
學習Linux-4.12核心網路協議棧(2.2)——介面層資料包的接收(上半部)
前面寫了這麼多,終於可以開始分析資料報的傳輸過程了,那我們就愉快的開始吧!
我們知道,一箇中斷處理函式主要分兩個部分,上半部和下半部,這篇文章主要介紹上半部分。
當一個數據包到達的時候,網絡卡驅動會完成接收並且觸發中斷,我們就從這個中斷處理函式開始:
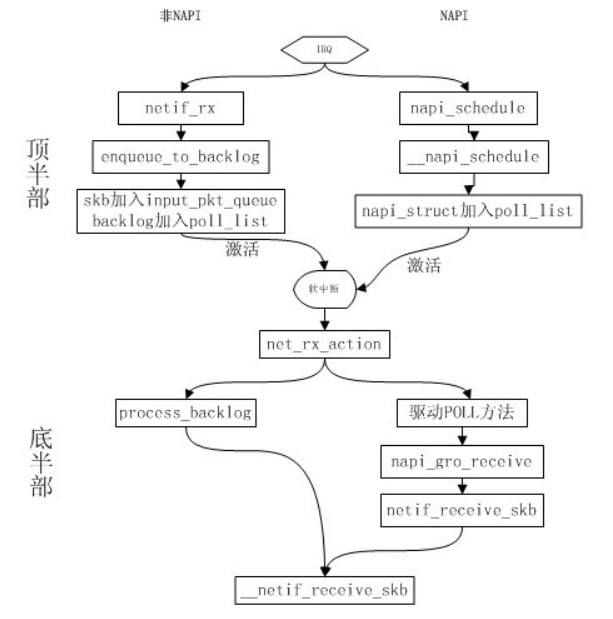
當一箇中斷產生併發送給CPU的時候,對於NAPI和不支援NAPI的裝置來說處理結果是不一樣的,NAPI呼叫的函式是napi_schedule,非NAPI呼叫的函式是netif_rx,這兩個函式都是在網絡卡驅動的中斷處理函式上半部分被呼叫的。
產生中斷的每個裝置都有一個相應的中斷處理程式,是裝置驅動程式的一部分。
每個網絡卡都有一箇中斷處理程式,用於通知網絡卡該中斷已經被接收了,以及把網絡卡緩衝區的資料包拷貝到記憶體中。當網絡卡接收來自網路的資料包時,需要通知核心資料包到了。網絡卡立即發出中斷:嗨,核心,我這裡有最新的資料包了。核心通過執行網絡卡已註冊的中斷處理函式來做出應答。
中斷處理程式開始執行,通知硬體,拷貝最新的網路資料包到記憶體,然後讀取網絡卡更多的資料包。
這些都是重要、緊迫而又與硬體相關的工作。核心通常需要快速的拷貝網路資料包到系統記憶體,因為網絡卡上接收網路資料包的快取大小固定,而且相比系統記憶體也要小得多。所以上述拷貝動作一旦被延遲,必然造成網絡卡快取溢位 - 進入的資料包占滿了網絡卡的快取,後續的包只能被丟棄。當網路資料包被拷貝到系統記憶體後,中斷的任務算是完成了,這時它把控制權交還給被系統中斷前執行的程式,處理和操作資料包的其他工作在隨後的下半部中進行。
我們現在知道了不管是否支援NAPI,對於驅動來說無非是呼叫napi_schedule或者netif_rx來通知核心,將資料包交給核心。所以如果不知道驅動使用的中斷處理程式是哪個,那麼只要搜尋一下這兩個函式就能定位出來了。下面我們來分析一下這兩個函式,因為NAPI是基於前者發展出來的,所以我們先了解netif_rx。一、非NAPI (netif_rx)
/** * netif_rx - post buffer to the network code * @skb: buffer to post * * This function receives a packet from a device driver and queues it for * the upper (protocol) levels to process. It always succeeds. The buffer * may be dropped during processing for congestion control or by the * protocol layers. * * return values: * NET_RX_SUCCESS (no congestion) * NET_RX_DROP (packet was dropped) * */ int netif_rx(struct sk_buff *skb) { trace_netif_rx_entry(skb); return netif_rx_internal(skb); }
static int netif_rx_internal(struct sk_buff *skb)
{
int ret;
net_timestamp_check(netdev_tstamp_prequeue, skb); //記錄接收時間到skb->tstamp
trace_netif_rx(skb);
#ifdef CONFIG_RPS
if (static_key_false(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu;
preempt_disable();
rcu_read_lock();
cpu = get_rps_cpu(skb->dev, skb, &rflow); //如果有支援rps,則獲取這個包交給了哪個cpu處理
if (cpu < 0)
cpu = smp_processor_id(); //如果上面獲取失敗,則用另外一種方式獲取當前cpu的id
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail); //呼叫該函式將包新增到queue->input_pkt_queue裡面
rcu_read_unlock();
preempt_enable();
} else
#endif
{
unsigned int qtail;
ret = enqueue_to_backlog(skb, get_cpu(), &qtail);
put_cpu();
}
return ret;
}
這個函式最後呼叫enqueue_to_backlog將包新增到queue->input_pkt_queue的尾部,這個input_pkt_queue是每個cpu都有的一個佇列,如果不夠清楚它的作用,可以看看前面一篇文章的截圖,這個佇列的初始化在net_dev_init()中完成:
8568 for_each_possible_cpu(i) {
8569 struct work_struct *flush = per_cpu_ptr(&flush_works, i);
8570 struct softnet_data *sd = &per_cpu(softnet_data, i);
8571
8572 INIT_WORK(flush, flush_backlog);
8573
8574 skb_queue_head_init(&sd->input_pkt_queue);
8575 skb_queue_head_init(&sd->process_queue);
