Spark中cache和persist的作用以及儲存級別
在Spark中有時候我們很多地方都會用到同一個RDD, 按照常規的做法的話,那麼每個地方遇到Action操作的時候都會對同一個運算元計算多次,這樣會造成效率低下的問題
例如:
val rdd1 = sc.textFile("xxx")
rdd1.xxxxx.xxxx.collect
rdd1.xxx.xxcollect上面就是兩個程式碼都用到了rdd1這個RDD,如果程式執行的話,那麼sc.textFile(“xxx”)就要被執行兩次,我們可以把rdd1的結果進行cache到記憶體中,使用如下方法
val rdd1 = sc.textFile("xxx")
val rdd2 = rdd1.cache 按照如上的方法改造後,後面兩個業務程式碼執行的話rdd1就會在第一次執行的時候被持久化到記憶體中,後面的業務程式碼就可以複用,能有效提高效率
其中cache這個方法也是個Tranformation,當第一次遇到Action運算元的時才會進行持久化
其中cache內部呼叫了persist方法,persist方法又呼叫了persist(StorageLevel.MEMORY_ONLY)方法,所以執行cache運算元其實就是執行了persist運算元且持久化級別為MEMORY_ONLY
def cache 注意:
Spark有幾種持久化級別如下(參考自部落格):
1.MEMORY_ONLY
使用未序列化的Java物件格式,將資料儲存在記憶體中。如果記憶體不夠存放所有的資料,則資料可能就不會進行持久化。那麼下次對這個RDD執行運算元操作時,那些沒有被持久化的資料,需要從源頭處重新計算一遍。這是預設的持久化策略,使用cache()方法時,實際就是使用的這種持久化策略。
2.MEMORY_AND_DISK
使用未序列化的Java物件格式,優先嚐試將資料儲存在記憶體中。如果記憶體不夠存放所有的資料,會將資料寫入磁碟檔案中,下次對這個RDD執行運算元時,持久化在磁碟檔案中的資料會被讀取出來使用。
3.MEMORY_ONLY_SER
基本含義同MEMORY_ONLY。唯一的區別是,會將RDD中的資料進行序列化,RDD的每個partition會被序列化成一個位元組陣列。這種方式更加節省記憶體,從而可以避免持久化的資料佔用過多記憶體導致頻繁GC。
4.MEMORY_AND_DISK_SER
基本含義同MEMORY_AND_DISK。唯一的區別是,會將RDD中的資料進行序列化,RDD的每個partition會被序列化成一個位元組陣列。這種方式更加節省記憶體,從而可以避免持久化的資料佔用過多記憶體導致頻繁GC。
5.DISK_ONLY
使用未序列化的Java物件格式,將資料全部寫入磁碟檔案中。
6.MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等
