
RocketMQ 原始碼分析 訊息儲存(預備知識二)(轉載+整理)
前言
在RMQ中為了提高commitlog檔案的讀寫效率,而採用了一個叫做記憶體對映的技術。按照我的理解,記憶體對映在處理大檔案上有非常大的效能提升,所以這篇來記錄一下我對記憶體對映的理解。
使用者態和核心態
我們都知道作業系統分為使用者態和核心態,核心態表示當前為核心程式執行時的狀態,使用者態是使用者程式程式碼執行的狀態。使用者態是不能直接和物理裝置打交道的,如果想把硬碟的一塊區域讀到使用者態,則需要兩次拷貝(硬碟->核心->使用者)。看使用者態和核心態在一次IO使用的情況:
讀操作:作業系統檢查核心的緩衝區有沒有需要的資料,如果已經快取了,那麼就直接從快取中返回;否則從磁碟中讀取,然後快取在作業系統的快取中,因為只有核心程式才可以和IO裝置進行讀寫,所以這個過程就是核心態,核心程式將緩衝區複製到使用者空間中,核心態就結束,使用者態繼續執行。
寫操作:將資料從使用者空間複製到核心空間的快取中。這時對使用者程式來說寫操作就已經完成,核心空間再講資料刷到磁碟中。至於什麼時候再寫到磁碟中由作業系統決定,除非顯示地呼叫了sync同步命令。
那麼為什麼要分成使用者態和核心態呢?
將它們分開主要是為了安全性考慮。即使使用者的程式崩潰了,核心中的核心程式也不受影響。
虛擬記憶體
在早期的計算機中,是沒有虛擬記憶體的概念的。我們要執行一個程式,會把程式全部裝入記憶體,然後執行。當執行多個程式時,經常會出現程序地址空間不隔離,沒有許可權保護、記憶體使用效率低等問題。所以引入虛擬記憶體來避免上述的問題。
虛擬記憶體不只是“用磁碟空間來擴充套件實體記憶體”的意思——這只是擴充記憶體級別以使其包含硬碟驅動器而已。把記憶體擴充套件到磁碟只是使用虛擬記憶體技術的一個結果,
Linux虛擬記憶體的大小為2^32(在32位機器上)剛好4G,核心將這4G位元組的空間分為兩部分。最高的1G位元組(從虛地址0xC0000000到0xFFFFFFFF)供核心使用,稱為“核心空間”。而較低的3G位元組(從虛地址0x00000000 到0xBFFFFFFF),供各個程序使用,稱為“使用者空間”。因為每個程序可以通過系統呼叫進入核心,因此,Linux核心空間由系統內的所有程序共享。
使用者空間不是程序共享的,而是程序隔離的。每個程序最大都可以有3GB的使用者空間。一個程序對其中一個地址的訪問,與其它程序對於同一地址的訪問絕不衝突。比如,一個程序從其使用者空間的地址0x1234ABCD處可以讀出整數8,而另外一個程序從其使用者空間的地址0x1234ABCD處可以讀出整數20,這取決於程序自身的邏輯。
從上面我們知道,一個程式編譯連線後形成的地址空間是一個虛擬地址空間,但是程式最終還是要執行在實體記憶體中。因此,應用程式所給出的任何虛地址最終必須被轉化為實體地址,所以,虛擬地址空間必須被對映到實體記憶體空間中,這個對映關係需要通過硬體體系結構所規定的資料結構來建立。這就是我們所說的段描述符表和頁表,Linux主要通過頁表來進行對映。