8576 INIT_LIST_HEAD(&sd->poll_list);
8577 sd->output_queue_tailp = &sd->output_queue;
8578 #ifdef CONFIG_RPS
8579 sd->csd.func = rps_trigger_softirq;
8580 sd->csd.info = sd;
8581 sd->cpu = i;
8582 #endif
8583
8584 sd->backlog.poll = process_backlog;
8585 sd->backlog.weight = weight_p;
8586 }
...
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
現在我們來看看enqueue_to_backlog函式怎麼將包新增到queue->input_pkt_queue尾部的:
/*
* enqueue_to_backlog is called to queue an skb to a per CPU backlog
* queue (may be a remote CPU queue).
*/
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
struct softnet_data *sd;
unsigned long flags;
unsigned int qlen;
sd = &per_cpu(softnet_data, cpu); //獲取當前cpu的softnet_data物件
local_irq_save(flags); //儲存中斷狀態
rps_lock(sd);
if (!netif_running(skb->dev)) //確認net_device的dev->state是不是__LINK_STATE_START狀態,如果該網路裝置沒有執行,直接退出,不進行包的處理
goto drop;
qlen = skb_queue_len(&sd->input_pkt_queue); //獲取input_pkt_queue的當前長度
if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) { //如果當前長度小於最大長度,而且滿足流量限制的要求
if (qlen) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb); //關鍵在這裡,將SKB新增到input_pkt_queue佇列的後面
input_queue_tail_incr_save(sd, qtail); //佇列尾部指標加1
rps_unlock(sd);
local_irq_restore(flags); //恢復中斷狀態
return NET_RX_SUCCESS; //返回成功標識
}
/* Schedule NAPI for backlog device
* We can use non atomic operation since we own the queue lock
*/
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {
if (!rps_ipi_queued(sd))
____napi_schedule(sd, &sd->backlog); //把虛擬裝置backlog新增到sd->poll_list中以便進行輪詢,最後設定NET_RX_SOFTIRQ標誌觸發軟中斷
}
goto enqueue;
}
drop:
sd->dropped++; /* 如果接收佇列滿了就直接丟棄 */
rps_unlock(sd);
local_irq_restore(flags); /* 恢復本地中斷 */
atomic_long_inc(&skb->dev->rx_dropped);
kfree_skb(skb);
return NET_RX_DROP;
}
在非NAPI中,我們只要將skb新增到input_pkt_queue就可以了嗎?我們要看到最後,它將backlog新增到了sd->poll_list裡面,並且呼叫__napi_schedule()觸發軟中斷。我們還記得,在協議棧初始化的時候,net_dev_init()有初始化軟中斷:
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
所以接下來,軟中斷會執行net_rx_action 函式。這個部分我們放到下篇文章資料包接收的下半部裡面分析。
網路資料包在上半部的處理通常有兩種模式:傳統的netif_rx模式和NAPI(napi_schedule)模式,在這裡我們主要討論網路上半部的內容,無論上半部採用何種收包模式,都會呼叫__netif_rx_schedule()函式,netif_receive_skb函式會根據不同的協議呼叫不同的協議處理函式。
二、 NAPI(napi_schedule)
在分析NAPI前, 我們先來看看網絡卡驅動是怎麼呼叫NAPI的函式的:
2235 if (likely(napi_schedule_prep(&nic->napi))) { //設定state為NAPI_STATE_SCHED 2236 e100_disable_irq(nic); 2237 __napi_schedule(&nic->napi); //將裝置新增到 poll list,並開啟軟中斷。 2238 }
/**
* napi_schedule - schedule NAPI poll
* @n: NAPI context
*
* Schedule NAPI poll routine to be called if it is not already
* running.
