
大駝峰命名法和小駝峰命名法
前言
我們在做專案的時候,命名格式必須統一,這樣才會方便不同人之間的編碼閱讀!,所以今天就來說一下駝峰命名法!
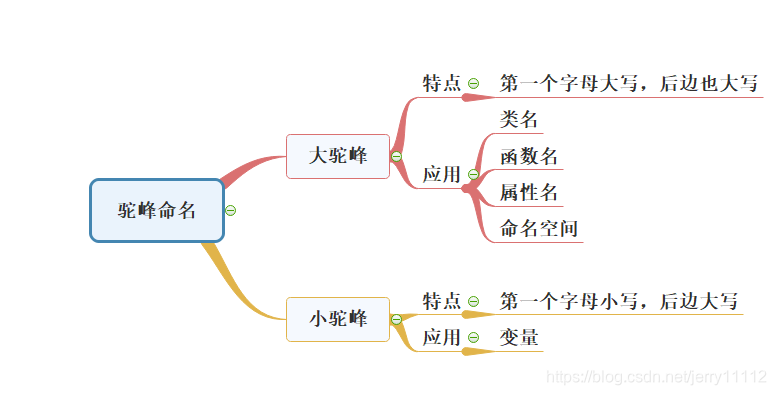
駱峰式命名法(Camel-Case)是電腦程式編寫時的一套命名規則(慣例)。
駱峰式命名法就是當變數名或函式名是由一個或多個單字連結在一起,而構成的唯一識別字時,第一個單詞以小寫字母開始;第二個單詞的首字母大寫或每一個單詞的首字母都採用大寫字母!
小駝峰法
變數一般用小駝峰法標識。駝峰法的意思是:除第一個單詞之外,其他單詞首字母大寫。譬如int studentCount=0;
變數myStudentCount第一個單詞是全部小寫,後面的單詞首字母大寫。
大駝峰法
相比小駝峰法,大駝峰法把第一個單詞的首字母也大寫了。常用於類名,函式名,屬性,名稱空間。譬如public class StudentInfomation;
相關推薦
大駝峰命名法和小駝峰命名法的區別
天才 理解 color 小寫 一個 駝峰命名 nbsp round 大寫 之前一直知道有駝峰命名法,今天才知道駝峰命名法還分大駝峰和小駝峰,現將二者區別說一下: 1.大駝峰,每一個單詞的首字母都大寫,例如:AnamialZoo,JavaScript
大駝峰命名法和小駝峰命名法
前言 我們在做專案的時候,命名格式必須統一,這樣才會方便不同人之間的編碼閱讀!,所以今天就來說一下駝峰命名法! 駱峰式命名法(Camel-Case)是電腦程式編寫時的一套命名規則(慣例)。 駱峰式命名法就是當變數名或函式名是由一個或多個單字連結在一起,而構成的唯一識別字時
Id class 變量 的賦值規範 大駝峰和小駝峰 代碼的格式和註釋的類型
id classde 變量 的賦值規範 大駝峰和小駝峰 代碼的格式和註釋的類型Id classde 變量 的賦值規範 大駝峰和小駝峰 代碼的格式和註釋的類型 其實我認為這是非常重要的,只要是個開發人員都會寫代碼,但是做到這些的卻不容易,現在公司看中的是合作能力、溝通能力、和編碼風格,這也是開發人員
Call調用webservice接口,使用命名空間和不使用命名空間的區別
.cn 測試 inf targe abs 註釋 命名空間 all 方式 生活中我們會遇到許許多多的奇葩問題,而這些問題又是我們不得不解決的。 我先用一段代碼來引出我想要說的內容: import javax.jws.WebMethod; import javax.j
梯度下降法和隨機梯度下降法和小批量梯度對比
對於梯度下降法 如果訓練樣本集特別大(假設為樣本3億:表示在美國大學3億人口,因此美國的人口普查擁有這樣數量級的資料),如果想用這些資料去擬合一個線性迴歸模型,那麼需要對著3億資料進行求和,計算量太大了,這種梯度下降也被稱為批量地圖下降法,(批量:表示每次我們都要同事考慮所有訓練樣本,我們
c語言語系的命名風格和java繫命名風格
c語言系的命名風格:單詞之間使用下劃線分隔。如上圖。 java語言是另外一個系,javascript屬於java語系(當年就是想借助java的名氣所以命名javascript)。java語系是駝峰式命名法,如getElementById()。如果使用c語系命名風格則使用下劃線分隔 get_e
隨機梯度下降法,批量梯度下降法和小批量梯度下降法以及程式碼實現
前言 梯度下降法是深度學習領域用於最優化的常見方法,根據使用的batch大小,可分為隨機梯度下降法(SGD)和批量梯度下降法(BGD)和小批量梯度下降法(MBGD),這裡簡單介紹下並且提供Python程式碼演示。 如有謬誤,請聯絡指正。轉載請註明出處。 聯
演算法導論第三版第六章 合併K個有序連結串列的三種解法(最小堆法和分治遞迴法)
題目要求是將k個有序連結串列合併為一個連結串列,時間複雜度限定為O(nlogk)。下面給出應用最小堆方法的兩個程式,最後再貼上利用分治遞迴法的程式碼,雖然時間複雜度不及堆方法,但思路相對簡單好理解。 (1)最小堆方法1 用一個大小為K的最小堆(用優先佇列+自定義降序實現)(
