
MapReduce 應用:TF-IDF 分散式實現
概述
本文要說的 TF-IDF 分散式實現,運用了很多之前 MapReduce 的核心知識點。算是 MapReduce 的一個小應用吧。
版權說明
學前導讀
演算法框架
首先我們來看一下,分散式的 TF-IDF 的演算法框架圖:
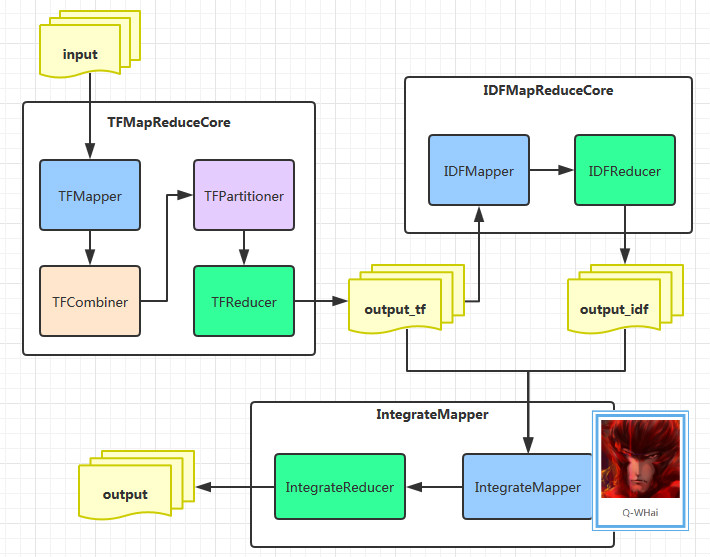
在圖中,我們有三個大模組,這三個大模組正是 MapReduce 中的三個 Job。
在學習 TF-IDF 的時候我們就知道了,TF-IDF 的計算可以分成三個部分進行。第一個階段:計算各個文件中每個單詞的 TF 值;第二階段:計算所有文件中所有單詞的 IDF 值;第三個階段:計算各個文件中各個單詞的 TF-IDF 值。在單機的環境下,很容易實現這些計算。可是,分散式環境下要怎麼做呢?於是,根據這三個階段,我設計了上面的架構圖。
TFMapReduceCore 類包含的是計算 TF 的核心類,IDFMapReduceCore 中則包含了 IDF 的核心類,IntegrateCore 中包含的是將 TF、IDF 的結果進行整合,從而計算最終的 TF-IDF 結果。且這裡還產生了兩個中間輸出目錄,而這兩個中間輸出目錄也正是第三個階段的輸入目錄,這一步中,需要用到 MapReduce 的多路徑輸入。上面也有專門的文章描述了這一塊。
程式碼實現
TFMapReduceCore
這裡我將與計算 TF 相關的程式碼封裝在同一個 TFMapReduceCore 類中,其中的 TFMapper, TFReducer 等都是 TFMapReduceCore 類的一個子類。
TFMapper
public static class TFMapper extends Mapper<Object, Text, Text, Text> {
private final Text one = new Text("1");
private Text label = new Text();
private 因為我們輸入的原始檔是用一個檔案表示一個分類,如果你是以其他規則劃分,那麼可以不必遵從本文的邏輯。上面我首先在 setup() 裡獲取檔名,這樣做的目的在於不用在 map() 中重複獲取,從而提升程式的效率。並且在 cleanup() 裡把檔名(也就是分類)資訊寫入到 Mapper 的輸出路徑中。
大家可能注意到了這裡我寫入檔名的時候,使用了一個技巧,使用“!”充當了一個單詞。因為這個字元的 ASCII 碼比所有的字元的 ASCII 碼都要小,這樣做的目的是可以讓這條記錄在其他所有記錄之前被訪問( 這裡所指的其他所有記錄指的是,同一個分類中的所有記錄。因為這裡我們有對 Mapper 的輸出做 Partitioner 分割槽 )。
TFCombiner & TFReducer
從上面的 Mapper 中可以看到 Mapper 輸出的 key 的格式為: : 。如此,只要去解析 key 中的 keyword 就可以了。而在 Mapper 的 cleanup() 方法中還寫入檔案的資訊。這樣一來,我們就可以使用這個 “!: allWordCount” 對每個檔案進行區分開來。區分的原理之前也說到過了,就是因為 “!” 的 ASCII 碼最小的原因。
public static class TFCombiner extends Reducer<Text, Text, Text, Text> {
private int allWordCount = 0;
@Override
protected void reduce(Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
if (values == null) {
return;
}
if(key.toString().startsWith("!")) {
allWordCount = Integer.parseInt(values.iterator().next().toString());
return;
}
int sumCount = 0;
for (Text value : values) {
sumCount += Integer.parseInt(value.toString());
}
double tf = 1.0 * sumCount / allWordCount;
context.write(key, new Text(String.valueOf(tf)));
}
}通過上面的 Combiner 的 reduce 操作之後,所有單詞的 TF 值都已經計算完成。再通過一次 Reducer 操作就 ok 了。Reducer 的程式碼如下:
public static class TFReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values,
Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
if (values == null) {
return;
}
for (Text value : values) {
context.write(key, value);
}
}
}TFPartitioner
在 Partitioner 分割槽這一塊,就簡單地以自定義的 Hash Partitioner 作為分割槽類。如果你有更加嚴格的要求,可以參考我之前的部落格《MapReduce 進階:Partitioner 元件》。
public static class TFPartitioner extends Partitioner<Text, Text> {
@Override
public int getPartition(Text key, Text value, int numPartitions) {
String fileName = key.toString().split(":")[1];
return Math.abs((fileName.hashCode() * 127) % numPartitions);
}
}IDFMapReduceCore
這裡我將與計算 IDF 相關的程式碼封裝在同一個 IDFMapReduceCore 類中,其中的 IDFMapper, IDFReducer 都是 IDFMapReduceCore 類的一個子類。
IDFMapper
因為 IDF 的計算是針對所有文件的,所以在 IDFMapper 中可以直接按照計算 WordCount 的邏輯來編寫就 ok 了。因為在計算 IDF 時,我們不需要關心某一個單詞的詞頻,所以這裡統一的使用 1 填充 mapper 的輸出 value.