*/
static inline void napi_schedule(struct napi_struct *n)
{
if (napi_schedule_prep(n)) //確定裝置處於執行,而且裝置還沒有被新增到網路層的POLL 處理佇列中
__napi_schedule(n);
}
/**
* __napi_schedule - schedule for receive
* @n: entry to schedule
*
* The entry's receive function will be scheduled to run.
* Consider using __napi_schedule_irqoff() if hard irqs are masked.
*/
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
local_irq_save(flags);
____napi_schedule(this_cpu_ptr(&softnet_data), n);
local_irq_restore(flags);
}
EXPORT_SYMBOL(__napi_schedule);
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list); //將裝置新增到poll佇列
__raise_softirq_irqoff(NET_RX_SOFTIRQ); //觸發軟中斷
}
到這裡可以看出,它間裝置新增到poll佇列以後觸發了軟中斷,我們還記得在net_dev_init()裡面我們註冊了軟中斷的處理函式 net_rx_action,所以後面文章我們分析軟中斷處理函式net_rx_action.
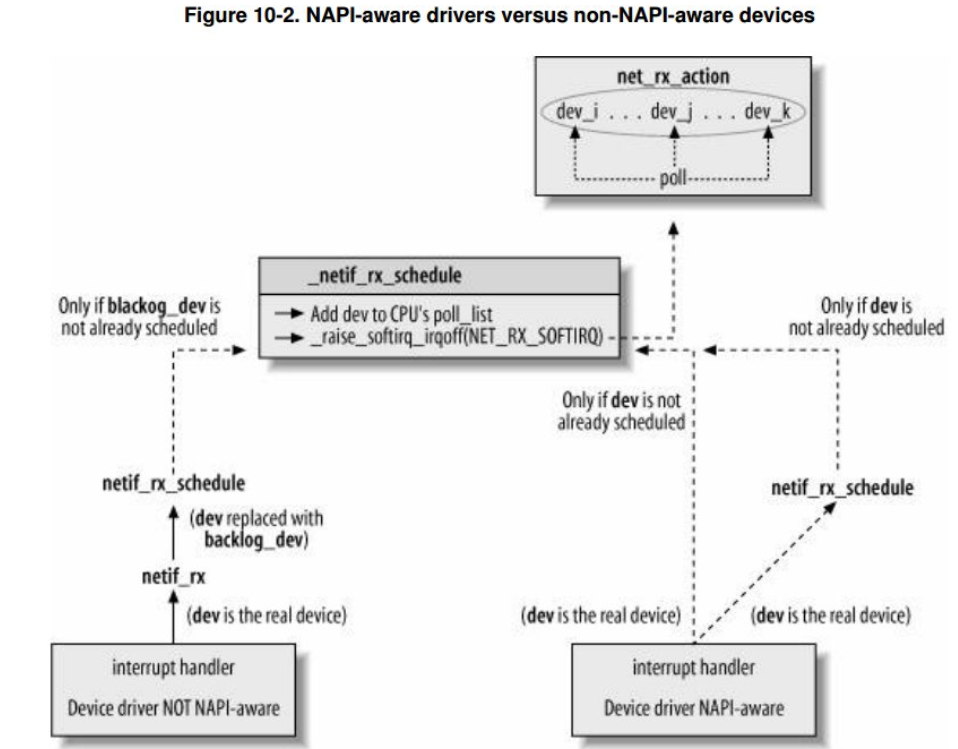
到這裡可以得出的結論是:無論是NAPI介面還是非NAPI最後都是使用 net_rx_action 作為軟中斷處理函式。也就是中斷的上半部分雖然有所不一樣,但是他們下半部分的入口的是由net_rx_action,我們下篇文章將從這個函式開始分析。