於是,我們得出一個結論,如果給出的頁表不同,那麼CPU將某一虛擬地址空間中的地址轉化成的實體地址就會不同。所以我們為每一個程序都建立其頁表,將每個程序的虛擬地址空間根據自己的需要對映到實體地址空間上。既然某一時刻在某一CPU上只能有一個程序在執行,那麼當程序發生切換的時候,將頁表也更換為相應程序的頁表,這就可以實現每個程序都有自己的虛擬地址空間而互不影響。所以,在任意時刻,對於一個CPU來說,只需要有當前程序的頁表,就可以實現其虛擬地址到實體地址的轉化。
記憶體對映
首先,“對映”這個詞,就和數學課上說的“一一對映”是一個意思,就是建立一種一一對應關係,在這裡主要是隻 硬碟上檔案的位置,與程序 **邏輯地址空間**中 一塊大小相同的區域之間的一一對應,如下圖中過程1所示。這種對應關係純屬是邏輯上的概念,物理上是不存在的,原因是程序的邏輯地址空間本身就是不存在 的。在記憶體對映的過程中,並沒有實際的資料拷貝,檔案沒有被載入記憶體,只是邏輯上被放入了記憶體,具體到程式碼,就是建立並初始化了相關的資料結構 (struct address_space),這個過程有系統呼叫mmap()實現,所以建立記憶體對映的效率很高。
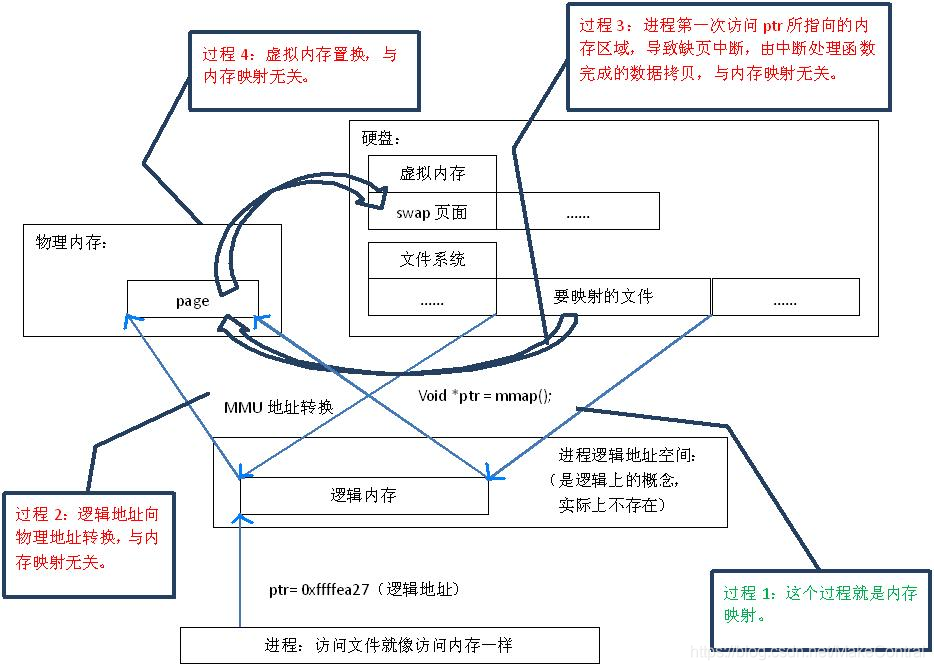
既然建立記憶體對映沒有進行實際的資料拷貝,那麼程序又怎麼能最終直接通過記憶體操作訪問到硬碟上的檔案呢?
mmap()會 返回一個指標ptr,它指向程序邏輯地址空間中的一個地址,這樣以後,程序無需再呼叫read或write對檔案進行讀寫,而只需要通過ptr就能夠操作 檔案。但是ptr所指向的是一個邏輯地址,要操作其中的資料,必須通過MMU將邏輯地址轉換成實體地址,如圖1中過程2所示。這個過程與記憶體對映無關。
前面講過,建立記憶體對映並沒有實際拷貝資料,這時,MMU在地址對映表中是無法找到與ptr相對應的實體地址的,也就是MMU失敗,將產生一個缺頁中斷,缺 頁中斷的中斷響應函式會在swap中尋找相對應的頁面,如果找不到(也就是該檔案從來沒有被讀入記憶體的情況),則會通過mmap()建立的對映關係,從硬 盤上將檔案讀取到實體記憶體中,如圖1中過程3所示。這個過程與記憶體對映無關。
用檔案對映的方法對檔案進行操作,效率要比read和write系統呼叫高,這是為什麼呢?
從程式碼層面上看,從硬碟上將檔案讀入記憶體,都要經過檔案系統進行資料拷貝,並且資料拷貝操作是由檔案系統和硬體驅動實現的,理論上來說,拷貝資料的效率是一 樣的。
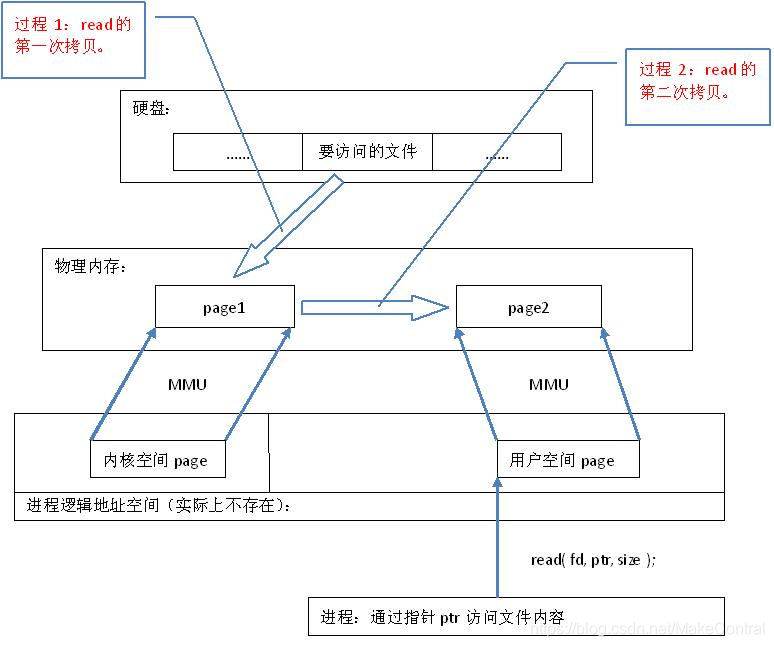
read()是系統呼叫,其中進行了資料 拷貝,它首先將檔案內容從硬碟拷貝到核心空間的一個緩衝區,如下圖中過程1,然後再將這些資料拷貝到使用者空間,如下圖中過程2,在這個過程中,實際上完成 了兩次資料拷貝 ;而mmap()也是系統呼叫,如前所述,mmap()中沒有進行資料拷貝,真正的資料拷貝是在缺頁中斷處理時進行的,由於mmap()將檔案直接對映到使用者空間,所以中斷處理函式根據這個對映關係,直接將檔案從硬碟拷貝到使用者空間,只進行了 一次資料拷貝 。
因此,記憶體對映的效率要比read/write效率高。
參考文章
https://www.cnblogs.com/volcao/p/8818199.html