
Forward-Backward演算法做HMM的Inference
阿新 • • 發佈:2018-12-30
馬爾可夫鏈的三個基本問題
1.已知一個序列,他的likelihood是什麼樣的。(使用前向演算法)
2.求解一個最好的狀態鏈(Viterbi演算法)
3.優化或者重新估計這個HMM,比如重新估計發散矩陣和轉換矩陣(Baum-Welch演算法)
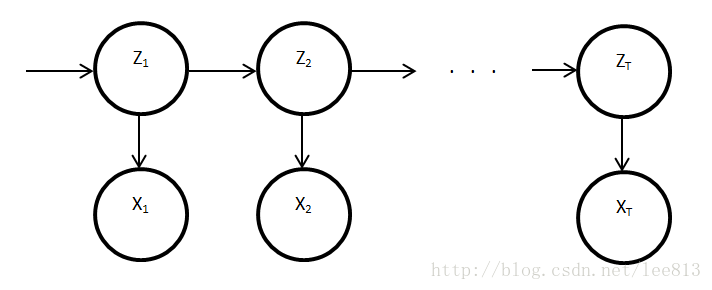
F/B演算法是一個求解HMM的重要演算法,它是動態規劃(Dynamic programming, 這個名字的翻譯有點意思)的重要一種。
F/B前提:假設發散概率矩陣(Emission Probablity Matrix), 轉換矩陣(Transition Probabilty Matrix) , 和初始概率(Initial probability)已知。
F/B目的:求在已知的觀測資料X下的某個狀態Z的概率。
F/B為什麼要分成兩部分:前向演算法(Forward)和後向演算法(Backward)
首先來看我們要求的概率
在觀測資料X固定的情況下,
根據Chain Rule,可以將
根據圖論的D-separation,我們可以將
那麼 (Zk|X)
(2)式中右邊的前半部分就是前向演算法,後半部分是後向演算法。
前向演算法(Forward)
前向演算法可以計算給定了觀測資料後,這些資料跟目前HMM的引數的相似程度。或者說來計算觀測資料在這些引數下的似然(likelihood)。前向演算法要求
m代表了狀態Z的數量,根據邊際概率,我們得到了這個式子。然後根據Chain rule:
使用D-separation
這個式子可以解釋成為對於每個
typedef struct
{
int N; /* 隱藏狀態數目;Q={1,2,…,N} */
int M; /* 觀察符號數目; V={1,2,…,M}*/
double **A; /* 狀態轉移矩陣A[1..N][1..N]. a[i][j] 是從t時刻狀態i到t+1時刻狀態j的轉移概率 */
double **B; /* 混淆矩陣B[1..N][1..M]. b[j][k]在狀態j時觀察到符合k的概率。*/
double *pi; /* 初始向量pi[1..N],pi[i] 是初始狀態概率分佈 */
} HMM;
前向演算法程式示例如下:
/*
函式引數說明:
*phmm:已知的HMM模型;T:觀察符號序列長度;
*O:觀察序列;**alpha:區域性概率(到目前狀態為止所有概率的和);*pprob:最終的觀察概率
*/
void Forward(HMM *phmm, int T, int *O, double **alpha, double *pprob)
{
int i, j; /* 狀態索引 */
int t; /* 時間索引 */
double sum; /*求區域性概率時的中間值 */
/* 1. 初始化:計算t=1時刻所有狀態的區域性概率: */
for (i = 1; i <= phmm->N; i++)
alpha[1][i] = phmm->pi[i]* phmm->B[i][O[1]];
/* 2. 歸納:遞迴計算每個時間點,t=2,… ,T時的區域性概率 */
for (t = 1; t < T; t++)
{
for (j = 1; j <= phmm->N; j++)
{
sum = 0.0;
for (i = 1; i <=