
Python+Selenium框架設計篇之5-框架內封裝基類和實現POM
阿新 • • 發佈:2018-12-30
前面文章,我們實現了框架的一部分功能,包括日誌類和瀏覽器引擎類的封裝,今天我們繼續封裝一個基類和介紹如何實現POM。關於基類,是這樣定義的:把一些常見的頁面操作的selenium封裝到base_page.py這個類檔案,以後每個POM中的頁面類,都繼承這個基類,這樣每個頁面類都有基類的方法,這個我們會在這篇文章實現。
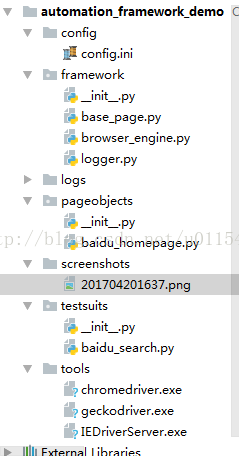
1. 在實現封裝基類裡,我們實現了元素八大方式的定位和截圖類封裝。具體專案層級結構如下圖。
2. 基類base_page.py的具體實現程式碼,這裡就封裝了幾個常用方法,其他方法,你自己去練習封裝下。
3. 頁面物件中,百度主頁的元素定位和簡單的操作函式,頁面類主要是元素定位和頁面操作寫成函式,供測試類呼叫。# coding=utf-8 import time from selenium.common.exceptions import NoSuchElementException import os.path from framework.logger import Logger # create a logger instance logger = Logger(logger="BasePage").getlog() class BasePage(object): """ 定義一個頁面基類,讓所有頁面都繼承這個類,封裝一些常用的頁面操作方法到這個類 """ def __init__(self, driver): self.driver = driver # quit browser and end testing def quit_browser(self): self.driver.quit() # 瀏覽器前進操作 def forward(self): self.driver.forward() logger.info("Click forward on current page.") # 瀏覽器後退操作 def back(self): self.driver.back() logger.info("Click back on current page.") # 隱式等待 def wait(self, seconds): self.driver.implicitly_wait(seconds) logger.info("wait for %d seconds." % seconds) # 點選關閉當前視窗 def close(self): try: self.driver.close() logger.info("Closing and quit the browser.") except NameError as e: logger.error("Failed to quit the browser with %s" % e) # 儲存圖片 def get_windows_img(self): """ 在這裡我們把file_path這個引數寫死,直接儲存到我們專案根目錄的一個資料夾.\Screenshots下 """ file_path = os.path.dirname(os.path.abspath('.')) + '/screenshots/' rq = time.strftime('%Y%m%d%H%M', time.localtime(time.time())) screen_name = file_path + rq + '.png' try: self.driver.get_screenshot_as_file(screen_name) logger.info("Had take screenshot and save to folder : /screenshots") except NameError as e: logger.error("Failed to take screenshot! %s" % e) self.get_windows_img() # 定位元素方法 def find_element(self, selector): """ 這個地方為什麼是根據=>來切割字串,請看頁面裡定位元素的方法 submit_btn = "id=>su" login_lnk = "xpath => //*[@id='u1']/a[7]" # 百度首頁登入連結定位 如果採用等號,結果很多xpath表示式中包含一個=,這樣會造成切割不準確,影響元素定位 :param selector: :return: element """ element = '' if '=>' not in selector: return self.driver.find_element_by_id(selector) selector_by = selector.split('=>')[0] selector_value = selector.split('=>')[1] if selector_by == "i" or selector_by == 'id': try: element = self.driver.find_element_by_id(selector_value) logger.info("Had find the element \' %s \' successful " "by %s via value: %s " % (element.text, selector_by, selector_value)) except NoSuchElementException as e: logger.error("NoSuchElementException: %s" % e) self.get_windows_img() # take screenshot elif selector_by == "n" or selector_by == 'name': element = self.driver.find_element_by_name(selector_value) elif selector_by == "c" or selector_by == 'class_name': element = self.driver.find_element_by_class_name(selector_value) elif selector_by == "l" or selector_by == 'link_text': element = self.driver.find_element_by_link_text(selector_value) elif selector_by == "p" or selector_by == 'partial_link_text': element = self.driver.find_element_by_partial_link_text(selector_value) elif selector_by == "t" or selector_by == 'tag_name': element = self.driver.find_element_by_tag_name(selector_value) elif selector_by == "x" or selector_by == 'xpath': try: element = self.driver.find_element_by_xpath(selector_value) logger.info("Had find the element \' %s \' successful " "by %s via value: %s " % (element.text, selector_by, selector_value)) except NoSuchElementException as e: logger.error("NoSuchElementException: %s" % e) self.get_windows_img() elif selector_by == "s" or selector_by == 'selector_selector': element = self.driver.find_element_by_css_selector(selector_value) else: raise NameError("Please enter a valid type of targeting elements.") return element # 輸入 def type(self, selector, text): el = self.find_element(selector) el.clear() try: el.send_keys(text) logger.info("Had type \' %s \' in inputBox" % text) except NameError as e: logger.error("Failed to type in input box with %s" % e) self.get_windows_img() # 清除文字框 def clear(self, selector): el = self.find_element(selector) try: el.clear() logger.info("Clear text in input box before typing.") except NameError as e: logger.error("Failed to clear in input box with %s" % e) self.get_windows_img() # 點選元素 def click(self, selector): el = self.find_element(selector) try: el.click() logger.info("The element \' %s \' was clicked." % el.text) except NameError as e: logger.error("Failed to click the element with %s" % e) # 或者網頁標題 def get_page_title(self): logger.info("Current page title is %s" % self.driver.title) return self.driver.title @staticmethod def sleep(seconds): time.sleep(seconds) logger.info("Sleep for %d seconds" % seconds)
baidu_homepage.py
這裡注意下元素定位寫法,=>和base_page.py中find_element()方法元素定位切割有關係,網上有些人寫根據逗號切割或者等號切割,在實際使用xpath定位,發現單獨逗號或者單獨等號切割都不精確,造成元素定位失敗。# coding=utf-8 from framework.base_page import BasePage class HomePage(BasePage): input_box = "id=>kw" search_submit_btn = "xpath=>//*[@id='su']" def type_search(self, text): self.type(self.input_box, text) def send_submit_btn(self): self.click(self.search_submit_btn)
4. 測試類的寫法舉例
# coding=utf-8 import time import unittest from framework.browser_engine import BrowserEngine from pageobjects.baidu_homepage import HomePage class BaiduSearch(unittest.TestCase): def setUp(self): """ 測試韌體的setUp()的程式碼,主要是測試的前提準備工作 :return: """ browse = BrowserEngine(self) self.driver = browse.open_browser(self) def tearDown(self): """ 測試結束後的操作,這裡基本上都是關閉瀏覽器 :return: """ self.driver.quit() def test_baidu_search(self): """ 這裡一定要test開頭,把測試邏輯程式碼封裝到一個test開頭的方法裡。 :return: """ homepage = HomePage(self.driver) homepage.type_search('selenium') # 呼叫頁面物件中的方法 homepage.send_submit_btn() #呼叫頁面物件類中的點選搜尋按鈕方法 time.sleep(2) homepage.get_windows_img() # 呼叫基類截圖方法 try: assert 'selenium' in homepage.get_page_title() # 呼叫頁面物件繼承基類中的獲取頁面標題方法 print ('Test Pass.') except Exception as e: print ('Test Fail.', format(e)) if __name__ == '__main__': unittest.main()
homepage = HomePage(self.driver)測試結果:會在logs資料夾生成一個日誌檔案,也會在screenshots資料夾生成一個png圖片。