爬山算法和模擬退火算法簡介
出了 搜索算法 旅行 www cnblogs 所有 發的 圖1 貪心 轉自:http://www.cnblogs.com/chaosimple/archive/2013/06/10/3130664.html 一. 爬山算法 ( Hill Climbing )
排序算法和查找算法
算法 排序 冒泡 插入 選擇 示例:分別用冒泡排序,快速排序,選擇排序,插入排序將數組中的值從小到大的順序排序$array = (9,5,1,3,6,4,8,7,2);1、冒泡排序算法//思路:兩兩比較待排序數據元素的大小,發現兩個數據元素的次序相反即進行交換,直到沒有反序的數據元素為止
PHP數組基本排序算法和查找算法
emp 文章 大於 temp 嚴格 每次 找到 個人 數組 關於PHP中的基礎算法,小結一下,也算是本博客的第一篇文章1.2種排序算法冒泡排序:例子:個人見解 5 6 2 3 7 9 第一趟 5 6 2 3 7 9 5 2 6 3 7 9 5 2 3 6 7
清除浮動的四種方法:額外標簽法,overflow:hidden,單偽元素法和雙偽元素法
new ont nbsp ola 圖片 分享 col ons pac 當給浮動的元素增加了一個父級元素,但是又不方便給高度的情況下 (父盒子給高度也是一個解決方法,但是大多數情況下,因為盒子的內容會經常改變,父盒子高度固定,需要每次去調整) 此時可以使用下面的四種方法來清
Python算法教程第三章知識點:求和式、遞歸式、侏儒排序法和並歸排序法
code pen nom eve end sort urn 使用 微信公眾號 本文目錄:一、求和式;二、遞歸式;三、侏儒排序法和並歸排序法微信公眾號:geekkr</br></br></br> 一、求和式 # 假設有一函數為f(),則在P
埃氏篩法和尤拉篩法的區別
Eratosthenes篩法(Sieve of Eratosthenes) 由於思想非常簡單,故只給出實現。 void eratosthenes_sieve(int n) { totPrimes = 0; memset(flag, 0, size
鏈地址法和開放定址法,求等概率下查詢成功時的平均查詢長度
問題描述: 演算法與資料結構的一個題目,用鏈地址法和開放定址法,求等概率情況下查詢成功時的平均查詢長度 已知一組關鍵字(13,20,85,52,8),雜湊函式為:H(key)=key MOD 6
方程求根(二分法和牛頓迭代法)
一、實驗內容 以方程:x3-0.2x2-0.2x-1.2=0為例,編寫程式求方程的根 編寫二分法、迭代法、牛頓法程式,分析執行結果 二、程式碼(python) import matplotlib.pyplot as plt #計算原函式值 de
求素數個數(埃氏篩法和尤拉篩法)
求1——n的素數的個數,有以下三種方法: 普通的O()演算法: #include<iostream> #include<cstdio> #include<cmath> using namespace std; bool isprim
梯度下降法和最速下降法的細微差別
1. 前言: 細微之處,彰顯本質;不求甚解,難以理解。 一直以來,我都認為,梯度下降法就是最速下降法,反之亦然,老師是這麼叫的,百度百科上是這麼寫的,wiki百科也是這麼說的,這麼說,必然會導致大家認為,梯度的反方向就是下降最快的方向,然而最近在讀Steph
無符號數和有符號數(一) -- 原碼錶示法和補碼錶示法
無符號數: 即沒有符號的數。 在c語言中就是 unsigned 型別的。 無符號數在計算機中的儲存較為簡單, 因為沒有符號位, 直接將數字化成二進位制然後儲存在對應的儲存器或者暫存器中。 這時暫存器或
[資料結構]散列表-連結法和開放定址法 線性探查
在介紹hash表之前首先提到直接定址表 但是由於實際上儲存在字典裡的關鍵字集合K比實際上所有可能的關鍵字的全域U要小的多,因此散列表所需要的儲存空間比直接定址表要小的多 通過雜湊函式 h:U -> {0,1,2…m-1} 其中m 遠小於|U| 但是對於h