
輪子:一個簡單的node爬蟲踩坑之路
阿新 • • 發佈:2018-12-30
一個簡單的node爬蟲踩坑之路
準備工作
最近在看爬蟲相關的文章,偶然想起來嘗試一下用node來實現一個簡單的爬蟲。但是爬別的多沒意思,當然是爬美女圖片啊。。。
這大概 node 裡面造的最多的輪子了。
於是,我選取了下面的地址:美女圖片戳我,簡單分析後,我的目標是通過爬取首頁的輪播圖,然後爬取輪播圖的直鏈後面的詳情大圖,並按照圖片名稱存到指定的資料夾中。
大致流程是下面這個樣子的:
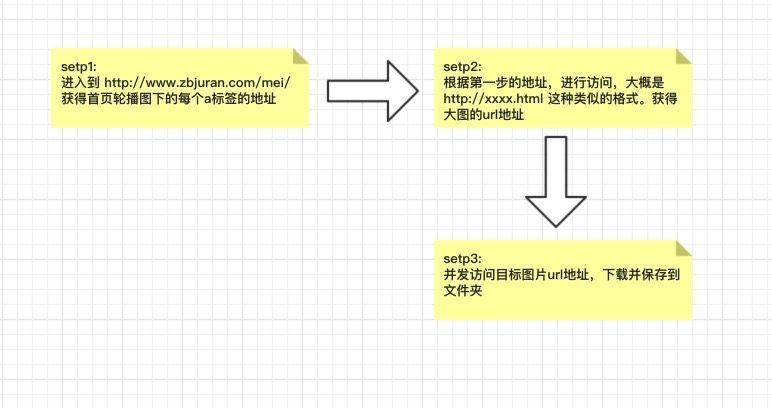
看起來挺簡單的,選用的技術方案是:
superagent: 請求庫mkdirp: 建立資料夾async: 控制併發請求cheerio: Dom操作庫fs: 內建核心檔案讀寫庫
最終的效果
原始碼:
// 關鍵在於理清非同步流程
'use strict'
let fs = require("fs");
let cheerio = require('cheerio');
let asyncQuene = require("async").queue;
let request = require('superagent');
require('superagent-charset')(request);
const config = {
urlPre: 'http://www.zbjuran.com',
indexUrl: 'http://www.zbjuran.com/mei/' 劃重點
1.當爬取網頁編碼為 gb2312的網頁的時候,爬到的內容中文顯示是亂碼
這個問題的原因其實是挺清晰的,就是網頁編碼與本地編碼不一致或不支援引起的。以為只是個小問題,但是在找解決辦法的時候卻糾結了我很久,查詢了網上相關資料,有說使用 iconv 解碼decode一下就可以,然並卵,有說使用encoding的,其實也沒用。其實最後查閱資料得出的原因是,superagent只支援utf-8的編碼,如果需要支援其他的需要引用一個官方的庫:superagent-charset,使用方法如下:
const request = require('superagent');
require('superagent-charset')(request);
//請求
request.get('xxx').set('gbk').end(xxxxx)如此,即可正常返回中文
2. 非同步操作用 async 來控制
對於下載圖片,訪問 url 這樣存在非同步的操作,如果操作對後面程式的執行有影響,最好使用 async 庫來控制非同步流程,類似的還有 eventproxy。
下面是一個使用來async來控制請求佇列的官網示例,
// create a queue object with concurrency 2
var q = async.queue(function(task, callback) {
console.log('hello ' + task.name);
callback();
}, 2);
// assign a callback
q.drain = function() {
console.log('all items have been processed');
};
// add some items to the queue
q.push({name: 'foo'}, function(err) {
console.log('finished processing foo');
});
q.push({name: 'bar'}, function (err) {
console.log('finished processing bar');
});
// add some items to the queue (batch-wise)
q.push([{name: 'baz'},{name: 'bay'},{name: 'bax'}], function(err) {
console.log('finished processing item');
});
// add some items to the front of the queue
q.unshift({name: 'bar'}, function (err) {
console.log('finished processing bar');
});其實官網有好多栗子,近期還會抽時間好好研究一下類似非同步流程庫的具體實現。
3. 404錯誤。獲取不到資源
這個其實還好,主要是網站為了防爬的措施,可以嘗試一下方法來試試看:
- 設定
user-agent - 降低請求的併發量
- 更換IP
總結
雖然只是一個簡單的爬蟲,但是發現自己對於 promise 這種的非同步流程還不是很熟悉,這點需要重點掌握。
另外,從爬蟲的角度來說,node現在的庫已經很完善了,還有 phantomjs,node-crawl 這種操作更6的庫存在,掌握一門工具很容易,更重要的是要學會製作工具。
最後,練習爬蟲只是出於對技術的熱愛,莫要亂爬。