
網際網路級監控系統必備-時序資料庫之Influxdb技術
時間序列資料庫,簡稱時序資料庫,Time Series Database,一個全新的領域,最大的特點就是每個條資料都帶有Time列。
時序資料庫到底能用到什麼業務場景,答案是:監控系統。
Baidu一下,網際網路監控系統,大家會發現小米、餓了嗎等網際網路巨頭都在用時序資料庫實現企業級的網際網路監控系統。
很多人會說,用Zabbix不就搞定了,其實不是這樣的,簡單的主機資源監控、網路監控、小規模的部署環境,Zabbix能搞定。
如果在IDC 上千臺伺服器環境下,分散式應用架構、各種中介軟體,這種情況下我們要監控上千臺服務的主機資源、網路、按不同緯度監控服務的效能、TPS,監控各類中介軟體,程式監控埋點。Zabbix就無法
滿足需要了。此時,我們要獨立搭建自己的監控體系了。說到這,每一個監控圖表的背後,都有什麼?
1. 時間軸
2. 資料值(不同指標緯度)
例如,一段時間內CPU使用率
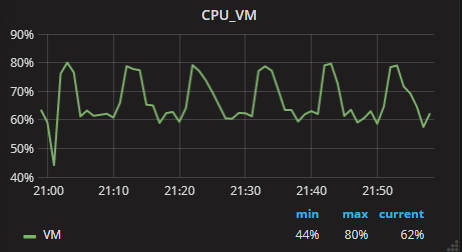
這時,各種Google、Baidu之後,你肯定會搜尋到Influxdb、OpenTSDB等時序資料庫。
Influxdb我們研究了很長的時間,準備用2篇文章,推薦給大家,本文中,我們分享一下Influxdb的關鍵特性、查詢語法和使用場景。
一、Influxdb關鍵特性
1. 支援類似SQL的查詢語法
2.提供了Http Api直接訪問
3.儲存超過10億級別的時間序列資料
4.靈活的資料保留策略,可以定義到Database級別(只保留最熱的資料)
5.內建管理介面和CMD
6.飛一般速度的聚合查詢
7.按不同時間段進行聚合查詢
8.內建持續查詢功能,定時計算指定時間段的資料,插入到指定表中,可以理解為定時歸集資料
9. 水平擴充套件,支援叢集模式
二、Influxdb 版本和.Net支援
1. 根據我們的使用經驗,V0.10版本是非常穩定的,V0.9.6我們用過,有記憶體洩漏問題
2. GitHub上有非常多的.Net Libraby,方便我們寫入和讀取資料

三、資料寫入Write Data(Points)
Http API:
curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load,host=server01,region=us-west value=0.64 1434055562000000000‘
db:mydb, 要寫入的資料庫
measurement:cpu_load,表
tag keys:host region tag value:server01 us-west
tag標籤可以理解為維度,可選引數,用於標識不同的資料來源,基於tag使查詢更加簡單和高效
Tags are indexed so queries on tag keys or tag values are more performant than queries on fields.
key field:value value field:0.64
Timestamp:1434055562000000000 可選引數、UTC
支援批量寫入
支援同一個Timestamp寫入不同的資料
Influxdb 支援儲存結構靈活變化,可以在任意增加measure、tags、fields,但是每個tag、field的資料型別必須固定。
四、查詢Query
Http API:
curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=mydb" --data-urlencode "q=SELECT value FROM cpu_load_short WHERE region='us-west‘
返回JSON格式資料
支援同時多個Query SQL
查詢最大返回10000個點的資料,如果超過閾值,可以設定chunk_size
Measurement、Tag、Field、資料等大小寫敏感,SQL關鍵字不區分大小寫
支援算術計算:
SELECT (water_level * 2) + 4 from h2o_feet
支援對Tags進行過濾查詢,條件必須使用單引號
SELECT water_level FROM h2o_feet WHERE location = 'santa_monica'
Tag value 為空、不為空過濾
SELECT * FROM h2o_feet WHERE location !~ /.*/
SELECT * FROM h2o_feet WHERE location =~ /.*/
時間範圍過濾
SELECT * FROM h2o_feet WHERE time > now() - 7d
Field value過濾
SELECT * FROM h2o_feet WHERE location = 'coyote_creek' AND water_level > 8
聚合函式、選擇函式、轉換函式
五、持續查詢(Continuous Queries)
持續查詢是Influxdb自動、週期的執行的查詢,結果自動儲存
設計持續查詢的目的是為了規則取樣資料,比如按天、按月取樣資料
CREATE CONTINUOUS QUERY <cq_name> ON <database_name> [RESAMPLE [EVERY <interval>] [FOR <interval>]] BEGIN SELECT <function>(<stuff>)[,<function>(<stuff>)] INTO <different_measurement> FROM <current_measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<stuff>] END

六、 監控應用場景
通過上面幾個部分的介紹,Influxdb的基本語法就可以掌握了。有什麼作用:
1. 實時採集監控資料,按時間寫入Influxdb
2. 按不同緯度聚合查詢監控資料,用於監控展現
3. 持續查詢,定時歸集指定時間的資料,用於更大時間範圍監控資料的展現
總結一下,場景結合實踐,通過實際監控系統的應用,和大家分享了Influxdb的使用和技能。我們自己的監控系統就是通過這個套路一點點搭建起來的。
目前,我們的監控平臺,2500個監控項,500臺伺服器實時監控,每日處理上T資料,幾百個監控圖表,Influxdb滿足了我們日常超大規模監控的需要。
同時,Influxdb在大資料展現領域,也有不俗的表現,Druid的整合也很棒的。