對於上述任意一種持久化策略,如果加上字尾_2,代表的是將每個持久化的資料,都複製一份副本,並將副本儲存到其他節點上。這種基於副本的持久化機制主要用於進行容錯。假如某個節點掛掉,節點的記憶體或磁碟中的持久化資料丟失了,那麼後續對RDD計算時還可以使用該資料在其他節點上的副本。如果沒有副本的話,就只能將這些資料從源頭處重新計算一遍了。
- 建議:(參考自部落格)
預設情況下,效能最高的當然是MEMORY_ONLY,但前提是你的記憶體必須足夠足夠大,可以綽綽有餘地存放下整個RDD的所有資料。因為不進行序列化與反序列化操作,就避免了這部分的效能開銷;對這個RDD的後續運算元操作,都是基於純記憶體中的資料的操作,不需要從磁碟檔案中讀取資料,效能也很高;而且不需要複製一份資料副本,並遠端傳送到其他節點上。但是這裡必須要注意的是,在實際的生產環境中,恐怕能夠直接用這種策略的場景還是有限的,如果RDD中資料比較多時(比如幾十億),直接用這種持久化級別,會導致JVM的OOM記憶體溢位異常。
如果使用MEMORY_ONLY級別時發生了記憶體溢位,那麼建議嘗試使用MEMORY_ONLY_SER級別。該級別會將RDD資料序列化後再儲存在記憶體中,此時每個partition僅僅是一個位元組陣列而已,大大減少了物件數量,並降低了記憶體佔用。這種級別比MEMORY_ONLY多出來的效能開銷,主要就是序列化與反序列化的開銷。但是後續運算元可以基於純記憶體進行操作,因此效能總體還是比較高的。此外,可能發生的問題同上,如果RDD中的資料量過多的話,還是可能會導致OOM記憶體溢位的異常。
如果純記憶體的級別都無法使用,那麼建議使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因為既然到了這一步,就說明RDD的資料量很大,記憶體無法完全放下。序列化後的資料比較少,可以節省記憶體和磁碟的空間開銷。同時該策略會優先儘量嘗試將資料快取在記憶體中,記憶體快取不下才會寫入磁碟。
通常不建議使用DISK_ONLY和字尾為_2的級別:因為完全基於磁碟檔案進行資料的讀寫,會導致效能急劇降低,有時還不如重新計算一次所有RDD。字尾為_2的級別,必須將所有資料都複製一份副本,併發送到其他節點上,資料複製以及網路傳輸會導致較大的效能開銷,除非是要求作業的高可用性,否則不建議使用。
- 可以查詢RDD的持久化策略:
scala> rdd1.getStorageLevel
res17: org.apache.spark.storage.StorageLevel = StorageLevel(false, false, false, false, 1)
scala> rdd1.getStorageLevel.description
res18: String = Serialized 1x Replicated
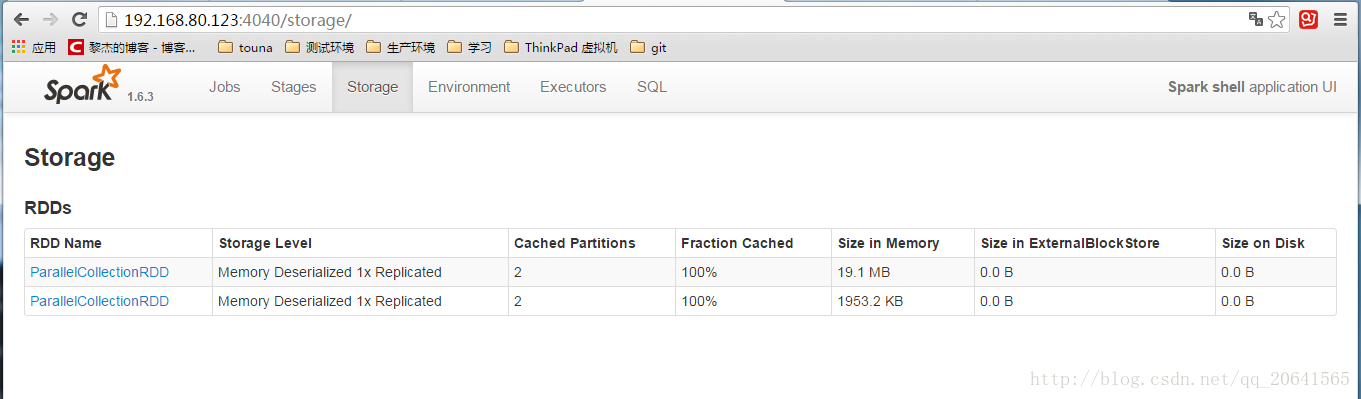
- UI介面上面檢視持久化的資料:
當cache後檢視持久化的資料:
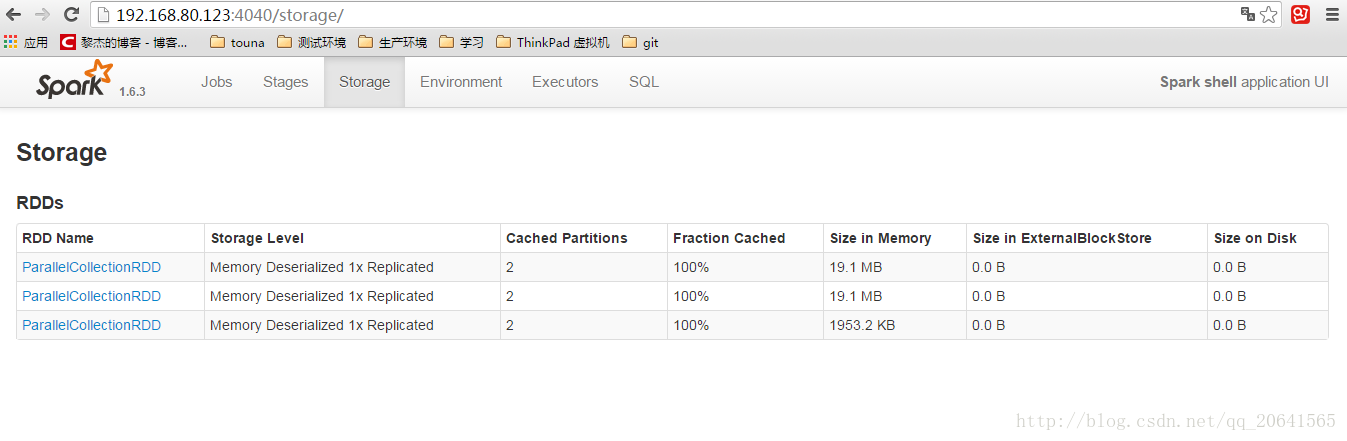
當執行rdd1.unpersist(true)後,持久化的資料就會被刪除: