長,只貼where 部分了

我們可以看到customername 確實使用了 like ”%%“ 無法使用seek,但是companyid 和createdate 可以使用索引呀~所以我們再看一下 提示出的索引:
CREATE NONCLUSTERED INDEX [EFS_IX_Customer_b87864c46d0f4d3ca4ad4e4db8232063] ON [dbo].[Customer] ([CompanyId],[CreateDate]) INCLUDE ([Id],[CustomerId],[CustomerName],[Project],[IndustryOneId],[IndustryTwoId],[SourceId],[StateId],[TypeId],[ProtectId],[Audit],[delFlag]) GO
還是比較智慧吧~這回你可以建立這個索引了!
還得囉嗦一句:覆蓋索引雖好,但建立要注意,不要把過多的列放在索引裡。個人建議索引的篩選列+包含列不要超過表字段的1/3 ,純屬個人建議不是那麼絕對。
文章至此已經在上一篇的基礎上又做了一些細節的說明。看官們可以按照優先順序動手了。
-
大面積建立缺失索引
如果系統完全沒有過保養,表上基本沒有建立過什麼索引,那麼上面的建立方式一樣很傷體力,這裡還有一種簡單粗暴的方式for you!

大批量建立索引切記不要看到就建立,一定是影響、開銷、次數都很高的,並且要優化合並生成的指令碼,也就是上一篇提到的精簡索引!
-
根據執行計劃建立
這種方式和根據語句建立有異曲同工之妙,但不同的是一般的收集工具只收集1秒以上的語句。預設超過1秒才算慢,但是系統中有些語句執行不到一秒,但非常高頻,這也是需要關注的一大類! 限於篇幅這裡就不展開說了!
--------------部落格地址---------------------------------------------------------------------------------------
-----------------------------------------------------------------------------------------------------
總結 : 往往一個系統的整體緩慢都是因為索引問題導致的,優化索引是對你係統最簡單的保養!
不要小看一條語句的威力,一條語句足可以讓你的系統徹底無法工作!
相反優化一條重要的高頻語句就可以讓你的系統變的流暢!
優化索引要有自己的方法,不能逮到一條做一條,效率又差又可能抓不住重點。
每個人優化都有自己的一套方法,只有是夠系統,夠全面就可以。本文只是簡單介紹自己的優化方式,不喜勿噴~
相關文章連結 :
----------------------------------------------------------------------------------------------------
注:此文章為原創,歡迎轉載,請在文章頁面明顯位置給出此文連結!
若您覺得這篇文章還不錯請點選下右下角的推薦,非常感謝!
引用高大俠的一句話 :“拒絕SQL Server背鍋,從我做起!”
為了方便閱讀給出系列文章的導讀連結: