
SQL Server調優系列基礎篇(聯合運算子總結)
前言
上兩篇文章我們介紹了檢視查詢計劃的方式,以及一些常用的連線運算子的優化技巧,本篇我們總結聯合運算子的使用方式和優化技巧。
廢話少說,直接進入本篇的主題。
技術準備
基於SQL Server2008R2版本,利用微軟的一個更簡潔的案例庫(Northwind)進行解析。
一、聯合運算子
所謂的聯合運算子,其實應用最多的就兩種:UNION ALL和UNION。
這兩個運算子用法很簡單,前者是將兩個資料集結果合併,後者則是合併後進行去重操作,如果有過寫T-SQL語句的碼農都不會陌生。
我們來分析下這兩個運算子在執行計劃中的顯示,舉個例子
SELECT FirstName+N''+LastName,City,Country FROM Employees UNION ALL SELECT ContactName,City,Country FROM Customers
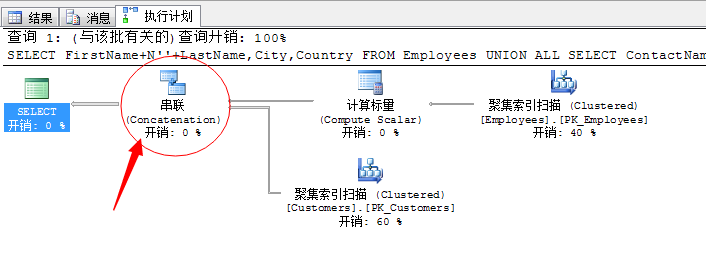
就是上面這個圖示了,這就是UNION ALL聯合運算子的圖示。

這個聯合運算子很簡單的操作,將兩個資料集合掃描完通過聯合將結果彙總。
我們來看一下UNION 這個運算子,例子如下
select City,Country from Employees UNION SELECT City,Country FROM Customers
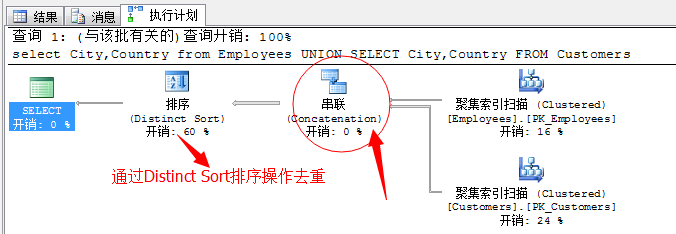
我們可以看到,UNION 運算子是在串聯運算子之後發生了一個Distinct Sort排序操作,經過這個操作會將結果集合中的重複值去掉。
我們一直強調:大資料表的排序是一個非常耗資源的動作!
所以,到這裡我們已經找到了可優化的選項,去掉排序,或者更改排序方式。
替換掉Distinct Sort排序操作的方式就是哈序聚合。Distinct Sort排序操作需要的記憶體和去除重複之前資料集合的資料量成正比,而雜湊聚合需要的記憶體則是和去除重複之後的結果整合正比!
所以如果資料行中重複值很多,那麼相比而言通過雜湊聚合所消耗的記憶體會少。
我們來舉個例子
select ShipCountry from Orders UNION SELECT ShipCountry FROM Orders
這個例子其實沒啥用處,這裡就是為了演示,我們來看一下結果
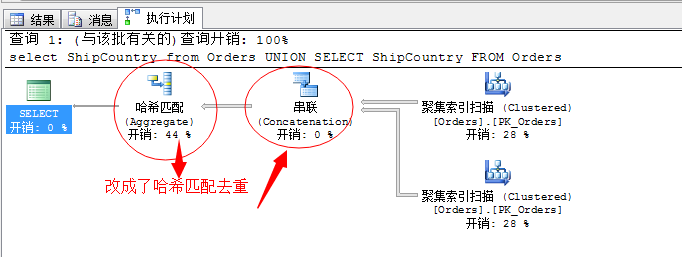
我們知道,這張表裡這個ShipCountry是存在大面積重複值的,所以採用了雜湊匹配來去重操作是最優的方式。
其實,相比雜湊匹配連線還有一種更輕量級的去重的連線方式:合併連線
上一篇我已經分析了這個連線方法,用於兩個資料集的連線方式,這裡其實類似,應用前都必須先將原結果集合排序!