public static class IDFMapper extends Mapper<Object, Text, Text, Text> {
private final Text one = new Text("1");
private Text label = new Text();
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString());
label.set(tokenizer.nextToken().split(":")[0]);
context.write(label, one);
}
}IDFReducer
在前面我們已經統計了某一個單詞在某一個文件(分類)出現的標誌,也就是單詞 W 在文件 D 中出現過了一次。這樣一來,我們就可以統計出單詞 W 在全部文件中出現過多少次了。而這一思想,正是計算 WordCount 邏輯。所以程式碼很好編寫。等等,我們還需要計算所有的文件數。是的,在計算 IDF 的公式中,我們需要知道一共有多少個文件。可是,在當前的情況下我們無法獲得這個值,因為這是在 Reducer 中。雖然在 Reducer 裡面無法計算文件總數,但是在 Reducer 外面卻可以。這個過程就是純粹的 Java 邏輯,很簡單,不多說了。
當我們知道了訓練文件總數,就可以通過 job 將資訊傳遞給 Reducer。只是這裡我們並不是呼叫 job.setNumReduceTasks(N),而是呼叫了 job.setProfileParams(msg) 方法。
public static class IDFReducer extends Reducer<Text, Text, Text, Text> {
private Text label = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
if (values == null) {
return;
}
int fileCount = 0;
for (Text value : values) {
fileCount += Integer.parseInt(value.toString());
}
label.set(String.join(":", key.toString(), "!"));
int totalFileCount = Integer.parseInt(context.getProfileParams()) - 1;
double idfValue = Math.log10(1.0 * totalFileCount / (fileCount + 1));
context.write(label, new Text(String.valueOf(idfValue)));
}
}IntegrateCore
這裡我將與計算 TF-IDF 相關的程式碼封裝在同一個 IntegrateCore 類中,其中的 IntegrateMapper, IntegrateReducer 都是 IntegrateCore 類的一個子類。在計算的最後一步中,沒有什麼需要說明的地方。只是,前面計算 TF、IDF 產生的中間輸出檔案的格式並不統一,所以這裡需要對不同格式的檔案內容進行不同的考慮。
IntegrateMapper
public static class IntegrateMapper extends Mapper<Object, Text, Text, Text> {
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
StringTokenizer tokenizer = new StringTokenizer(value.toString());
context.write(new Text(tokenizer.nextToken()), new Text(tokenizer.nextToken()));
}
}IntegrateReducer
public static class IntegrateReducer extends Reducer<Text, Text, Text, Text> {
private double keywordIDF = 0.0d;
private Text value = new Text();
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
if (values == null) {
return;
}
if (key.toString().split(":")[1].startsWith("!")) {
keywordIDF = Double.parseDouble(values.iterator().next().toString());
return;
}
value.set(String.valueOf(Double.parseDouble(values.iterator().next().toString()) * keywordIDF));
context.write(key, value);
}
}測試執行
資料來源
android
android
java
activity
maphadoop
map
reduce
ssh
mapreduceios
ios
iphone
jobsjava
java
code
eclipse
java
mappython
python
pycharm執行命令
執行此命令之前,請先將測試資料上傳到 HDFS 的 /input 目錄下。
$ hadoop jar temp/run.jar /input /output執行結果
activity:android 0.0994850021680094
android:android 0.0994850021680094
code:java 0.07958800173440753
eclipse:java 0.07958800173440753
ios:ios 0.13264666955734586
iphone:ios 0.13264666955734586
java:android 0.0554621874040891
java:java 0.08873949984654256
jobs:ios 0.13264666955734586
map:android 0.024227503252014105
map:hadoop 0.024227503252014105
map:java 0.019382002601611284
mapreduce:hadoop 0.0994850021680094
pycharm:python 0.1989700043360188
python:python 0.1989700043360188
reduce:hadoop 0.0994850021680094
ssh:hadoop 0.0994850021680094看到這個結果你可能會認為這個結果不一定可靠。如果你懷疑這些結果,你可以自己編寫一個單機版的 Java 程式進行驗證。當然,我已經驗證過了。
Job
此處是瀏覽器登入 Cluster Metrics 的資訊展示。顯示的是程式在執行完成之後的內容,看到有三個 Job 參與了 TF-IDF 的計算。