我們知道優化的方式可以採用建立索引來提高排序速度。
我們來重現這種去重方式,我們新建一個表,然後建立索引,程式碼如下
--新建表 SELECT EmployeeID,FirstName+N' '+LastName AS ContactName,City,Country INTO NewEmployees FROM Employees GO --新增索引 ALTER TABLE NewEmployees ADD CONSTRAINT PK_NewEmployees PRIMARY KEY(EmployeeID) CREATE INDEX ContactName ON NewEmployees(ContactName) CREATE INDEX ContactName ON CUSTOMERS(ContactName) GO --新建查詢,這裡一定要加上一個顯示的Order by才能出現合併連線去重 SELECT ContactName FROM NewEmployees UNION ALL SELECT ContactName FROM Customers ORDER BY ContactName
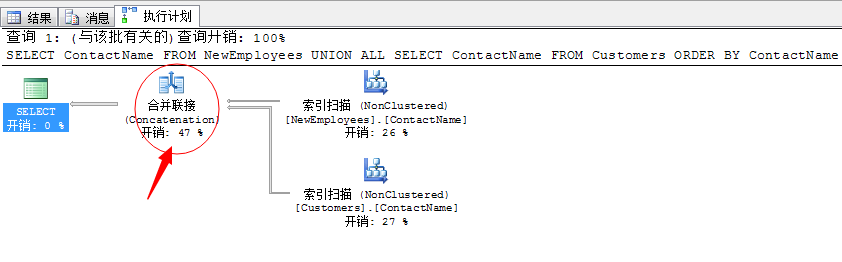
我們採用索引掃描的方式可以避免顯式的排序操作。
我們將UNION ALL改成UNION,該操作將會對兩個資料集進行去重操作。
--新建查詢,這裡一定要加上一個顯示的Order by才能出現合併連線去重
SELECT ContactName FROM NewEmployees
UNION
SELECT ContactName FROM Customers
ORDER BY ContactName

這裡我們知道UNION操作會對結果進行去重操作,上面應用了流聚合操作,流聚合一般應用於分組操作中,當然這裡用它進行了分組去重。
在我們實際的應用環境中,最常用的方式還是合併連線,但是有一種情況最適合雜湊連線,那就是一個小表和大表進行聯合操作,尤其適合哪種大表中存在大量重複值的情況下。
雜湊演算法真是個好東西!
參考文獻
- 參照書籍《SQL.Server.2005.技術內幕》系列
結語
此篇文章先到此吧,簡短一點,便於理解掌握,本篇主要介紹了查詢計劃中的聯合操作運算子,下一篇我們分析SQL Server中的並行運算,在多核超執行緒雲集的今天,來看SQL Server如何利用並行運算來最大化的利用現有硬體資源提升效能,有興趣可提前關注,關於SQL Server效能調優的內容涉及面很廣,後續文章中依次展開分析。
SQL Server這個軟體一旦深入進去,你會發現它真的非常深,基本可以用深不見底來描述,如果想研究裡面的效能調優這塊,可以關注本系列內容,我們一起研究!
而且到現在還有很多人對SQL Server這套產品有誤解,或者說觀點有待糾正,以前就遇到過客戶直接當我面大談神馬SQL Server匯入資料一多就宕機了....
神馬SQL Server只能做小資料量的應用...神馬不如Oracle云云....!!!
還有一部分童鞋單純的認為SQL Server是小兒科,沒啥技術含量...簡單的很....
關於這些觀點,我不想吐槽啥,我只想讓那些真正瞭解SQL Server的朋友一起來為SQL Server證明點什麼。
文章最後給出上一篇的連線
如果您看了本篇部落格,覺得對您有所收穫,請不要吝嗇您的“推薦”。